
论文阅读_SyncDreamer
SyncDreamer: Generating Multiview-Consistent Images from a Single-view Image
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | SyncDreamer: Generating Multiview-Consistent Images from a Single-view Image |
| 作者 | Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, Wenping Wang |
| 作者单位 | The University of Hong Kong, Tencent Games, University of Pennsylvania, Texas A&M University |
| 时间 | 2023 |
| 发表会议/期刊 | ICLR 2024 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 单视角物体图像 |
| 输出 | 多视角一致图像(用于3D重建) |
| 所属领域 | 单视角三维重建、多视角合成 |
摘要精简
SyncDreamer是一种新颖的扩散模型,能够从单视角图像生成多视角一致的图像。该模型通过同步的多视角扩散过程,在一次反向过程中联合生成所有视角的图像,利用3D感知的特征注意力机制在不同视图间同步中间状态,从而在几何和颜色上保持高度一致性。核心设计是通过 3D 感知特征注意力机制,在反向扩散的每一步同步所有生成视图的中间状态,建模多视角图像的联合概率分布。模型基于预训练的 Zero123(Stable Diffusion 变体)初始化,保留强泛化能力,可处理照片、素描等多种风格输入。**生成的多视角图像无需 SDS 损失,直接通过 vanilla NeuS 即可重建高质量 3D 网格,其实就是借助了NeRF的变种。**实验表明,其在多视角一致性(PSNR/SSIM/LPIPS)和 3D 重建精度(Chamfer 距离 / Volume IoU)上显著超越 Zero123、RealFusion、Magic123 等基线,且支持生成多个合理的 3D 实例。
SDS
SDS 的本质: 用一个“已经训练好的 2D 扩散模型”,来给一个“正在优化的 3D 表示”提供梯度信号,让 3D 模型渲染出来的图像,逐渐变成扩散模型认为“符合文本语义的图像”。SDS 就是连接 2D diffusion 和 3D 表示的桥梁。
DreamFusion 的 SDS 有明显缺陷:每个视角独立优化,容易出现 Janus problem(多脸怪)

引言与出发点
从单张图像感知3D结构是一个挑战,因为图像中可用的3D信息有限。虽然已有基于扩散模型的2D图像生成方法取得巨大成功,但直接训练泛化性强的3D扩散模型需要大量3D数据,而现有3D数据集不足以覆盖任意3D形状的复杂性。因此,近期工作尝试利用预训练的2D扩散模型进行3D任务,例如通过蒸馏(distillation)方法从文本生成3D形状,或将此流程用于单视角重建。然而,这些方法通常需要耗时的文本反转(textual inversion)和NeRF优化,且不能保证结果质量。
另一种思路是直接用2D扩散模型生成多视角图像用于3D重建,但关键问题是如何在生成同一物体图像时保持多视角一致性。现有方法通过条件输入、自回归生成或神经场渲染等方式试图提升一致性,但要么局限于特定物体类别,要么无法保证任意物体的一致性。
