
DFS 与 BFS
DFS 与 BFS
在二叉树上进行 DFS 遍历和 BFS 遍历的代码比较。
DFS 遍历使用 递归:
1 | void dfs(TreeNode root) { |
BFS 遍历使用队列数据结构:
1 | void bfs(TreeNode root) { |
只是比较两段代码的话,最直观的感受就是:DFS 遍历的代码比 BFS 简洁太多了!这是因为递归的方式隐含地使用了系统的 栈,我们不需要自己维护一个数据结构。如果只是简单地将二叉树遍历一遍,那么 DFS 显然是更方便的选择。
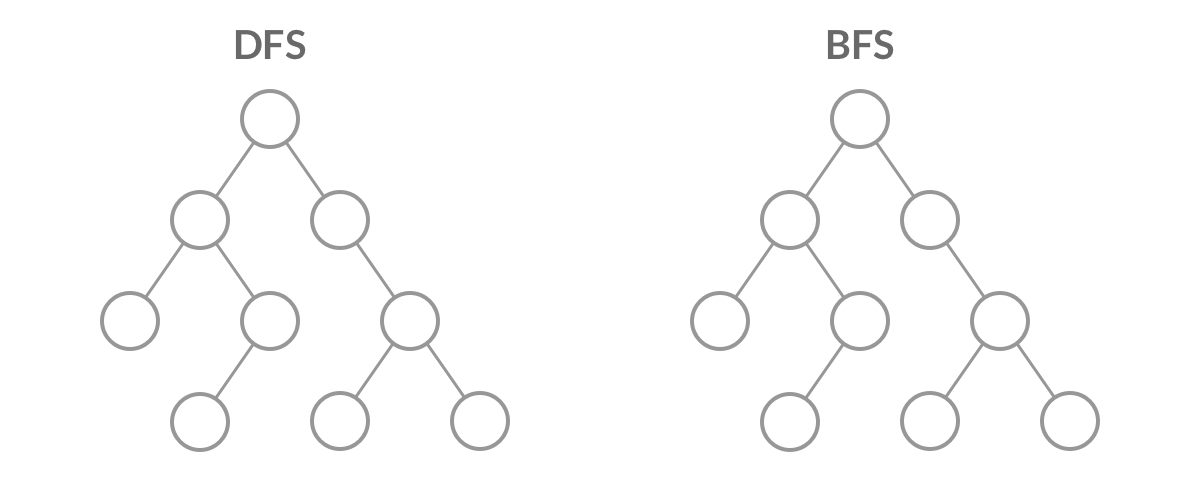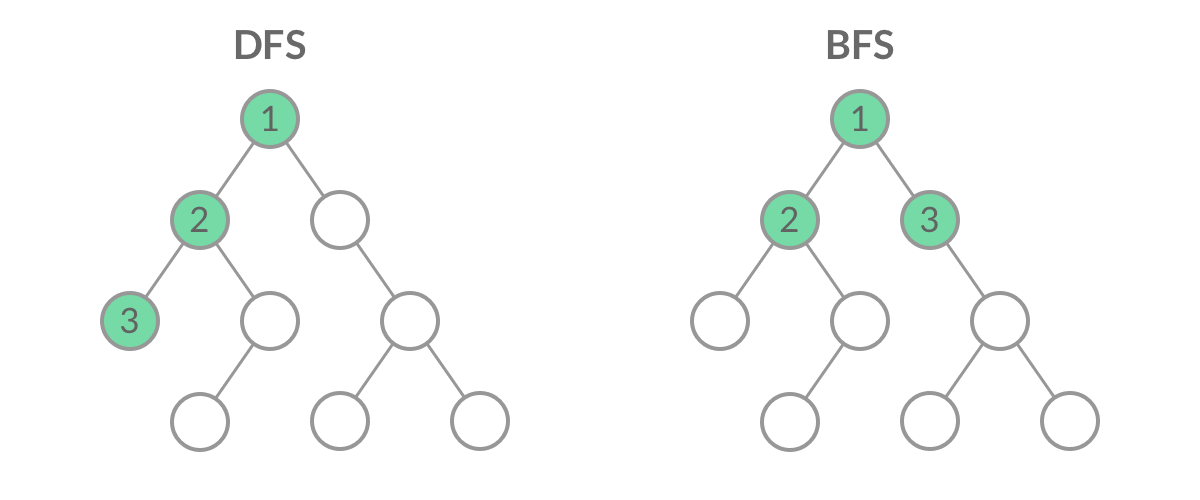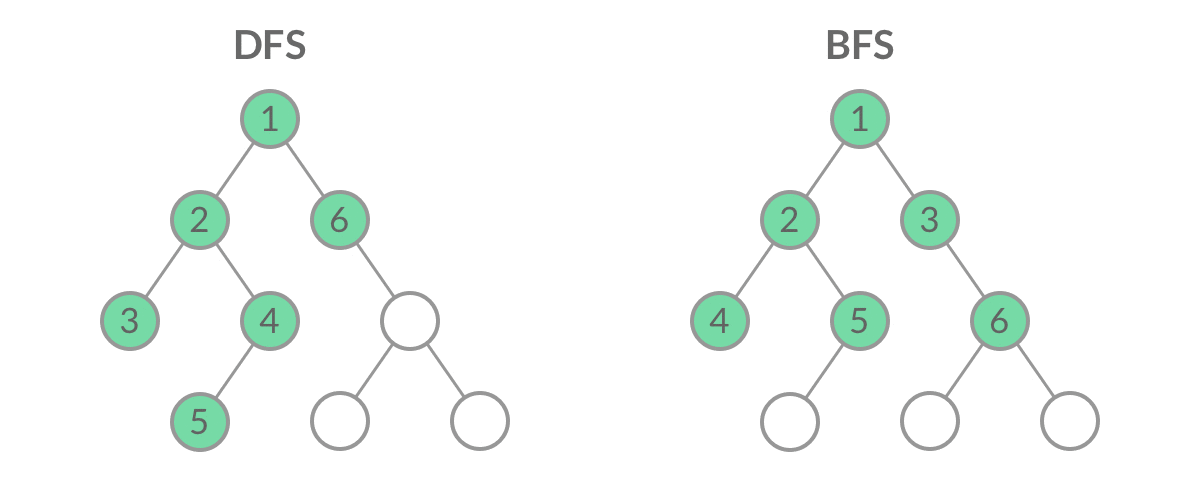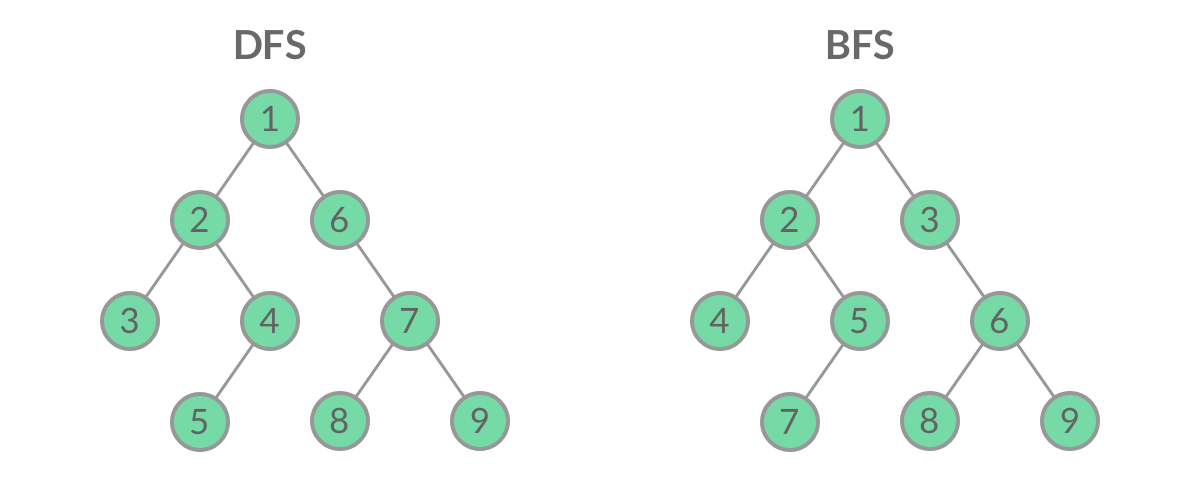
虽然 DFS 与 BFS 都是将二叉树的所有结点遍历了一遍,但它们遍历结点的顺序不同。
二叉树的递归和网格图的递归有何区别?
答:列表总结如下。
二叉树 网格图
递归入口 根节点 岛屿第一行最左边的陆地
递归方向 左儿子和右儿子 左右上下的相邻陆地
递归边界 空节点(或者叶节点) 出界、遇到水或者旗子
对于图 G 中的任意一条有向边 (u,v),u 在排列中都出现在 v 的前面。
那么称该排列是图 G 的「拓扑排序」。根据上述的定义,我们可以得出两个结论:
如果图 G 中存在环(即图 G 不是「有向无环图」),那么图 G 不存在拓扑排序。
如果图 G 是有向无环图,那么它的拓扑排序可能不止一种。举一个最极端的例子,如果图 G 值包含 n 个节点却没有任何边,那么任意一种编号的排列都可以作为拓扑排序。
