
论文阅读_Uni-MVSNet
UniMVSNet
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference |
| 作者 | YRui Peng, Rongjie Wang, Zhenyu Wang, Yawen Lai, Ronggang Wang |
| 作者单位 | 北京大学电子与计算机工程学院 |
| 时间 | 2022 |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 多视角 |
| 输出 | 参考视角深度图 |
| 所属领域 | MVS |
1. 摘要精简
本文提出 UniMVSNet,通过统一深度表征和统一焦点损失,解决现有 MVS 方法中回归与分类的固有缺陷。**统一表征(Unification)兼具分类对代价体的直接约束能力和回归的亚像素深度预测能力;统一焦点损失(UFL)能更合理地解决样本不平衡问题,**适配连续标签。基于粗到精框架,该方法在 DTU 和 Tanks and Temples 基准测试中均排名第一,不仅性能最优,还具备最强泛化能力。
传统方法中:
- 回归方法:能实现亚像素深度预测,但容易过拟合
- 分类方法:能直接约束代价体,但只能离散预测
本文提出Unification表示和Unified Focal Loss,在DTU和Tanks and Temples基准测试中均排名第一。
就是提出了一个新的表述当前深度图生成质量的表示和一个新的对应的loss
2. 研究动机与出发点
-
回归方法(如 MVSNet)通过 Soft-argmin 加权深度假设得到深度,虽能实现亚像素精度,但间接学习代价体,易过拟合且权重组合存在歧义,收敛难度大;
-
分类方法(如 R-MVSNet)预测深度假设的概率,直接约束代价体,鲁棒性强,但离散预测无法直接得到精确深度,置信度推导不直观。
作者旨在统一两者优势,提出新的深度表征和损失函数,让模型既能直接优化代价体(如分类),又能输出精确深度(如回归),解决单一表征的局限性。
3. 创新点
3.1 统一的深度表示(Unification)
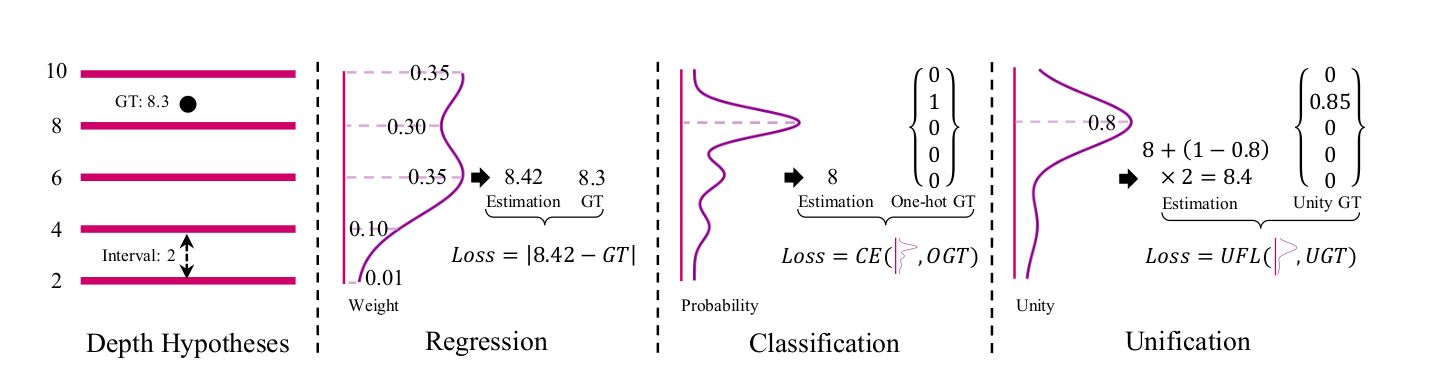
将深度估计重新构造为多标签分类任务:
- 分类:确定哪个深度假设是最优的
- 回归:估计最优假设与真实深度的偏移量
Unity生成:ground-truth unity在最优深度假设处有一个连续的非零目标(0∼1),表示与真实深度的接近程度Unity生成(标签构造)
对于每个像素,找到包含真实深度的最优深度假设:
1 | # 算法流程 |
Unity回归:使用sigmoid而非softmax,选择具有最大unity的深度假设,然后计算精确深度
3.2 统一焦点损失(Unified Focal Loss)
为了对应这种统一的深度表示来计算loss,新提出一个同一焦点损失
传统Focal Loss局限:
只能处理离散标签
统一焦点损失:
其中是sigmoid-like函数,控制缩放因子范围
4. 网络架构
