
论文阅读_Utonia
Utonia
Utonia: Toward One Encoder for All Point Clouds
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Utonia: Toward One Encoder for All Point Clouds |
| 作者 | Yujia Zhang, Xiaoyang Wu, Yunhan Yang, Xianzhe Fan, Han Li, Yuechen Zhang, Zehao Huang, Naiyan Wang, Hengshuang Zhao |
| 作者单位 | 1. 香港大学 2. 香港中文大学 3. 小米 |
| 时间 | 2025 |
| 发表会议/期刊 | arXiv preprint / 待发表 (推测) |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 跨域点云(室内、室外LiDAR、遥感、物体CAD、视频提升点云) |
| 输出 | 每个点的稠密特征表示(可用于下游任务) |
| 所属领域 | 三维自监督学习、跨域统一表示学习 |
1. 摘要精简
Utonia 是首个面向全场景跨域点云的统一自监督编码器,可同时处理遥感、室外 LiDAR、室内 RGB-D、物体 CAD、视频重建点云等异构数据。
针对跨域数据在坐标尺度、密度、采样模式、模态缺失上的差异,通过因果模态遮蔽、感知粒度重缩放、RoPE 增强位置编码三类域无关设计,在 25 万跨域点云与 100 万 CAD 数据上训练得到统一表征空间。
2. 引言出发点
现有点云自监督模型(Sonata、Concerto)均为单域训练,跨域泛化能力极差,无法适配不同传感器、尺度、密度的点云数据。
点云跨域训练存在三大核心障碍:输入模态不统一(颜色 / 法向缺失)、稀疏性与密度差异巨大、感知粒度与空间坐标系不兼容。
直接混合多域数据训练会使模型陷入域特定先验,表征按域聚类,无法学习通用几何与语义信息。
稀疏点云是物理世界的几何显式表达,亟需统一编码器支撑自动驾驶、AR/VR、机器人等跨域应用。
3. 创新点与相关工作对比
创新点:
- 跨域统一预训练:首次在单个自监督编码器中联合训练室内、室外 LiDAR、物体 CAD、遥感、视频提升点云等多种点云类型,实现跨域共享表示。
- 识别跨域不匹配三大问题:① 输入通道不统一(颜色、法向等可选);② 稀疏性和密度不一致;③ 感知粒度变化(由域和下游任务引起)。
- 提出三个简单域无关设计:
- 因果模态遮蔽(Causal Modality Blinding):随机丢弃颜色/法向通道,使模型对缺失模态鲁棒。
- 感知粒度重缩放(Perceptual Granularity Rescale):根据固定的观察粒度统一坐标尺度,使局部算子可比较。
- 基于 RoPE 的增强位置编码:在粒度对齐的坐标上应用旋转位置编码,并添加坐标抖动和缩放,增强跨域几何可迁移性,同时消除对重力方向的过度依赖。
- 域先验擦除与泛化增强采用差异化强增强(物体域全 SO (3) 旋转、场景域弱旋转),消除重力先验与域特定偏差。
- 涌现行为:跨域联合预训练产生新能力,如物体级与场景级数据的相互促进、保留场景级重力对齐但对物体级保持旋转不变性等。
- 扩展到下游应用:在 VLM 中集成 Utonia 特征提升空间推理,在 VLA 中提升机器人操作性能。
与相关工作对比及指出的问题:
| 对比方法 | 问题 |
|---|---|
| 现有单域 SSL(PointMAE、MSC、Sonata、Concerto) | 局限于单一域,跨域迁移差,即使都是 3D 点云(如图 2 中 Concerto 无法对齐玩具车与真实车) |
| 点云统一模型尝试(Zhang 等人、Zha 等人的 MoDE) | 依赖复杂模块或仅验证部分域组合,未真正实现跨域联合预训练 |
| PTv3、RoPE 在 1D/2D 的应用 | 未探索 RoPE 结合粒度对齐在 3D 跨域预训练中的作用 |
4. 网络架构构成
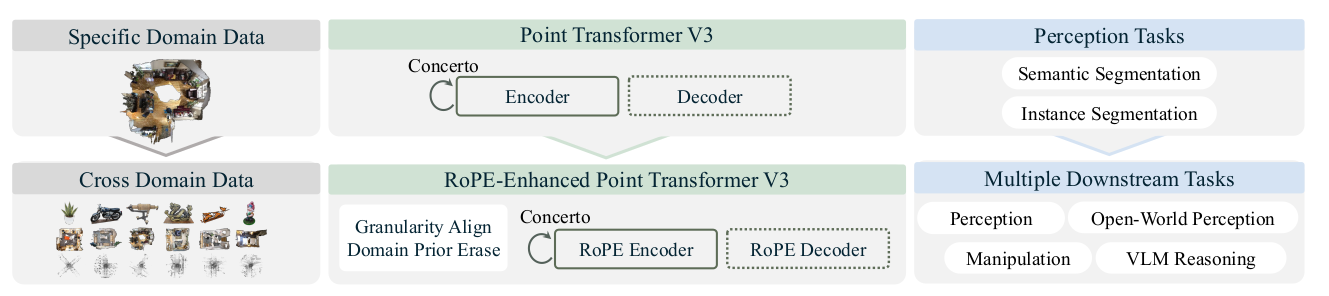
Utonia 基于 RoPE 增强的 Point Transformer V3 (PTv3) [42] 编码器,遵循 Sonata [44] 和 Concerto [55] 的教师-学生自蒸馏预训练框架,但引入三个关键改进(见创新点)。整体架构如图 4 所示:
- 编码器:PTv3,采用 RoPE 增强的位置编码(在粒度对齐的坐标上),并添加因果模态遮蔽。