假设我们当前搜索到了节点 u,如果它的所有相邻节点都已经搜索完成,那么这些节点都已经在栈中了,此时我们就可以把 u 入栈。可以发现,如果我们从栈顶往栈底的顺序看,由于 u 处于栈顶的位置,那么 u 出现在所有 u 的相邻节点的前面。因此对于 u 这个节点而言,它是满足拓扑排序的要求的。
这样以来,我们对图进行一遍深度优先搜索。当每个节点进行回溯的时候,我们把该节点放入栈中。最终从栈顶到栈底的序列就是一种拓扑排序。
算法
对于图中的任意一个节点,它在搜索的过程中有三种状态,即:
「未搜索」:我们还没有搜索到这个节点;
「搜索中」:我们搜索过这个节点,但还没有回溯到该节点,即该节点还没有入栈,还有相邻的节点没有搜索完成);
「已完成」:我们搜索过并且回溯过这个节点,即该节点已经入栈,并且所有该节点的相邻节点都出现在栈的更底部的位置,满足拓扑排序的要求。
通过上述的三种状态,我们就可以给出使用深度优先搜索得到拓扑排序的算法流程,在每一轮的搜索搜索开始时,我们任取一个「未搜索」的节点开始进行深度优先搜索。
我们将当前搜索的节点 u 标记为「搜索中」,遍历该节点的每一个相邻节点 v:
如果 v 为「未搜索」,那么我们开始搜索 v,待搜索完成回溯到 u;
如果 v 为「搜索中」,那么我们就找到了图中的一个环,因此是不存在拓扑排序的;
如果 v 为「已完成」,那么说明 v 已经在栈中了,而 u 还不在栈中,因此 u 无论何时入栈都不会影响到 (u,v) 之前的拓扑关系,以及不用进行任何操作。
当 u 的所有相邻节点都为「已完成」时,我们将 u 放入栈中,并将其标记为「已完成」。
在整个深度优先搜索的过程结束后,如果我们没有找到图中的环,那么栈中存储这所有的 n 个节点,从栈顶到栈底的顺序即为一种拓扑排序。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 This is a 部落格 of outbreak_sen!
 微信
微信- 支付宝

