
论文阅读_TransformerFusion
TransformerFusion
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | TransformerFusion:Monocular RGB Scene Reconstruction using Transformers |
| 作者 | Aljaz Bozic, Pablo Palafox, Justus Thies, Angela Dai, Matthias Niessner |
| 作者单位 | Technical University of Munich (TUM) |
| 时间 | 2021 |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 标定之后的多视角图像 |
| 输出 | Mesh |
| 所属领域 | MeshMVS |
摘要精简
本文提出 TransformerFusion,一种基于 Transformer 的单目 RGB 视频 3D 场景重建方法。该方法将视频帧通过 Transformer 网络融合为体素特征网格,以隐式表示场景;核心是利用 Transformer 的注意力机制,为每个 3D 位置学习选择最相关的图像帧,仅在需要处存储细粒度特征,兼顾内存效率与交互式重建速率。最终通过 MLP 从粗到细的插值特征中预测表面占用率,经 Marching Cubes 提取 3D 网格。实验表明,该方法在几何准确性和完整性上超越现有多视图立体匹配、全卷积 3D 重建及 LSTM/GRU 时序融合方法,达到当前最优性能。
引言与出发点
- 问题背景:从单目RGB视频进行稠密、完整的3D场景重建极具挑战,尤其是面向交互式应用。现有的多视图深度估计方法通常对序列中的所有帧特征进行平均,未能区分不同帧在不同区域的信息量差异(如运动模糊、物体遮挡或视角不佳),限制了重建质量。
- 研究目标:受Transformer在序列建模中的成功启发,提出一种基于Transformer的特征融合方法,能够在线、交互式地从RGB视频重建3D场景。
- 核心思路:设计一个Transformer网络,使其能够学习为场景中的每个3D位置选择并融合最具信息量的图像特征,从而获得更高质量的重建。
创新点
基于Transformer的时序特征融合
- 核心机制:使用Transformer架构替代简单的特征平均或基于RNN(LSTM/GRU)的融合。对于每个3D位置,网络将多视角的2D图像特征(及投影深度、视线方向等附加信息)作为序列输入,通过自注意力机制学习融合权重,从而动态地关注信息最丰富的视角。
- 优势:能够处理长序列,并学习复杂的视角依赖关系,对噪声、模糊或遮挡更具鲁棒性。
从粗到细的层次化融合与过滤
- 双分辨率特征网格:在粗分辨率(30cm)和细分辨率(10cm)两个层次上分别进行特征融合与存储。
- 近表面掩码预测:在粗、细两级额外训练一个分支来预测“近表面”掩码,用于在推理时过滤掉自由空间区域,仅在高可能包含表面的区域进行细粒度的特征融合与重建。
- 效果:显著减少了计算量和内存占用,使在线交互式重建成为可能(约7 FPS)。
