
论文阅读_MC-MVSNe
MC-MVSNet: When multi-view stereo meets monocular cues
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | MC-MVSNet: When multi-view stereo meets monocular cues |
| 作者 | Xincheng Tang, Mengqi Rong, Bin Fan, Hongmin Liu, Shuhan Shen |
| 第一单位 | 北京科技大学 智能科学与技术学院 (School of Intelligence Science and Technology, University of Science and Technology, Beijing) |
| 时间 | 2026 |
| 发表会议/期刊 | Pattern Recognition (Volume 176) |
摘要精炼
本文提出了一种名为 MC-MVSNet 的新型多视图立体 (MVS) 框架,旨在通过整合多样化的单目线索来提升在挑战性场景(如遮挡和无纹理区域)下的深度估计鲁棒性。该框架主要通过三个核心模块实现:
1)混合特征融合模块,将传统的CNN特征与视觉基础模型(VFM)导出的全局几何感知特征相结合,以增强特征匹配的判别性;
2)代价体过滤模块,利用单目深度预测的跨视图几何一致性来修剪冗余的深度假设,从而缩小搜索空间并减少匹配歧义;
3)曲面块代价聚合模块,利用单目表面法向量构建与几何对齐的曲面块来聚合代价,提高了在曲面和无纹理区域的深度估计精度。在 DTU、Tanks and Temples 和 ETH3D 基准上的大量实验表明,MC-MVSNet 达到了最先进的性能,并展现出强大的泛化能力。
引言与动机
传统的基于学习的 MVS 方法虽然通过 CNN 的特征表示能力优于传统方法,但在处理非朗伯面、无纹理区域和遮挡等挑战性场景时仍然表现不佳。
近期,在大量多样化数据集上预训练的**单目视觉基础模型(VFM)**展现出了强大的泛化能力和场景理解能力,能够提取丰富的语义和几何感知特征。然而,直接将 VFM 应用于 MVS 面临两大挑战:
- VFM 的全局特征表示对于 MVS 所需的精确像素级匹配而言,判别性不足。
- VFM 的单目几何预测缺乏密集多视图匹配所需的精度。
因此,本文的出发点是:如何将 VFM 的强大单目线索适配到 MVS 的细粒度需求中,从而提升重建的准确性和鲁棒性。
创新点
本文的主要创新点在于系统性地将多种单目线索(深度、法向量、全局特征)集成到 MVS 的各个阶段,具体包括三个核心模块:
-
上下文混合特征自适应模块 (CHFA):针对现有 FPN 特征在处理非朗伯面或无纹理区域时存在的匹配歧义问题,提出将 FPN 提取的局部细节特征与 VFM 提取的全局几何感知特征进行融合。该模块在由粗到细的架构中,首先在粗阶段融合以引入全局上下文约束,然后在细阶段逐步融入更高分辨率的 FPN 特征以保留局部细节,从而在整个流程中增强了特征的判别力。
-
