
论文阅读_SpatialTrackerV2
SpatialTrackerV2: 3D Point Tracking Made Easy3D
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | SpatialTrackerV2: 3D Point Tracking Made Easy3D 点跟踪变得简单 |
| 作者 | Yuxi Xiao1∗ Jianyuan Wang2 Nan Xue3 Nikita Karaev2,4 Yuri Makarov4 Bingyi Kang5 Xing Zhu3 Hujun Bao1 Yujun Shen3 Xiaowei Zhou ∗:平等贡献;†:项目负责人;‡:通讯作者。 |
| 作者单位 | 浙江大学 牛津大学 蚂蚁集团 Pixelwise AI 字节跳动种子(Bytedance Seed) |
| 时间 | 20250719axiv |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 单目视频 |
| 输出 | 3D 场景几何形状、相机姿势和 3D 点轨迹 |
| 所属领域 | 点跟踪,三维重建 |
| 一句话总结做了什么 | 从任意场景的单目视频中一次性生成一致的 3D 场景几何形状、相机姿势和 3D 点轨迹。这个和SpatialTracker不是一个东西了,做的是feedforward |
摘要
SpatialTrackerV2 是一种前馈式的三维点跟踪方法,专为单目视频设计。与基于现成组件构建的模块化流水线不同,这种方法将点跟踪、单目深度估计和相机姿态估计之间的内在联系统一起来,形成了高性能且前馈式的三维点跟踪器。
以下是 SpatialTrackerV2 的主要特点和优势:
- 分解世界空间中的3D运动:该方法将世界空间中的三维运动分解为场景几何形状、相机自身运动和像素级物体运动。通过完全可微分和端到端的架构实现这一点,使得它可以跨各种数据集进行可扩展的训练,包括合成序列、带姿势的RGB-D视频以及未标记的真实世界镜头。
- 联合学习几何和运动:通过从这种异构数据中共同学习几何结构和运动信息,SpatialTrackerV2 能够超越现有的三维跟踪方法,提高30%的表现,并且在达到领先的动态三维重建方法准确性的同时,运行速度提高了50倍。
- 高效率和精确性:由于其高效的算法和架构设计,SpatialTrackerV2 不仅能够提供准确的跟踪结果,而且还能显著减少计算时间,使其非常适合实时应用或需要处理大量数据的任务。
- 广泛的数据适用性:该方法适用于多种类型的数据集,无论是经过精心标注的合成数据还是未经处理的真实世界视频素材,都能够有效地从中提取有用的信息用于三维点的跟踪。
综上所述,SpatialTrackerV2 代表了一种新颖且有效的解决方案,它通过整合多个相关领域的技术来提升三维点跟踪的性能和效率,为这一领域带来了显著的进步。
引言
三维点跟踪旨在从单目视频中恢复任意点的长期三维轨迹。
之前的方法由于其逐场景优化的设计,计算成本较高。SpatialTracker推进了高效的三维点跟踪,采用前馈模型;而最近的工作则探索了不同的架构设计和渲染约束,以实现更高质量的三维跟踪。然而,这些前馈式解决方案受限于训练数据的可扩展性问题,因为需要真实的三维轨迹作为监督信号,这在现实世界的随意拍摄视频中降低了跟踪质量。此外,忽视相机运动、物体运动和场景几何之间的内在关联,会导致误差在各个模块间相互纠缠并累积。
这些局限性激发了我们的核心洞察:
- 对真实三维轨迹的依赖限制了现有前馈模型的可扩展性,凸显出需要能够泛化到多样化且弱监督数据源的设计。
- 缺乏对场景几何、相机运动和物体运动的联合推理,导致误差叠加和性能下降,强调了分离并显式建模这些运动成分的重要性。
为应对这些挑战,我们将三维点跟踪分解为三个独立的组成部分:视频深度、相机运动和物体运动,并将它们集成到一个完全可微分的管道中,支持在异构数据上的可扩展联合训练。
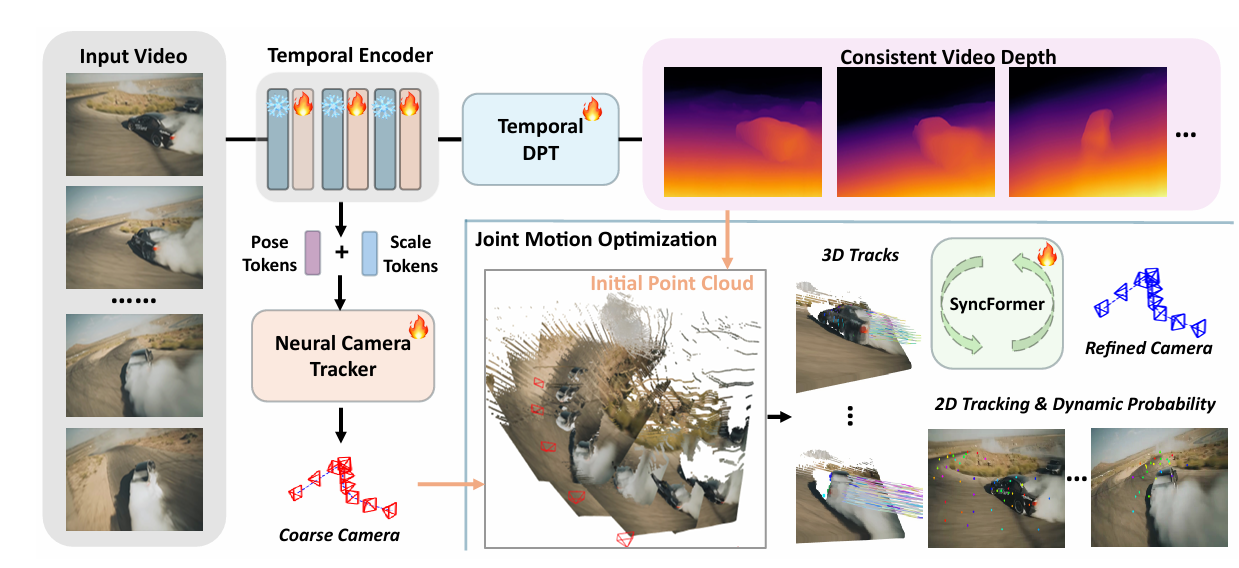
