
论文阅读_High-Resolution Image Synthesis with Latent Diffusion Models
基于潜在扩散模型的高分辨率图像合成,Stable Diffusion的基础论文
前置知识:

-
Diffusion Models(DDPM):扩散模型包括两个过程:前向过程(forward process)和反向过程(reverse process)
-
其中前向过程又称为扩散过程(diffusion process):对数据逐渐增加高斯噪音,直至数据变成随机噪音。
-
Diffusion Model(DDPM)训练过程就是训练UNet预测每一步的noise,从而逐步还原原始图像。原始图像空间的Diffusion
-
-
Latent Diffusion Models(LDMs):diffusion直接在原图进行图片的去噪处理,而 latend diffusion 是图像经过VAE编码器压缩的图像,进行diffusion处理,然后再通过解码器,对压缩后的latent 编码还原为图像。
-
Stable diffusion:一个基于Latent Diffusion Models(LDMs)的text2image模型的实现。
-
latent embedding:相对于像素空间,latent空间是通过VAE将图像编码为一个低微表示
-
变分自编码器(VAE):生成latent空间表示的模型
背景:
-
高分辨率图像合成Diffusion Models属于基于似然性的模型,倾向于用过多的容量来建模细节。训练这样的模型需要大量的计算资源,评估已经训练的模型在时间和内存上也很昂贵
-
潜在空间(Latent Space):首先找到一个等价但计算量小的空间,在里面训练扩散模型。
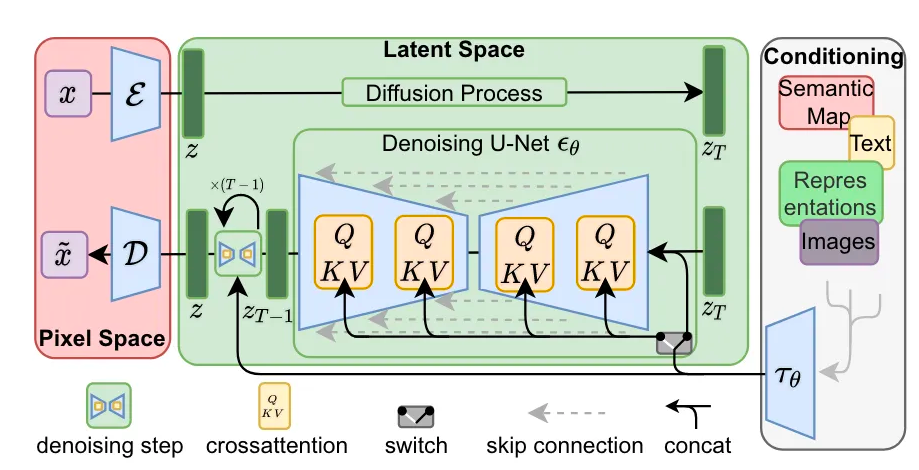
Diffusion Process:加噪声
Denoising UNet:去噪自编码器,去除噪声
D:解码器,将低维表示z还原成原始图像空间。
e:将x压缩成低维latent表示
步骤:
-
首先训练一个自编码器(VAE编码器),提供一个较低维度的表示空间Latent,在感知上等同于数据空间。
-
在潜在空间中训练DM。
-
对于文本到图像任务,设计了一种架构,将Transformer连接到DM的UNet主干,交叉注意力(cross-attention)的通用条件调节机制,并启用任意类型的、基于token的调节机制。
LDMs相比DDPM最大的两点改进如下:
-
加入Autoencoder(上图中左侧红色部分),使得扩散过程在latent space下,提高图像生成的效率;
-
加入条件机制,能够使用其他模态的数据控制图像的生成(上图中右侧灰色部分),其中条件生成控制通过Attention(上图中间部分QKV)机制实现。
优点
-
提高可实现质量的上限,降低采样率。
-
由于扩散模型为空间数据提供了极好的归纳偏差,不需要对潜在空间中的相关生成模型进行大量的空间下采样,但仍然可以通过适当的自编码模型大大降低数据的维数。
-
只需要训练通用自编码阶段一次。因此可以重用于多个DM训练。能够有效地探索用于各种图像到图像和文本到图像任务的大量扩散模型。
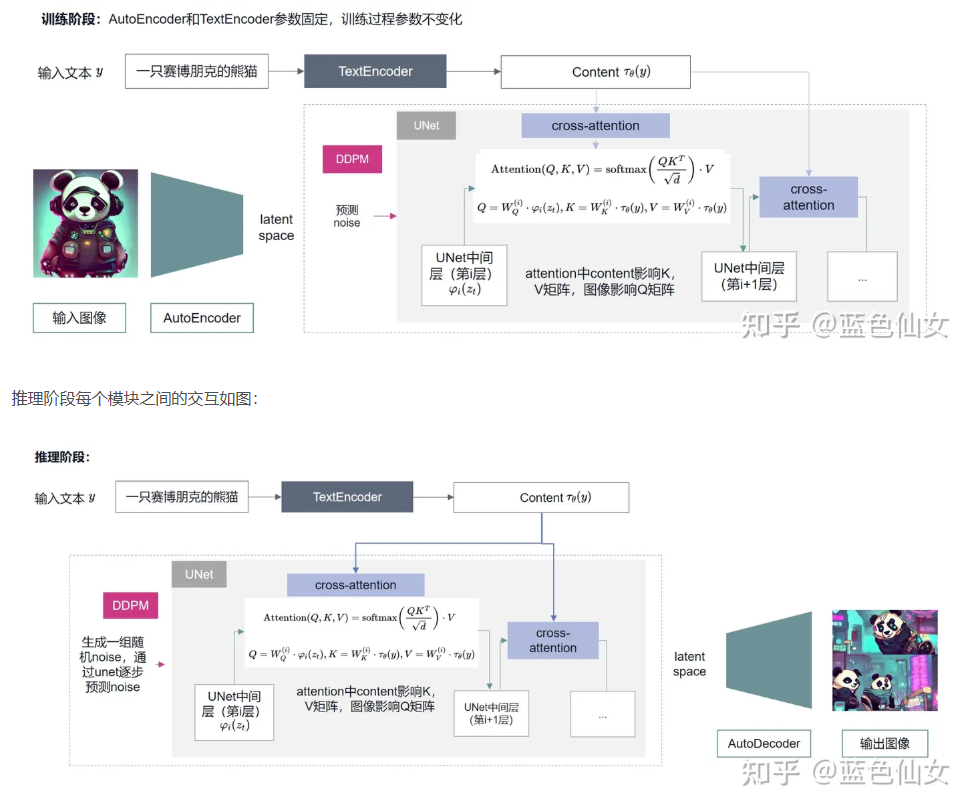
示例:
 微信
微信- 支付宝

