
Bark模型微调
Bark模型微调
TTS模型/文本到语音(TTS)生成模型
以下开放的、已支持训练的 TTS 模型:
| 模型名 | 是否支持训练 | 特点 | 架构类型 |
|---|---|---|---|
SpeechT5(HuggingFace) |
✅ | 支持 TTS、VC、ASR,多任务训练 | |
Coqui-TTS(强烈推荐) |
✅ | 支持 Tacotron2/FastSpeech2/VITS | |
ESPnet(工业级框架) |
✅ | 支持多种语音模型,配置稍复杂 | |
YourTTS, VITS, GlowTTS |
✅ | Coqui-TTS/ESPnet 中均支持 | |
| VITS | VAE + GAN + flow | ||
| Bark | GPT decoder-only | ||
| Tacotron2 | encoder-decoder + attention |
EnCodec 解码器
EnCodec 是由 Facebook FAIR 开源的 神经压缩音频模型,可以高效地将音频压缩成离散 token,再解压回高质量语音。
类似于 VQ-VAE(Vector Quantized Variational AutoEncoder)结构
-
输入:Bark 生成的离散音频 token
-
输出:PCM waveform(可以保存为
.wav)
Bark模型
由 Suno 公司开发的一款基于 transformer 的文本到音频模型,多种语言,可以模拟非语言交流,如笑声、叹息和哭泣,提供了两个不同的模型大小(small 和 large)核心是一个 预训练的 GPT-style decoder-only 模型。
-
输入是:文本 + 音色信息(语者 embedding),
-
输出是:EnCodec(Facebook FAIR 开源的神经音频编码器)格式的离散音频 token
-
Bark 的最终输出是使用
EnCodec解码器把这些 token 解码为语音。
Suno 只开源了推理流程,没有发布训练脚本或训练数据预处理方式:
-
没有训练 loss 定义
-
没有 tokenizer 训练方法
-
没有 codec token 的 ground truth 标签准备方式
-
不能直接把音频作为
labels喂给模型。你需要先把音频转成 codec token -
from encodec import EncodecModel encodec = EncodecModel() token_ids = encodec.encode(audio)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
## 使用
~~~python
from transformers import AutoProcessor, BarkModel
import torch
import scipy
processor = AutoProcessor.from_pretrained("suno/bark-small", trust_remote_code=True)
model = BarkModel.from_pretrained("suno/bark-small")
inputs = processor(
text=["你好,我是 Bark 模型生成的语音[zh] 你好,我是来自中国的语音。[en_speaker_4] Hello, I am speaking with emotion.[laughs] Wow, this is amazing!"],
return_tensors="pt"
)
speech = model.generate(**inputs)
scipy.io.wavfile.write("bark_out.wav", rate=model.generation_config.sample_rate, data=speech.cpu().numpy().squeeze())# 时间长
Bark不能直接微调
Bark 的输入输出不是传统形式,属于非端到端 TTS
Bark 模型本身是一个大规模、冻结的 Transformer 模型,Hugging Face 官方没有发布 Bark 可训练版本,并且没有forward函数,只有generate函数,也没有提供微调脚本。这种方式不能微调成功,而没有实现 forward() 来返回 loss,这导致它无法适配 Trainer 或反向传播。Trainer 会直接报错或 silently fail。
Bark模型的三个阶段可以分别微调
一个barkmodel分为"BarkFineModel", “BarkSemanticModel”, “BarkCoarseModel”,都有forward函数