因此,本文提出SyncDreamer,旨在为任意物体的单视角重建生成多视角一致的图像。核心思想是将扩散框架扩展为对多视角图像的联合概率分布进行建模,通过同步的多视角扩散模型,在反向过程的每一步同步所有生成图像的中间状态,从而实现一致性。
创新点
- 同步多视角扩散模型:首次提出同步多视角扩散模型,将单视角生成扩展到多视角联合生成,通过建模多视角图像的联合概率分布,在一次反向过程中同步生成所有视角的图像,确保几何和外观的一致性。
- 3D感知的特征注意力机制:设计了一个新颖的3D感知特征注意力模块,通过构建空间特征体(spatial feature volume)和视图视锥体特征(view frustum feature volume),并在UNet的中间特征图上应用深度注意力(depth-wise attention),以关联不同视角间的对应特征,从而在生成过程中同步各视角状态。
- 固定视点生成策略:在训练和生成时使用一组固定的目标视点(方位角均匀分布,仰角固定为30°),这简化了多视角一致性学习,并使模型更容易收敛。
- 高效的3D重建流程:生成的图像具有高度一致性,因此可以直接使用标准的NeRF或NeuS进行重建,无需复杂的损失函数或耗时的优化,简化了单视角3D重建流程。
- 强泛化能力与多样性:模型权重基于在Objaverse上微调的Zero123模型初始化,继承了其强大的泛化能力,能够处理照片、草图、卡通、油画等多种风格的输入,并能从同一输入生成多个合理的3D实例。
相关工作总结与对比
| 对比方法 | 核心问题指出 |
|---|---|
| Zero123(单视角扩散) | 1. 多视角一致性差,生成图像几何矛盾;2. 直接重建 3D 表面粗糙,需 SDS 优化;3. 无纹理渲染时一致性崩溃 |
| RealFusion(SDS 蒸馏) | 1. 依赖文本 inversion,耗时且细节匹配差;2. 生成图像视觉不逼真;3. 多视角一致性依赖蒸馏,稳定性低 |
| Magic123(混合先验) | 1. 依赖外部深度估计,深度不准时重建错误;2. 过度依赖 Zero123 输出,继承其一致性缺陷;3. 泛化性受深度模型限制 |
| Point-E/Shap-E(3D 生成) | 1. 重建网格不完整,细节缺失;2. 单图输入时文本嵌入匹配差,几何精度低;3. 无法生成多个合理实例 |
| One-2-3-45(SDF 回归) | 1. 从 Zero123 的不一致输出回归 SDF,丢失细节;2. 重建表面光滑但几何失真;3. 不支持多种风格输入 |
| 相关领域 | 代表性工作 | 指出问题/局限性 |
|---|---|---|
| 3D扩散模型 | Point-E, Shap-E, 3D生成扩散模型 | 直接训练3D扩散模型需要大量3D数据,现有数据集不足,生成质量和泛化性仍远不如2D图像生成模型。 |
| 基于蒸馏的2D提升方法 | DreamFusion, SJC, RealFusion, Magic123 | 需要耗时的文本反转和NeRF优化;每个形状需单独优化且结果难以预测;受限于文本嵌入的表示能力。 |
| 基于2D扩散的多视角生成 | Zero123, SparseFusion, Viewset Diffusion, MVDream | Zero123逐视角生成,缺乏多视角一致性;其他方法或依赖已知几何、或采用自回归生成、或局限于特定类别;MVDream面向文本到3D,而SyncDreamer专注于单视角到多视角。 |
