
论文阅读_RectifiedPointFlow
Rectified Point Flow: Generic Point Cloud Pose Estimation
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Rectified Point Flow: Generic Point Cloud Pose Estimation |
| 作者 | Tao Sun, Liyuan Zhu, Shengyu Huang, Shuran Song, Iro Armeni |
| 作者单位 | Stanford University, NVIDIA Research |
| 时间 | 2025 |
| 发表会议/期刊 | NeurIPS 2025 |
| 特点 | 文章性质 |
|---|---|
| 输入 | 无序、无位姿、多部件点云集合(支持成对配准与多部件装配) |
| 输出 | 各部件在全局坐标系下的刚性位姿 Ti∈SE(3) 与装配完成的点云 |
| 所属领域 | 点云配准、多部件三维装配、流匹配生成式模型 |
摘要精简
Rectified Point Flow 提出一种统一的参数化方法,将成对点云配准和多部件形状组装建模为条件生成问题。它学习一个逐点的连续速度场,将噪声点传输到目标位置,进而恢复各部件姿态。该方法无需对称标签即可内在学习装配对称性,并结合关注部件间接触的重叠感知编码器,在六个基准数据集上达到新的最佳性能。统一的公式化支持在多种数据集上进行有效联合训练,促进共享几何先验的学习,从而提升精度。
引言出发点
- 位姿估计任务(配准、装配、位姿回归)长期孤立发展,依赖任务特定假设与结构,泛化性差.
- 多部件装配存在对称性、可替换性、几何歧义,传统逐部件位姿回归易产生局部合理但全局不一致的结果。
- 现有方法要么依赖显式对应,要么直接回归 6DoF 位姿,难以处理低重叠与对称歧义。
- 生成式流模型可建模全局形状先验,但缺少面向部件关系的几何感知预训练策略。
创新点
- 统一的生成式框架:提出 Rectified Point Flow,将成对配准和多部件组装统一为条件生成任务,通过预测完整装配点云同时实现姿态估计,达到多个基准上的新SOTA。
- 可扩展的几何感知预训练:设计一种轻量级且可扩展的预训练策略,通过逐点重叠预测(二分类)让编码器学习部件间几何关系,无需水密网格或仿真,支持在多种3D数据集(包括Objaverse)上预训练。
- 重叠感知编码器预训练:以部件间重叠点预测为预训练任务,让编码器聚焦部件接触区域,提升位姿估计鲁棒性。
- 对称性与可互换性的内在处理:**由于直接在欧氏空间对密集点云操作,模型天然对部件对称性和互换性鲁棒,无需额外数据增强或启发式。**通过理论证明(定理1)学习目标在装配对称群下不变。
- 跨任务联合训练:统一的参数化使得可以在六个不同数据集上联合训练流模型,学习共享几何先验,显著提升数据量有限的任务的性能。
- DiT 双注意力架构:部件内注意力 + 全局注意力,同时建模局部结构与跨部件全局约束。
白话时刻
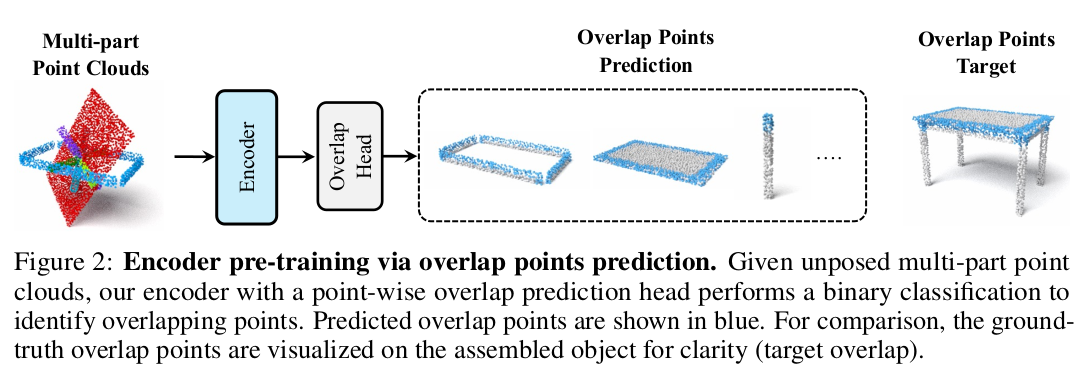