- 学生-教师自蒸馏:学生处理增强视图(局部视图、掩蔽视图),教师处理全局视图,通过聚类分配损失(Sinkhorn-Knopp 中心化)进行蒸馏。
- 跨模态联合嵌入预测(可选):沿用 Concerto,当图像可用时,点云特征预测冻结 DINOv2 的图像块特征。
5. 数据预处理与点的无序性/稀疏性处理
- 数据来源:混合数据集(见表 12),包括 ScanNet [7]、ScanNet++ [49]、S3DIS [2]、ARKitScenes [3]、HM3D [26]、Structured3D [60]、RE10k [62]、NuScenes [5]、Waymo [31]、SemanticKitti [4]、HK Remote [17]、PartNet [19]、ScanObjectNN [38]、GraspNet [11]、Cap3D [20] 等,总计数十万场景点云 + 1M CAD 资产。
- 预处理:
- 统一模态接口:坐标、颜色(若有)、法向(若有)拼接,缺失的通道填零。
- 因果模态遮蔽:以一定概率随机丢弃整个颜色或法向通道,甚至逐点丢弃,训练模型对缺失模态鲁棒。
- 感知粒度重缩放:根据一个固定的“观察粒度”(例如,场景级和物体级分别设定标准网格大小),将点云坐标统一缩放,使局部邻域有可比的空间尺度。具体地,设定一个基准网格大小(如 0.02m),然后将不同域的点云通过缩放因子调整到该粒度,同时保持坐标绝对值有意义。
- 点的无序性:PTv3 本身具有置换不变性(通过排序或池化),自蒸馏中的点匹配基于原始坐标空间中的最近邻,不受点序影响。
- 稀疏性:PTv3 的稀疏注意力机制处理大规模稀疏点云,粒度重缩放后网格划分统一。
6. 特征提取
- 编码器:PTv3 编码器,输入为的点云(坐标+可选通道),输出多尺度点特征。在自蒸馏中,特征在不同尺度上用于不同分支。
- RoPE 增强:在每一层注意力中,对查询和键应用基于缩放后坐标的 3D RoPE,使位置编码连续且可跨域迁移。坐标在应用 RoPE 前还会添加随机抖动和缩放(见式 (1)-(5)),以增强尺度不变性。
- 因果模态遮蔽:随机缺失模态后,编码器仍能输出有效特征。
7. 如何找到两个点云的匹配关系
Utonia 不涉及点云间的匹配,其目标是学习单点云内每个点的特征表示。因此该问题不适用。
8. 如何基于两个点云的匹配关系计算点云之间的变换关系
Utonia 不计算点云间的变换。预训练任务是自监督特征学习,不涉及配准或变换估计。
9. 完整流程:输入点云到输出特征
- 输入:单个点云(包含坐标,可选颜色/法向)。
- 数据增强:应用随机空间变换(旋转、缩放、裁剪)、颜色抖动等,生成全局视图、局部视图、掩蔽视图(同 Sonata [44])。
- 模态遮蔽:在数据加载时以一定概率随机丢弃颜色/法向通道(因果模态遮蔽)。
- 粒度重缩放:将点云坐标按固定观察粒度缩放,使所有域的点云具有可比的空间单元。
- 编码:将视图输入 PTv3 编码器(带 RoPE 位置编码),得到多尺度特征。
- 自蒸馏:学生特征与教师特征(来自全局视图)在对应点位置对齐,通过在线聚类损失(Sinkhorn-Knopp)进行蒸馏。同时,若有图像,则加入跨模态余弦相似度损失(预测冻结 DINOv2 的图像块特征)。
- 输出:预训练完成后,可提取任意点云的编码器输出特征(可上投射至原始分辨率),用于下游任务。
10. 损失函数
总损失为模态内自蒸馏损失和可选的跨模态损失的加权和:
-
模态内自蒸馏损失:采用 DINOv2 的在线聚类损失(交叉熵),将学生特征与教师经过 Sinkhorn-Knopp 中心化后的聚类分配对齐。对于每个匹配的点对:
其中是学生特征经 softmax 的概率分布(温度),是教师特征经 Sinkhorn-Knopp 中心化后锐化的目标分布(温度)。
-
跨模态损失(若有图像):余弦相似度损失,鼓励点云特征与对应图像块特征接近:
权重通常取(即 1:1)。
11. 测试数据集与自建数据集
-
测试数据集:
- 室内语义分割:ScanNet [7], ScanNet200 [35], ScanNet++ [49], S3DIS [2]。
- 室外语义分割:NuScenes [5], Waymo [31], SemanticKITTI [4]。
- 物体分类与部分分割:ModelNet40, ScanObjectNN [38], ShapeNetPart, PartNetE [23]。
- 机器人操作:仿真环境(基于 Objaverse LVIS 子集 [8] 和 GraspVLA [9] 基准)。