理论上是可以单独微调这三个子模型的
但是只训练 Bark 的 Semantic 模型(BarkSemanticModel)完全可行,而且这是目前在 Hugging Face 上最可控、最推荐的 Bark 微调路径。
| 模块名 | 对应类 | 输入 | 输出 | 功能描述 | 数据怎么来? |
|---|---|---|---|---|---|
| Semantic | BarkSemanticModel |
文本 token | semantic token | 生成语义级别的表示(类似意图/句子意义) | semantic |
| Coarse | BarkCoarseModel |
semantic token | coarse audio token | 生成粗粒度音频 token(频谱级别) | 原生 Bark 的 generate_coarse() |
| Fine | BarkFineModel |
coarse token | fine audio token | 精细音频 token,接近最终波形 | 原生 Bark 的 generate_fine() |
| EnCodec(非 Transformer) | - | fine token | waveform | 用 EnCodec 解码器合成音频 |
用 EnCodec 编码器对音频提取出:
- semantic token
- coarse token
- fine token
分阶段训练这三个子模型:
- Semantic:用
text_token → semantic_token - Coarse:用
semantic_token → coarse_token - Fine:用
coarse_token → fine_token
audioLM
audioLM作为音频领域的重要论文,却很少有人解读,无论是spearTTS,还是VALL-E,以及新鲜出炉的bark,核心思路都源于audioLM。这篇来源于google的方法,看框架像是SoundSream和w2v-BERT的结合版。音频分别通过上述2个模型获取semantic tokens, 代表语义,and acoustic tokens 代表声学信息。这里tokens都是离散值。为什么要离散,因为这样才便于使用语言模型或GPT那套建模方式,同时也去除了冗余信息,减小了模型的建模难度。
-
跟文本数据相比,音频的数据速率(1s音频包含24000个浮点值,而其对应的文本可能就4-5字)要高得多,从而导致序列更长,所以要变成离散值才能训练
-
其次,文本和音频之间存在一对多的关系。这意味着同一句话可以被不同的说话者用不同的说话风格、不同的情感甚至不同的环境下来表达。
从自监督音频模型 w2v-BERT 中提取的语义标记,不仅能够捕获音频中的局部依赖(例如,语音中的音素、钢琴音乐中的旋律)和全局长期结构(例如,句法和语义内容、钢琴音乐中的和声和节奏),还能对音频进行320倍的降维,这个模型解决了上述挑战1
但是如果直接用semantic token去生成音频,效果并不好,这是音频还存在一对多的问题。因此,引入了SoundStream提取额外的声学信息token,该token中可以包含发音人的音色信息,情感特征等。
训练分为了3个阶段

第一阶段只有语义token参与自回归方式的训练。
第二阶段声学token自回归,额外还加入上一阶段生成的语义token作为condition。输出的目标为声学token。
第三阶段也为自回归,使用声学模型处理粗略的声学token,类似tacotron的后处理网络postnet,这样可以在最终音频添加更多细节。
Encodec: 实现音频数据的高效压缩
语音大模型,第一个要提的就是VALL-E。VALL-E的一个非常重要的前置工作就是Meta的Encodec
音频数据要想实现实时传输,那我们就必须对其实现高度的压缩。但是,高度压缩又会不可避免地损坏音频数据的质量,造成信息的失真,也就是保真度下降。这其实就是音频数据压缩效率和质量的矛盾。我们在设计音频数据压缩算法时,就需要在压缩效率和压缩质量上做一个取舍。本文的工作解决的就是这个问题。工作的核心思想在于使用神经网络来实现这一压缩过程。
论文中设计的神经网络采样了典型的编解码器架构,带有一个Encoder和一个Decoder。为了实现量化的过程,Encoder和Decoder之间插入了一个Quantizer(量化器)。
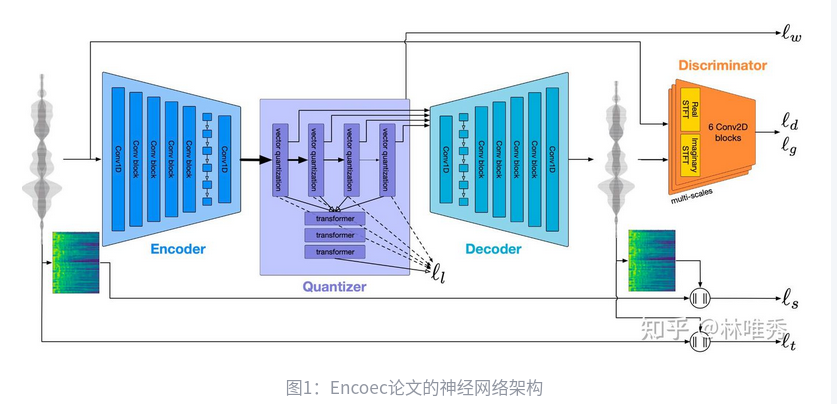
附录
- voice preset是什么
voice_preset字段的值来指定具体的音色。“{语言}spearker{n}”、“v2/{语言}spearker{n}”
 微信
微信- 支付宝