UniMVSNet 基于粗到精框架(3 个阶段),整体分为五大模块,流程为 “特征提取→代价体构建→正则化→深度生成→损失优化”:
- 特征提取模块:FPN-like 网络提取多尺度图像特征;
- 代价体构建模块:深度假设采样、特征 warping、自适应多视图聚合;
- 代价体正则化模块:多尺度 3D CNN 平滑代价体;
- 深度生成模块:基于 Unity 的最优假设选择与偏移计算;
- 损失优化模块:多阶段 UFL 加权求和优化。
基于由粗到细的三阶段框架:
- 阶段1:1/4分辨率,48个深度假设
- 阶段2:1/2分辨率,32个深度假设
- 阶段3:全分辨率,8个深度假设
继承CasMVSNet pipeline:特征提取 → 代价体构建 → 代价体正则化 → 深度回归
5. 特征提取
采用 FPN-like 网络对参考图和源图提取多尺度特征,三个分辨率级别:1/4, 1/2, 1
6. 代价体构建
阶段 1~3 分别为 48、32、8 个假设
可变形聚合(类似[38]):
其中是通过辅助网络生成的可学习权重
7. 代价体正则化
- 使用多尺度3D CNN进行代价体正则化,生成概率体积,在Unification中被视为估计的Unity
8. 深度图生成
Unity回归算法:
- 选择具有最大unity的深度假设作为最优假设,对每个像素,选取 Unity 最大的深度假设
- 计算该假设与真实深度的偏移量,偏移计算:根据最优假设的相邻区间计算偏移,公式为:,
- 融合得到精确深度估计,最终深度为Dx,y=do+off,多阶段逐步细化,输出全分辨率深度图。
与传统的soft-argmax不同,只在最优假设上进行回归
9. 损失函数
总损失:
其中是第i阶段所有有效像素的UFL平均值
超参数设置:
- (保护正样本信号)
- (三个阶段)
- (三个阶段)
- :多阶段权重
10. 测试数据集
- DTU:室内数据集,124个场景,固定相机轨迹
- Tanks and Temples:复杂真实环境,分为中级和高级集
- BlendedMVS:大规模合成数据集,用于微调
11. 消融实验
- 统一表征(Unification):对比回归、分类、统一表征,验证统一表征在精度和完整性上的平衡优势;
- 统一焦点损失(UFL):对比 L1、CE、BCE、GFL、UFL,验证 UFL 对样本不平衡和连续标签的适配性;
- 自适应聚合(AA):验证自适应视图权重聚合对性能的提升;
- 更精细真值(FGT):对比普通真值与交叉过滤后的精细真值,验证真值质量的影响;
- 训练数据量:测试 50% 训练数据下的性能,验证模型数据效率;
- UFL 参数:消融基数值(e/5)、正样本缩放范围([1,2)/[1,3)),优化参数配置。
实验结果
- DTU:Overall 0.315mm,排名第一
- Tanks and Temples:Intermediate 64.36,Advanced 38.96,均排名第一
- 在弱纹理和反射区域表现更加鲁棒
总结
UniMVSNet通过统一的深度表示和焦点损失,成功结合了回归和分类方法的优点,在多个基准测试中达到了最先进的性能,同时具有良好的泛化能力。
 微信
微信- 支付宝