特征提取的训练
首先用一个PTv3的编码器进行预训练,首先拿一个配准好的点云,然后分成几个部分,有重叠部分,然后把这几个点云通过编码器,编码器后面接一个MLP,用于提取特征之后判断每个点云的重叠性
训练的真实步骤
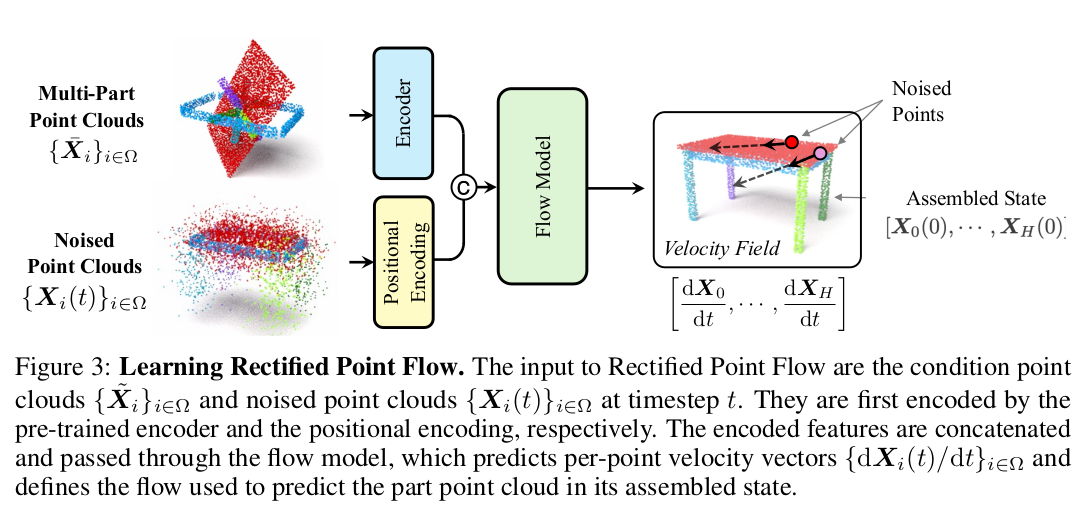
- 输入:散乱零件 A’、B’、C’……(就是你说的 “转完的待测点云”)
- 用 PTv3 编码器 提取每个零件的特征→ 得到条件特征 C
- 给组装好的 GT 点云 Y 加高斯噪声→ 得到带噪声的点 X (t)
- 把 X (t) + 条件 C 输入 DiT 扩散模型→ 模型预测 “去噪速度场” V。对每个零件的每个点,都预测一个 “位移向量”
- 监督信号:让模型学会把噪声点 → 还原成组装好的 Y
- 损失函数:让预测的速度场逼近真实速度场
推理的时候怎么做?(和训练一模一样)
- 输入:散乱零件 A’, B’
- 编码器提取条件特征 C
- 从纯高斯噪声开始
- 让 DiT 模型一步步去噪
- 最终直接输出:装配好的 A_gt, B_gt(两个仍然分开!), A’ 的第 1 个点 ↔ A_gt 的第 1 个点。点与点是一一对应的!顺序完全一样!**
最关键一步:怎么得到 R、t?
模型输出了 组装好的 Y_hat,它已经把 A、B 放在正确位置了。
现在只需要做一件事:对每个零件,用 SVD 算 RT
- 用 散乱 A’ ←→ 组装好的 A_hat
- 用 SVD(Kabsch) 算最优刚性变换
相关工作对比
- 姿态参数化:传统方法使用欧拉角/四元数(不连续),后续提出6D连续表示,或基于对应点+奇异值分解(SVD)的方法。最近有射线表示(RayDiffusion)和点图回归(DUST3R)。Rectified Point Flow采用密集点云/点图表示,扩展了该表示在点云配准和组装任务上的泛化性。
- 学习型3D配准:分为基于对应(如GeoTransformer)和直接回归(如DCPNet)两类。基于对应方法在低重叠场景(如形状组装)可能失败,直接方法精度不足。本文方法直接回归坐标,对重叠变化更鲁棒且泛化性更好。
- 多部件配准与组装:现有方法如MSN、SE(3)-Assembly、DiffAssembly、PuzzleFusion++、GARF等,大多不能很好处理对称性和可互换性,且GARF虽使用流匹配但局限于6-DoF姿态回归。Rectified Point Flow是首个在PartNet-Assembly和IKEA-Manual家具组装任务上取得成功的解决方案,且通过生成完整点云而非直接回归姿态,更好地学习全局形状先验。
网络架构构成
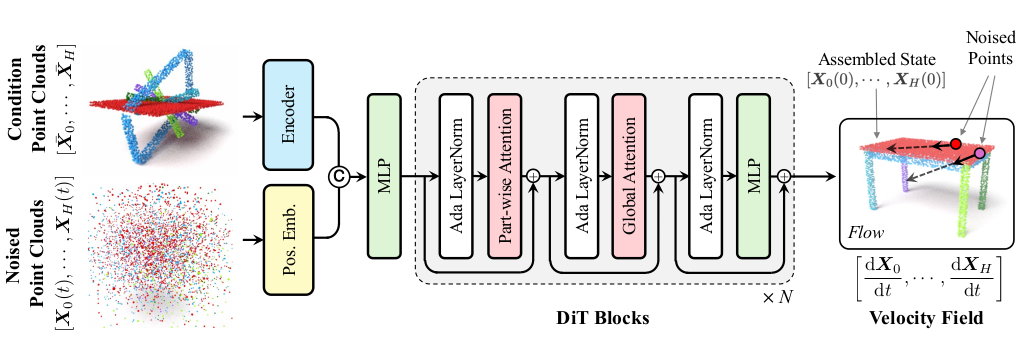
网络由两个主要阶段组成:
- 重叠感知编码器:以 PointTransformerV3 (PTv3) 为骨干,预训练进行逐点重叠预测(二分类)。输入为经过随机刚性变换的部件点云,编码器提取逐点特征,后接MLP预测重叠概率。预训练后编码器权重冻结,用作条件特征提取器。