代价体过滤模块 (CVFM):针对代价体中存在大量冗余深度假设的问题(如前景像素与背景像素的匹配),提出利用单目深度预测作为场景几何的粗略预览来修剪这些假设。该模块包含两个部分:
- 绝对深度代价过滤 (ADCF):通过比较参考视图与源视图的单目深度差异,剔除跨视图几何不一致的假设,主要处理跨越前景和背景的假设。
- 基于排名的代价过滤 (RCF):对于位于同一深度层级的假设,通过保留几何一致性排名前k的假设,进一步消除冗余。
-
曲面块代价聚合模块 (CPCA):针对传统 3D CNN 或基于平面块 (PCA) 的代价聚合在曲面和边界区域效果不佳的问题,提出利用单目表面法向量来构建与底层曲面几何对齐的曲面块。通过插值相邻像素的法向量构建局部切平面,并计算邻域像素视线与该平面的交点,从而在更贴合真实曲面的形状上进行代价聚合,提升了在曲面和无纹理区域的估计精度。
相关工作对比
本文在相关工作部分主要与以下两类方法进行了对比,并指出了现有方法的不足:
- 基于学习的 MVS 方法:对比了 CasMVSNet (2020)、Vis-MVSNet (2023)、TransMVSNet (2022) 等工作。指出它们虽然在效率和精度上不断进步,但在复杂场景下依然面临挑战。
- 单目视觉基础模型:对比了 DepthAnythingV2 (2024)、Metric3D V2 (2024)、DINOv2 (2024) 等工作。指出尽管这些 VFM 在单目任务上表现出色,但其全局特征和预测结果难以直接满足 MVS 对像素级匹配和精度的要求。
- 集成单目线索的MVS方法:对比了 MonoMVSNet (2025)、MVSFormer (2023)、GoMVS (2024) 等。
- MVSFormer 虽融合了 DINO 特征,但本文提出的 CHFA 模块更进一步,在由粗到细的框架中进行了更系统的融合。
- GoMVS 虽使用了单目法向量进行平面块代价聚合,但其平面假设在曲率高的区域会失效,而本文提出的 CPCA 模块构建了曲面块,能更好地贴合真实几何。
- 与 MonoMVSNet 和 GoMVS 相比,本文是首个在 MVS 框架的特征层面、深度假设空间、代价聚合层面系统性地引入多种单目线索(深度、法向、特征)的工作。
网络架构
MC-MVSNet 采用了一个四阶段的由粗到细 (coarse-to-fine) 的架构。
- 特征提取:对于参考图像和源图像,分别使用 FPN 提取局部特征,并使用预训练的 VFM (Metric3DV2) 提取全局几何感知特征。
- 特征融合 (CHFA):在粗阶段(stage 1),将低分辨率的 FPN 特征与 VFM 特征拼接,并通过 2D CNN 融合,生成上下文特征。在后续的细阶段,将上一阶段的上下文特征上采样后,与当前阶段更高分辨率的 FPN 特征再次进行拼接和融合,生成最终的融合图像特征。
- 代价体构建:基于融合后的图像特征和逆深度假设,通过可微分的单应性变换构建代价体。
- 代价体过滤 (CVFM):利用单目深度预测对构建好的代价体进行过滤,剔除冗余的深度假设。