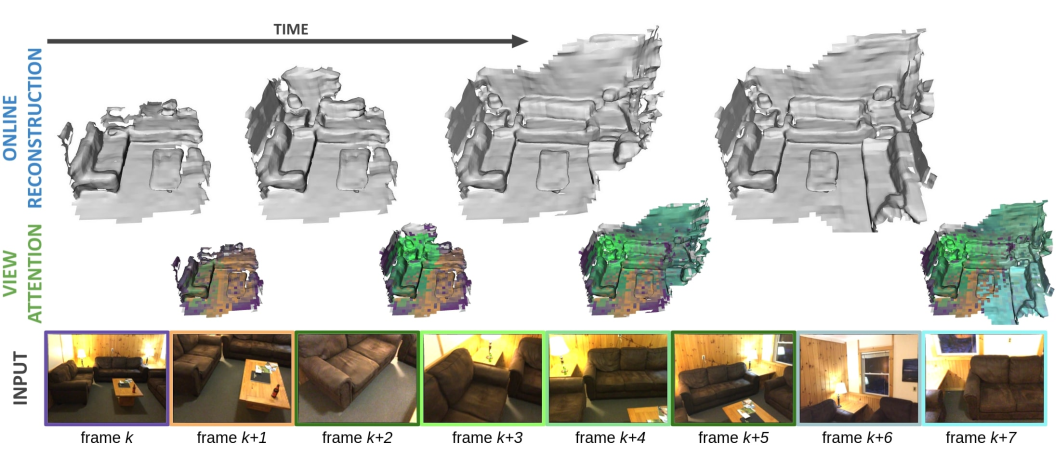
基于注意力的在线视图选择
- 增量式重建:在在线(逐帧处理)场景下,为每个3D位置仅保留最多 K=16 个最具信息量的视图特征。
- 选择策略:利用Transformer第一层注意力层的权重作为度量,当需要丢弃旧视图时,优先丢弃注意力权重最低的视图。
- 优势:在保证重建质量的同时,将每帧融合的处理开销控制在恒定水平,支持长视频处理。
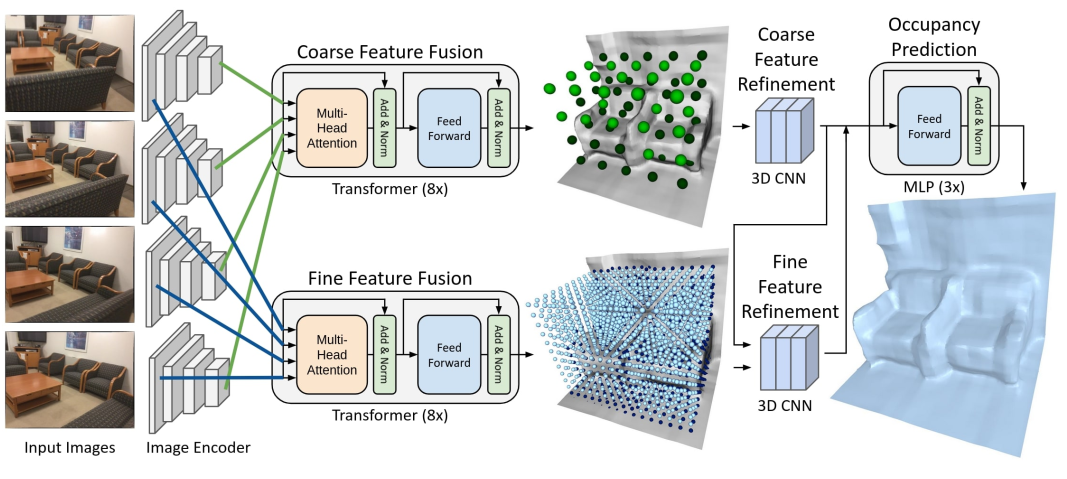
网络架构
网络为端到端框架,整体分为 5 个核心模块,输入单目 RGB 视频及相机内参 / 外参,输出 3D 网格:
- 图像编码模块:ResNet-18(ImageNet 预训练),提取每帧图像的粗粒度()和细粒度()2D特征图。
- 特征融合模块:两个独立的 Transformer 网络(:用于粗特征融合:用于细特征融合),分别融合所有帧的对应层级特征,输入所有帧对应层级的特征,输出:每个3D位置的融合特征(, )和注意力权重(, )
- 空间特征细化模块:
- 粗层级细化:3D CNN (3层残差块)作用于粗融合特征
- 细层级细化:将上采样后的粗细化特征与细融合特征 拼接,再输入3D CNN 进行细化
- 输出:空间一致的粗/细特征(, )
- 占用率预测模块:轻量级 MLP(3 层前馈网络),接收三线性插值后的粗 / 细特征 和 ,预测每个 3D 点的占用率(o∈[0,1])。
- 视图选择模块:基于 Transformer 的注意力权重,为每个 3D 位置动态保留 K=16 个高权重帧,新帧加入时丢弃最低权重帧,保障在线效率。
特征提取方式
特征提取围绕 “2D 图像特征→3D 位置特征→时序融合→空间细化” 展开,核心是多模态特征拼接与注意力融合:
- 2D 图像特征提取:通过 ResNet-18 的卷积层,分别输出粗、细两级特征图,覆盖不同层级的语义与几何信息。
- 3D 位置特征构建:对 3D 体素网格中的每个点p,通过相机投影$$ \Pi_i(\mathbf{p}) = \pi(\mathbf{K}_i(\mathbf{R}_i \mathbf{p} + \mathbf{t}_i)) $$计算其在各帧的 2D 投影位置,双线性采样对应帧的 2D 特征;同时拼接投影深度、视射线(ci为相机中心)、像素有效性(标记投影是否在图像内),将 输入一个线性层,得到嵌入向量
- 时序特征融合:粗/细Transformer分别接收对应层级的嵌入序列 ,通过 8 个 Transformer 模块(4 头自注意力,嵌入维度 256)学习融合,输出每个 3D 位置的时序融合特征 和第一层注意力权重
- 空间特征细化:对粗融合特征 应用3D CNN (3个残差块)后,通过最近邻上采样至细分辨率;将粗细化特征上采样至细分辨率,与细融合特征 拼接,再经细 3D CNN 细化,输出空间一致的细化特征 ,最后得到空间一致的粗 / 细特征(ψ~c、ψ~f)。
网格生成流程
Mesh 生成采用 “粗到细筛选→占用率预测→表面提取” 的流程,拓扑由占用场自动决定:
- 特征融合与细化:对于输入的视频帧序列,逐帧提取特征,并通过Transformer和3D CNN逐步更新粗、细两级全局体素特征网格。
- 表面占据场预测:对整个场景空间(或分块)进行密集采样,对于每个3D点 p,从粗、细特征网格中三线性插值得到特征 和 。
- MLP解码:将拼接后的特征输入MLP 𝒮,预测该点的占据值 o = 𝒮(ψ_p^c, ψ_p^f)。
- 等值面提取:使用Marching Cubes算法从预测的占据场(o ≥ 0.5 视为占据)中提取三角形网格表面。
损失函数
总损失函数由三部分组成:
- :粗层级近表面掩码预测的二元交叉熵损失。监督信号 由真值表面生成,若一个粗体素在 (30cm) 半径内有真值表面,则标记为近表面。
- :细层级近表面掩码预测的二元交叉熵损失。监督方式同上,半径阈值 (10cm)。
- :表面占据预测的二元交叉熵损失。在训练块内采样点(80%靠近表面,20%均匀采样),并根据真值扫描重建数据赋予占据标签 。
训练与测试数据集
- 训练数据集:ScanNet 数据集。一个大规模的室内场景RGB-D视频数据集。训练时从中随机采样 1.5m x 1.5m x 1.5m 的块。(约 165k 个训练块),每个块随机选择Kt=8张包含该块的 RGB 帧。
- 测试数据集:同样在 ScanNet 数据集的官方测试集上进行评估和对比实验。
推理与部署输入输出
- 输入:单目RGB视频序列(已知相机内参及每帧的位姿)。
- 输出:重建出的整个场景的3D三角形网格。
- 在线处理:系统支持在线增量式重建。每来一帧新的RGB图像,即更新内部的体素特征网格,并可根据需要实时提取当前已重建部分的网格。
消融实验测试组件
- Transformer融合 vs. 特征平均:
w/o TRSF, avg:用MLP处理单视角特征后直接平均融合。w/o TRSF, pred:用MLP预测权重进行加权平均。- 结论:Transformer融合显著优于平均策略。
- 空间特征细化 (3D CNN):
w/o spatial ref.:移除空间特征细化网络。- 结论:空间细化对几何完整性(召回率)至关重要。
- 从粗到细过滤 (C2F Filter):
w/o C2F filter:不使用近表面掩码进行过滤,在所有区域进行细粒度重建。- 结论:C2F过滤带来性能提升,并带来约3.5倍的运行加速。
- 使用的视图数量 (K):
- 测试了 K=4, 8, 16 帧。
- 结论:更多视图带来更好性能,但受计算和内存限制。
- 基于注意力的视图选择策略:
RND:从能看到该点的帧中随机选择K帧,而非基于注意力权重。- 结论:基于注意力的选择策略明显优于随机选择,在视图数量少时优势更大。
- Transformer的输入信息(补充材料):
w/o projected depth:移除投影深度输入。w/o view ray:移除了视线方向输入。- 结论:这两者都是有益的信息。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 This is a 部落格 of outbreak_sen!
 微信
微信- 支付宝