- 开放世界部分分割:PartObjaverse-Tiny [48]。
- 空间推理:ScanRefer, Multi3DRefer, Scan2Cap, ScanQA, SQA3D(基于 Video-3D LLM [59])。
-
自建数据集:Utonia 未新造数据集,而是整合现有数据形成混合预训练集。具体构成见表 12,包括真实与合成数据,总计约 25 万点云场景 + 100 万 Cap3D 物体(采样后每 epoch 9 万)。训练分为两阶段:阶段 1 用高质量数据集(ScanNet, Structured3D, Waymo, PartNet)预训练稳定初始化;阶段 2 用全量混合继续训练 100 epoch。
12. 消融实验测试的组件
消融实验基于 38M PTv3 模型,在多域混合数据(83k)上预训练,评估于 ScanNet200、Waymo、PartNetE(部分结果见表 2、7、8 等)。
- 粒度与网格大小(Tab. 2):对比原始网格、网格抖动、固定网格,证明固定粒度对齐对联合训练至关重要。
- 模态遮蔽(Tab. 7d):对比在数据加载时、局部视图、掩蔽视图上应用模态遮蔽,发现数据加载时遮蔽效果最好。
- RoPE 有效性(Tab. 7b):在单域和多域设置下对比有无 RoPE,RoPE 持续提升性能,尤其对室外 LiDAR。
- RoPE 基频选择(Tab. 7c):测试基频从 1 到 10000,性能稳定,默认。
- 帧增强(Tab. 7e):对序列数据(Waymo)应用时间视图(教师聚合多帧对齐点云,学生用单帧),提升性能。
- RoPE 坐标增强(Tab. 7e):对 RoPE 的坐标添加随机抖动和缩放,略有提升。
- 随机尺度增强(Tab. 7e):在网格采样前随机缩放点云,提升对尺度变化的鲁棒性。
- 模型规模与数据规模(Tab. 7f):从 38M 扩至 137M,从 83k 扩至全量数据,性能持续提升,表明跨域预训练受益于更大容量和数据。
其他创新点
- 跨域涌现行为:可视化显示 Utonia 特征在不同域中保持几何结构一致,对重力方向的依赖减弱,物体级与场景级特征可对应(如图 5、6)。
- 下游应用扩展:Utonia 特征可直接用于机器人操作(GraspVLA)提升成功率(Tab. 9),用于 VLM(Video-3D LLM)提升空间推理(Tab. 10),用于开放世界部分分割(P3SAM)提升分割质量(Tab. 8, Fig. 6)。
在线聚类(online clustering)蒸馏
DINO / DINOv2 系列论文中采用的在线聚类(online clustering)蒸馏方法。其核心思想是:不是让学生直接模仿教师的原始特征向量,而是让学生模仿教师对特征进行分类后得到的“软标签”。
具体操作流程如下:
第一步:教师端生成目标分布
- 输入:教师网络提取的特征。
- 过程:
- 将输入到一个可学习的投影头(Projection Head,通常是一个小的 MLP)中,得到 logits。
- 对 logits 应用 Sinkhorn-Knopp 算法(一种最优传输算法)进行中心化处理。
- Sinkhorn-Knopp 的作用是:强制所有聚类(类别)上的特征分布尽量均匀,避免模型把所有点都划分到同一个聚类中(即防止模型坍塌)。
- 输出:得到一个“锐化”的概率分布。这个分布可以理解为:在当前的批次中,教师的特征应该被划分到个聚类中的哪一个(是预设的超参数,比如 65536 个聚类)。
第二步:学生端生成预测分布
- 输入:学生网络提取的特征。
- 过程:
- 同样将输入到另一个投影头(或共享投影头)中,得到 logits。
- 对 logits 应用 Softmax 函数(带温度参数软化),得到概率分布。
- 输出:得到一个概率分布,表示学生认为这个特征应该属于各个聚类的概率。
第三步:对齐(损失计算)
- 将第一步教师生成的分布作为**“固定的目标”(由于教师使用了 Sinkhorn-Knopp 且教师本身是通过动量更新的,可以视为稳定的目标),将第二步学生生成的分布作为预测值**。
- 计算和之间的交叉熵损失:
总结
所谓的“对齐”,在数学上就是 最小化学生预测的概率分布与教师经过 Sinkhorn-Knopp 处理后生成的目标分布之间的交叉熵。
- 教师的任务是:根据当前特征,划分出高质量的、均匀的聚类标签。
- 学生的任务是:预测这个聚类标签。
通过这种“预测聚类标签”而非“直接复制特征”的方式,模型能够学到更具判别性和语义性的特征。
 微信
微信- 支付宝