- 曲面块代价聚合 (CPCA):在过滤后的代价体上,利用单目法向量引导,在曲面块上对邻域代价进行聚合。
- 正则化与深度回归:聚合后的代价体通过堆叠的 2D CNN 进行正则化,得到概率体,再通过 soft-argmax 操作回归出深度图。
- 迭代与输出:上述过程在四个阶段中迭代进行,最终输出全分辨率的深度图。之后通过几何一致性检查过滤并融合成最终的点云。
特征提取
特征提取由两条并行的支路组成:
- 局部特征 (FPN):使用特征金字塔网络提取,用于捕获图像中的细粒度局部细节,但感受野较小。
- 全局几何感知特征 (VFM):使用预训练的 Metric3DV2 模型(冻结权重)提取。该模型在大量数据上训练,能够从单张图像中提取蕴含丰富全局上下文和隐式几何结构的特征。
这两类特征通过提出的上下文混合特征自适应模块 (CHFA) 进行融合,在粗阶段(stage 1),将低分辨率的 FPN 特征与 VFM 特征拼接,并通过 2D CNN 融合,生成上下文特征。在后续的细阶段,将上一阶段的上下文特征上采样后,与当前阶段更高分辨率的 FPN 特征再次进行拼接和融合,生成最终的融合图像特征。以生成更具判别性的特征表示。
代价体构建
代价体的构建基于可微分的单应性变换。对于参考视图上的一个像素 ,其在第 i 个源视图上,对应于深度假设 的投影坐标 为:
其中, 和 是参考视图和源视图的内参矩阵, 和 是相对旋转和平移。
构建匹配代价体时,采用分组相关 (group-wise correlation) 的方法,形成形状为G×D×H×W的初始 3D 代价体(G为通道数,D为深度假设数,H/W为图像高 / 宽)。

代价体过滤(CVFM 模块)
利用 Metric3D V2 预测的单目深度,通过 绝对深度代价过滤(ADCF)和基于秩的代价过滤(RCF) 两步修剪冗余深度假设,这可以看作是一种基于单目先验的、在正则化之前的代价体预处理。它通过两个步骤生成一个二值掩码 来过滤初始代价体 ,得到过滤后的代价体:
- ADCF:计算源视图单目深度扭曲到参考视图后的绝对深度差,设定深度容差因子,构建二值掩码过滤深度差超过τ的冗余假设;
- RCF:对每个像素保留深度差最小的k个深度假设,构建二值掩码,过滤低置信度的深度假设;
- 取两个掩码的交集M=Mabs∩Mrank,通过逐元素乘法过滤初始代价体:C′=C⊙M,得到过滤后的代价体。
代价体正则化
本文的代价体正则化分为两个步骤:曲面块代价聚合(CPCA 模块)和2DCNN 堆叠正则化两步:
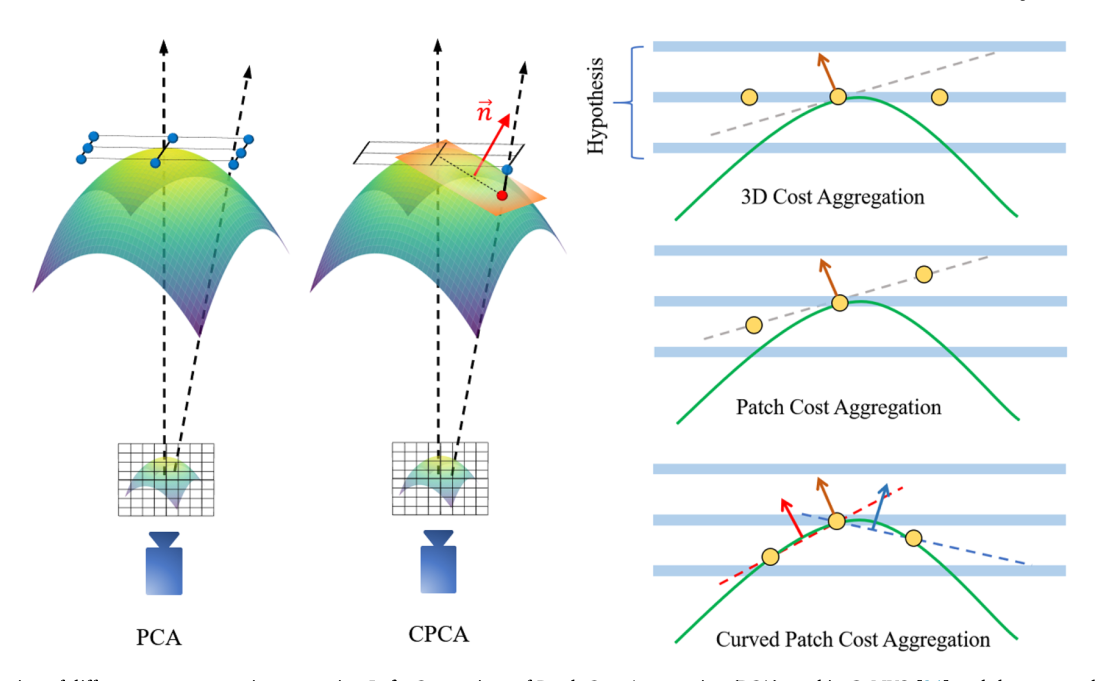
-
CPCA 模块:几何对齐的曲面块代价聚合
以 Metric3D V2 预测的单目表面法向量为局部几何先验,构建贴合场景真实曲面的局部块,实现代价聚合:
- 对参考视图像素 ((u, v)) 和深度假设 (d(u, v)),计算其在相机坐标系下的 3D 点:
其中 (f_x)、(f_y)、(c_x)、(c_y) 为参考相机内参;
-
对 局部窗口内的每个邻域像素 (j),插值参考像素与邻域像素的表面法向量 (),作为场景表面的一阶近似;
-