| 单视角重建传统方法 | 基于回归或检索的方法,NeRF-GANs | 泛化性差,难以处理新类别;NeRF-GANs通常针对特定类别训练,难以扩展到任意物体。 |
网络架构
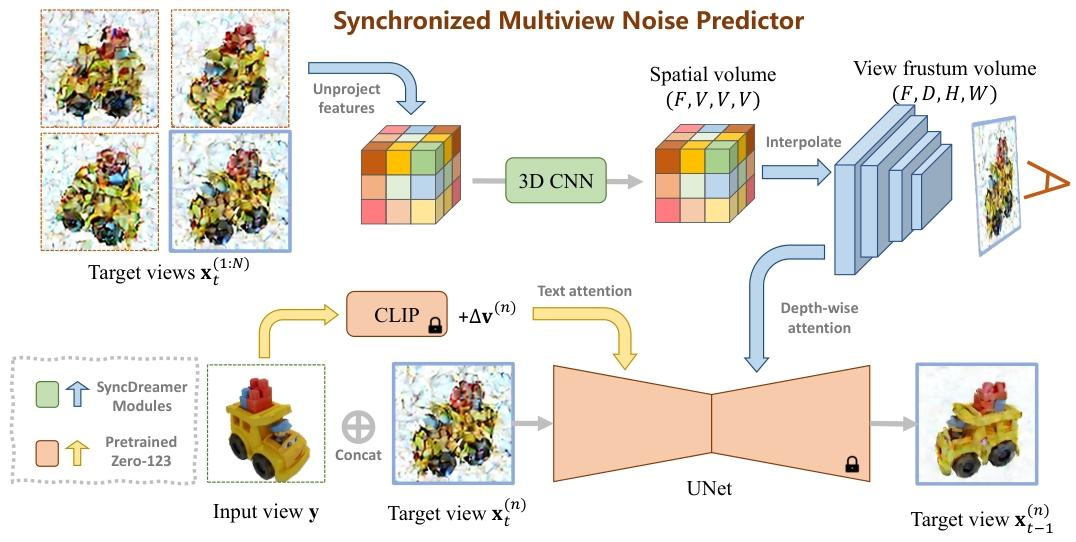
SyncDreamer的核心是一个同步的多视角噪声预测器,其架构如图2所示,主要包括:
- 主干UNet:基于Zero123的UNet初始化,输入为噪声目标视图、输入视图和视角差。训练时,UNet和文本注意力层被冻结以保持泛化能力。
- 3D感知特征注意力模块:
- 空间特征体构建:从所有噪声目标视图通过卷积提取特征,并投影到3D空间,形成大小的空间特征体。
- 视图视锥体特征采样:为当前目标视图构建一个像素对齐的视锥体,通过从空间特征体插值获得其特征。
- 深度注意力层:在UNet的每个中间特征图上,新增的深度注意力层沿深度维度对视锥体特征进行注意力操作,以聚合多视角信息。
- 同步生成流程:对个目标视图,分别构建一个共享的噪声预测器,但在反向扩散的每一步,通过上述3D感知注意力机制共享所有视图的信息,从而实现同步生成。
特征提取机制
特征提取的核心是3D感知的特征注意力,其步骤如下:
- 多视角特征提取:每个噪声目标视图通过卷积层提取2D特征图。
- 3D空间特征体构建:将所有2D特征图通过投影(利用已知相机参数)聚合到一个3D空间特征体中,捕获场景的几何结构。
- 视图视锥体采样:对于当前待去噪的视角,根据其相机参数,从3D空间特征体中采样出一个与图像像素对齐的视锥体特征体积(),其中是深度平面数。
- 深度注意力融合:将UNet中间层的2D特征图()与视锥体特征体积进行深度注意力计算。具体地,将2D特征图的每个空间位置沿通道维视为查询(query),在视锥体特征体积的对应深度列()上进行注意力,从而融合多视角几何信息,增强特征的一致性。
三维物体生成流程
从单视角图像生成3D物体的完整流程分为两步:
-
多视角一致图像生成:
- 输入:单视角图像(支持 256×256 分辨率,风格包括照片、素描、卡通等),粗略估计输入图像的仰角(或使用外部估计器);
- 过程:使用训练好的SyncDreamer模型,以为条件,通过扩散模型的反向过程(如DDIM采样)同步生成个(默认16个)固定视点下的多视角图像。这些图像在几何和外观上保持一致,计算每个目标视图与输入视图的姿态差异Δv(n)。
- 可选:可以生成多个随机种子下的实例,选择最合理的一组用于重建。
-
初始化
- 为 16 个目标视图分别初始化噪声图像xT(1:16)∼N(0,I);
- 加载预训练 Zero123 权重,冻结 UNet 和文本注意力层,初始化 3D 感知特征注意力模块参数。
-
同步反向扩散
- 迭代 T 步(默认 50 步 DDIM 采样),每步执行:
- 对每个目标视图n,将xt(n)与输入图像拼接,输入 UNet 编码器;
- 构建所有视图的空间特征体积,经 3D CNN 和视锥体插值得到当前视图的视锥体特征;
- 深度注意力层融合视锥体特征与 UNet 中间特征,解码器预测噪声ϵθ(n);
- 按 DDIM 更新规则计算xt−1(n),同步更新所有视图的图像。
- 迭代 T 步(默认 50 步 DDIM 采样),每步执行:
-
多视角图像输出
- 迭代结束得到 16 个视角一致的图像,使用 CarveKit 提取前景掩码,去除背景干扰。