- 条件 Rectified Flow 模型:使用 Diffusion Transformer (DiT) 作为流模型,包含6个DiT块,隐藏维度512,8个注意力头。每个DiT块包含:
- 部件自注意力:各部件内部点独立进行自注意力,捕获局部几何结构。
- 全局自注意力:所有部件点之间进行全局自注意力,促进跨部件信息交换。
- AdaLayerNorm:层归一化参数由时间步 调制。
输入包括:- 条件点云经编码器提取的特征;
- 带噪点云的位置编码(包括3D坐标、表面法线、部件索引的傅里叶特征);
- 时间步 。特征拼接后送入流模型,输出逐点速度场。
- 位姿解算模块:SVD(Kabsch)求解刚性变换。
数据集预处理与点云无序性/稀疏性处理
- 数据集:训练使用六个数据集:BreakingBad、TwoByTwo、PartNet-Assembly、IKEA-Manual(组装任务),TUD-L、ModelNet-40(配准任务),并额外使用Objaverse(通过PartField获取部件标注)进行编码器预训练。数据集包含不同部件定义(随机划分、语义部件、断裂仿真等)和规模。
- 测试数据集:上述数据集 + FRACTURA(零样本)。
- 预处理:
- 对每个输入部件点云施加随机刚性变换,使编码器学习姿态不变特征。
- 两个点云,固定第一个部件为锚点,归一化到单位球。
- 采样固定数量点,保证输入规模统一。
- 重叠标签生成:若部件某点距离其他部件任一点小于半径 ,则标记为重叠点。
- 点云无序性:PTv3本身设计用于处理无序点集,通过自注意力机制聚合邻域信息。
- 点云稀疏性:通过预训练重叠预测,编码器关注接触区域;流模型直接在坐标上回归,不依赖于点的顺序或密度均匀性。这样就实现了通过预测B点云到A点云的重复部分实现了预训练
特征提取
首先用一个PTv3的编码器进行预训练,首先拿一个配准好的点云,然后分成几个部分,有重叠部分,然后把这几个点云通过编码器,编码器后面接一个MLP,用于提取特征之后判断每个点云的重叠性
- 编码器预训练:PTv3接收随机变换后的部件点云,输出逐点特征 ,后接MLP预测重叠概率 ,使用二值交叉熵损失训练。预训练后编码器冻结,用于提取条件点云的特征。
- 流模型中的特征融合:对于带噪点云 ,应用多频傅里叶位置编码,包括3D绝对坐标、表面法线、部件索引的嵌入,与编码器输出的点特征拼接,作为DiT的输入。
- 流模型条件输入:
- 编码器输出的点特征
- 多频傅里叶位置编码
- 部件索引编码
- 噪声点位置编码

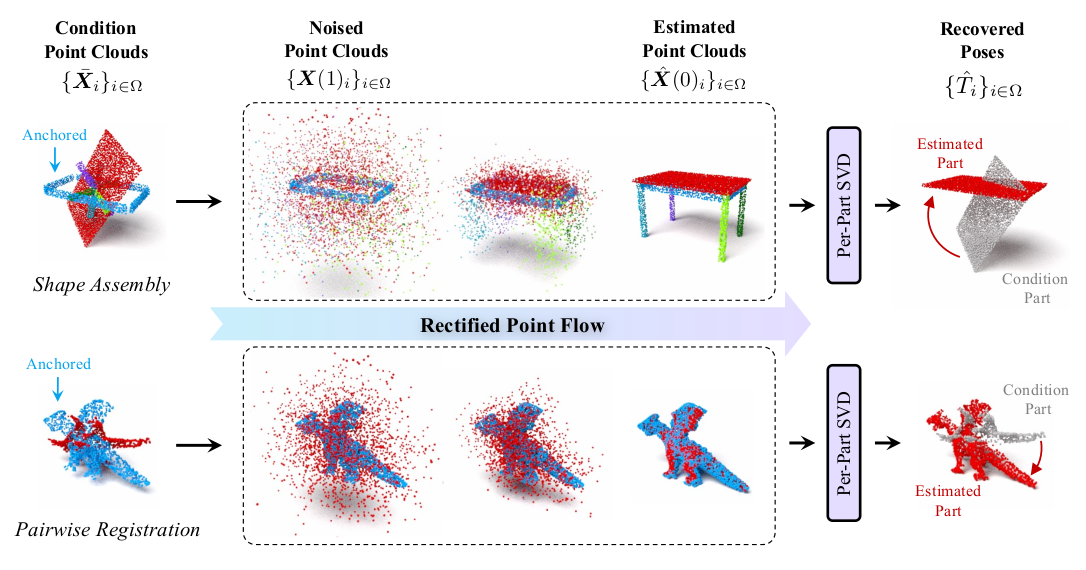
点云匹配关系
Rectified Point Flow 不显式建立点对应,不计算对应点、不计算匹配分数。
而是通过生成完整的装配点云来隐式建模匹配关系(B点云在A点云中的位置?)。
训练时,流模型学习将噪声点云映射到装配点云;
推理时,从噪声开始反向积分得到预测的装配点云 。
对每个非锚定部件,通过求解 Procrustes 问题(SVD)找到源点云 与预测装配点云 之间的最优刚性变换,从而实现匹配。
变换关系计算