利用插值法向量 () 和 3D 点 (X(u, v)) 定义局部切平面,计算邻域像素视线与切平面的交点
- 从代价体中插值交点对应的代价,聚合到参考像素的代价体中,形成几何对齐的曲面块聚合代价体,形状为 为块核大小)。
-
2D CNN 正则化:对 CPCA 模块输出的聚合代价体,采用带跳连的 3D UNet+2DCNN架构进行正则化:在 3D UNet 的每个空间分辨率下,经代价聚合后接入 2DCNN 层,通过跳连保留细节特征,抑制代价体中的噪声,增强代价体的空间连续性和深度区分性,为后续深度预测提供更可靠的代价分布。
深度图生成
深度图是从正则化后的概率体中通过 soft-argmax 操作生成的。具体来说,对于每个像素,其最终的深度值 是对所有深度假设 及其对应的概率 进行加权求和:
这个过程在由粗到细的四个阶段中逐步进行,初始阶段预测一个低分辨率的深度图,然后在后续阶段,以上一阶段的预测为中心,在一个更窄的深度范围内进行细化,最终生成全分辨率的深度图。
Loss 函数
模型采用交叉熵损失进行监督。在每个阶段,将预测的概率体与由真实深度值转换而来的 one-hot 标签计算交叉熵。总的损失是所有阶段损失的总和。这种多阶段监督方式有助于网络更好地学习由粗到细的深度估计。
数据集
本文在以下数据集上进行了实验和评估:
- 训练与微调:在 DTU 数据集上训练,在 BlendedMVS 数据集上微调。
- 评估:
- DTU:用于主要定量和定性评估,与最先进方法进行比较。
- Tanks and Temples:用于评估模型在大型、真实场景上的泛化能力。
- ETH3D:用于评估模型在高分辨率、稀疏视图和宽基线等挑战性场景下的鲁棒性和泛化能力。
消融实验
为了验证各个模块的有效性,本文进行了一系列消融实验,主要测试了以下组件:
-
上下文混合特征自适应模块 (CHFA):
- 全局特征提取器选择:比较了 TransMVSNet 的 ViT、DINOv2、DepthAnythingv2 和 Metric3DV2,证明 Metric3DV2 效果最好。
- 融合策略:比较了通道相加和通道拼接,证明拼接效果更好。
- 融合阶段:验证了在粗阶段引入全局特征并在细阶段逐渐增加局部特征的最优性。
-
代价体过滤模块 (CVFM):
- 各组件消融:分别验证了绝对深度代价过滤 (ADCF) 和基于排名的代价过滤 (RCF) 的有效性。
- 参数敏感性:分析了 ADCF 中的阈值参数 和 RCF 中的 top-k 参数 对性能的影响。
-
曲面块代价聚合模块 (CPCA):
- 聚合策略比较:比较了无 PCA(标准3D CNN)、PCA(平面块代价聚合)和本文提出的 CPCA 的性能。结果表明,PCA 虽能提升完整性但可能损失精度,而 CPCA 在提升完整性的同时更好地保持了精度。
-
其他分析:
- 输入视图数量:分析了不同输入视图数量对重建性能的影响。
- 挑战性场景鲁棒性:在 DTU 的一个困难子集上评估了模型对反光、无纹理区域的鲁棒性。
- 计算开销:分析了模型的显存占用和推理时间,并提出了一个显存高效版本。
 微信
微信- 支付宝