在我们的 SpatialTrackerV2 中,提出了一种前后端架构。前端是一个视频深度估计器和相机姿态初始化模块,改编自典型的单目深度预测框架 [88],并引入基于注意力机制的时间信息编码 [74]。预测的视频深度和相机姿态随后通过一个尺度-偏移估计模块进行融合,确保深度与运动预测之间的一致性。后端包含一个提出的联合运动优化模块(Joint Motion Optimization Module),该模块以视频深度和粗略的相机轨迹作为输入,迭代地估计二维和三维轨迹,以及轨迹级别的动态信息和可见性得分。这使得可以在循环中高效地进行捆绑调整(bundle adjustment),以优化相机姿态。其核心是一个新颖的 SyncFormer 模型,它在两个分支中分别建模二维和三维相关性,并通过多个交叉注意力层连接。这种设计缓解了二维和三维嵌入之间的相互干扰,使模型能够在两个不同的空间中更新表示:图像空间和相机坐标空间。此外,得益于这种双分支设计,捆绑调整可以有效应用于联合优化相机姿态以及二维和三维轨迹。
这种统一且可微分的管道使得在多样化数据集上进行大规模训练成为可能。
对于带有相机姿态的 RGB-D 数据集,我们利用静态点的真实深度和相机姿态的一致性约束来联合训练三维跟踪,而动态点则无缝参与优化过程。对于仅提供相机姿态标注但缺乏深度信息的视频数据集,我们利用相机姿态之间以及二维和三维点跟踪之间的一致性来驱动模型优化 依托该框架,我们成功地在整个流程中跨17个数据集实现了大规模训练。SpatialTrackerV2 在大多数视频深度数据集上优于最先进的动态重建方法 MegaSAM ,并在多个相机姿态基准上达到相当的性能,而其推理速度却快了 50 倍。
创新点
相关工作
2.1. Point tracking
- PIPs [23] 重新审视了最早在 [64] 中提出的二维点跟踪任务,并提出了一种基于深度学习的解决方案。
- TAP-Vid [14] 重新定义了该问题,并引入了一个基准数据集以及一个简单架构 TAP-Net。
- 随后,TAPIR [15] 结合了 TAP-Net 的全局匹配能力和 PIPs 的局部优化优势,进一步提升了性能。
- Co-Tracker [33] 率先采用 Transformer 架构并结合联合注意力机制,实现了对遮挡的有效跟踪;
- 此后,TAPTR [40] 和 LocoTrack [11] 进一步提高了效率,并引入了四维相关体(4D correlation volumes)。
- 最近,BootsTAPIR [16] 和 CoTracker3 [32] 探索了使用无标签数据来提升跟踪性能。
- 首个展示三维点跟踪能力的方法是基于测试时优化的 OmniMotion [75]
- SpatialTracker [86] 提出了首个前馈式三维点跟踪器,通过将二维点跟踪器 [33] 与单目深度估计器提供的深度先验 [3] 相结合实现。
- DELTA [54] 则在效率上进行了改进,实现了稠密的三维跟踪。
- 最近,TAPIP3D [90] 通过将图像特征提升至世界坐标系并在其中进行跟踪,提升了三维跟踪的鲁棒性。
2.2. Depth estimation
不看了,总结这个工作在 DepthAnythingV2 的基础上进行扩展
2.3. Camera estimation - 传统的相机姿态估计方法依赖于图像间的点对应关系,通常使用关键点检测器(如 SIFT、SURF)和最近邻匹配技术,再结合五点法、八点法等几何算法进行求解。捆绑调整(Bundle Adjustment)也常被用于进一步提高精度。
- 近年来,基于神经网络的直接回归方法逐渐兴起,旨在克服稀疏视角或对应点不可靠情况下的局限性。扩散模型如 PoseDiffusion和 RayDiffusion也被探索用于相机姿态估计,虽然精度较高,但推理成本高昂。
- 相比之下,VGGSfM或VGGT中的相机估计模块采用类似于 RAFT的迭代优化范式,在精度和推理效率之间取得了良好平衡,并能同时估计相机的外参和内参。
方法
看不下去了哥们
训练
损失函数:
 微信
微信- 支付宝