固定锚定部件()的坐标系为全局坐标系。对于每个非锚定部件 ,采用SVD(Kabsch 算法) 求解: Ti=(Ri,ti)
输入无位姿点云
输入无位姿点云
使用SVD得到旋转矩阵 和平移向量 。此过程在得到预测装配点云后执行。
实验数据集
成对配准
- ModelNet40
- TUD-L
多部件装配
- PartNet-Assembly
- BreakingBad
- TwoByTwo
- IKEA-Manual
零样本泛化
- FRACTURA(骨骼断面数据集)
所有数据集均使用官方划分,联合训练显著提升小数据集性能。
完整流程:输入点云到输出变换关系
- 输入:多个未对齐的部件点云 。
- 编码:将输入点云送入预训练的PTv3编码器 ,得到逐点特征。
- 流模型训练:
- 定义装配状态点云 (GT)和噪声点云 。
- 线性插值 ,速度 。
- 流模型 以 、带噪点云 、条件特征为输入,预测速度 。
- 优化条件流匹配损失 。
- 推理:
- 从噪声 开始,使用欧拉法反向积分 步(),得到预测装配点云 。
- 对每个非锚定部件,通过SVD求解 对齐 与 ,得到最终姿态。
Loss函数
采用条件流匹配损失(Conditional Flow Matching Loss):
其中 是所有部件点云的拼接, 为真实速度(即 )。损失迫使网络预测的速度场逼近真实插值速度。
测试数据集
- 形状组装:BreakingBad(断裂物体)、TwoByTwo(插入部件)、PartNet-Assembly(语义部件)、IKEA-Manual(家具组装步骤)。
- 成对配准:TUD-L(RGB-D扫描)、ModelNet-40(随机分割)。
- 预训练:Objaverse 1.0(使用PartField获取部件标注,用于编码器预训练)。
- 各数据集按文献划分训练/验证/测试集,部件定义多样化(随机分割、语义标签、仿真断裂等)。
消融实验组件
- 编码器预训练任务:对比无预训练、实例分割预训练、重叠检测预训练(本文),验证重叠检测最有效。
- 与Point-BERT预训练对比:在PartNet-Assembly上,Point-BERT(点云补全预训练)导致性能下降,证明重叠检测更利于捕获部件间关系。
- 生成公式对比:Rectified Flow vs DDPM,RF在旋转/平移误差上显著更优。
- 锚定 vs 非锚定评估:展示非锚定设置下性能,但相对排名一致。
- 采样步数影响:分析步数对精度和运行时的权衡,选用20步。
- 部件刚性保持:通过RMSE和重叠率验证预测点云保持部件刚性。
- 零样本泛化:在FRACTURA数据集上零样本测试,优于GARF。
- 形状先验学习:构建圆柱数据集,在不同分割方案上测试,证明模型学到整体形状先验而非过拟合特定分割。
- 对称性处理:可视化IKEA-Manual上的多假设生成,展示模型能够产生合理的对称配置。
其他创新点
- 理论证明:证明学习目标在装配对称群 下不变(定理1),因此模型无需标签即可学会部件对称性和可互换性。
- 泛化界分析:通过Rademacher复杂度分析,证明尽管预测高维点云,但SVD步骤的收缩效应使得复杂度与6DoF方法同阶 ,保证了相当的泛化风险。
- 微信
- 支付宝