-
3D 重建
-
将多视角图像与对应的相机参数输入 vanilla NeuS,训练 2k 步(约 10 分钟);
-
NeuS 学习神经隐式表面,通过 Marching Cubes 提取 3D 网格,输出最终 3D 模型。
-
数据集与实验对比
训练数据:
- 3D数据:Objaverse数据集(约80万个物体),渲染多视角图像进行训练。
- 输入视图:16个随机视角(与目标视图方位角相同,仰角随机)。
- 目标视图:16个固定视角(方位角均匀分布于,仰角固定为30°)。
测试数据与对比:
- 测试集:Google Scanned Object (GSO) 数据集(30个物体)以及从互联网收集的图像。
- 对比方法:
- 新视角合成:Zero123、RealFusion。
- 单视角重建:Zero123+SDS、RealFusion、Magic123、One-2-3-45、Point-E、Shap-E。
- 评估指标:
- 新视角合成 (NVS):PSNR、SSIM、LPIPS,以及使用COLMAP从生成图像中重建出的点数(衡量多视角一致性)。
- 单视角重建 (SVR):倒角距离 (Chamfer Distance)、体积IoU。
- 主要结果:
- NVS:SyncDreamer在PSNR、SSIM、LPIPS上均优于Zero123和RealFusion,且COLMAP重建点数远高于Zero123(1123 vs 95),证明其生成图像的多视角一致性更好。
- SVR:SyncDreamer在倒角距离和体积IoU上均达到最优,重建出的网格更平滑、细节更好。
消融实验
- 3D感知注意力模块的作用:
- 移除该模块(相当于在固定视点上微调Zero123)后,生成图像的多视角一致性显著下降,证明了该模块对保持一致性的必要性。
- 模型初始化策略:
- 比较从Stable Diffusion初始化 vs 从Zero123初始化。从Zero123初始化能更好地利用其3D先验,生成质量更高,泛化能力更强。
- UNet训练策略:
- 比较冻结UNet vs 微调UNet。冻结UNet可以防止过拟合(避免模型将物体预测为薄板),保持更好的生成质量和泛化性。
- 深度注意力层的设计:
- 将深度注意力替换为直接在视锥体特征体积上应用2D卷积,会导致生成质量下降和形状失真,证明了深度注意力设计的有效性。
- 生成视角数量对重建的影响:
- 使用16、8、4个生成视图进行NeuS重建。实验表明,8个视图仍能保持较好质量,但4个视图会导致重建质量显著下降。
其他创新与讨论
- 支持多样化输入风格:SyncDreamer能够处理卡通、素描、水墨画、油画等多种风格的2D输入,并生成合理且一致的3D模型,展示了强大的泛化能力。
- 生成多样性:由于扩散模型的随机性,SyncDreamer可以从同一输入图像生成多个合理的3D实例,为用户提供了选择空间。
- 扩展到文本到3D:通过结合文本到图像模型(如Stable Diffusion),SyncDreamer可以实现文本到3D的生成,用户可以先生成满意的2D图像,再将其输入SyncDreamer得到3D模型,流程更灵活。
- 局限性:
- 生成的视角固定,如需其他视角需依赖重建的神经表面进行渲染,可能导致模糊。
- 生成质量受输入图像中物体大小(透视模式)影响,对训练分布外的透视模式泛化能力有限。
- 生成的纹理有时细节较少,因为模型倾向于生成易于保持多视角一致性的较大纹理块。
 微信
微信- 支付宝

