
论文阅读_Sparc3D
Sparc3D: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Sparc3D: Sparse Representation and Construction for High-Resolution 3D Shapes Modeling |
| 作者 | Zhihao Li, Yufei Wang, Heliang Zheng, Yihao Luo, Bihan Wen |
| 第一作者单位 | Nanyang Technological University, Singapore |
| 时间 | 2025 (根据引用文献推断) |
| 发表会议/期刊 | 技术报告 (arXiv) |
方法概览
| 特点 | 描述 |
|---|---|
| 输入 | 原始、非水密的三角网格 (Triangle Mesh) |
| 输出 | 水密的高分辨率网格 (Watertight Mesh) 或用于生成的稀疏潜在表示 |
| 核心目标 | 解决3D生成流水线中两大瓶颈:1) 保持拓扑的高质量水密化重建;2) 模态一致的高效潜在编码。 |
| 所属领域 | 三维形状表示与生成 |
摘要精简
本文提出了 Sparc3D,一个统一的框架,用于解决3D生成流水线中的两大瓶颈。该框架结合了一个稀疏可变形移动立方体表示 Sparcubes 和一个新颖的编码器 Sparconv-VAE。Sparcubes 将原始非水密网格快速转换为 1024³ 分辨率的水密表面,通过稀疏体素采样、洪水填充标记符号、梯度变形优化,30 秒内完成转换(比现有方法快 3 倍);**Sparconv-VAE 是首个模态一致的稀疏卷积 VAE,无全局注意力,实现近无损 3D 重建,避免模态转换导致的细节丢失。**该框架在开放表面闭合、内部结构恢复、复杂几何重建上达到 SOTA,训练与推理成本低,可无缝集成到 latent diffusion pipeline,提升 3D 生成分辨率与质量。
引言与出发点
现有 3D 形状建模方法存在核心瓶颈,推动本文研究:
- 3D 监督 VAE 的缺陷:需水密网格作为监督,原始网格需先采样 UDF 再转 SDF,但 UDF 转 SDF 会使有效分辨率减半,且生成双层网格,仅保留最大连通组件,丢失小而关键的细节;
- 2D 监督 VAE 的不足:无需水密网格,但依赖密集体素投影,分辨率受限,且缺乏 3D 拓扑约束,生成的表面可能开放、内部结构错误,无法满足 3D 打印等应用;
- 模态不匹配问题:现有 VAE 输入(表面点 / 体素特征)与输出(SDF)模态不一致,需复杂全局注意力桥接,增加模型复杂度与误差传播;
- 水密转换效率低:现有方法转换 1024³ 分辨率需 90 秒以上,且易丢失细节。
因此,本文的出发点是:设计稀疏可变形表示(Sparcubes)解决水密转换的效率与细节丢失问题,提出模态一致的稀疏卷积 VAE(Sparconv-VAE)消除模态 gap,无需全局注意力,实现高效、近无损的高分辨率 3D 重建与生成。
创新点
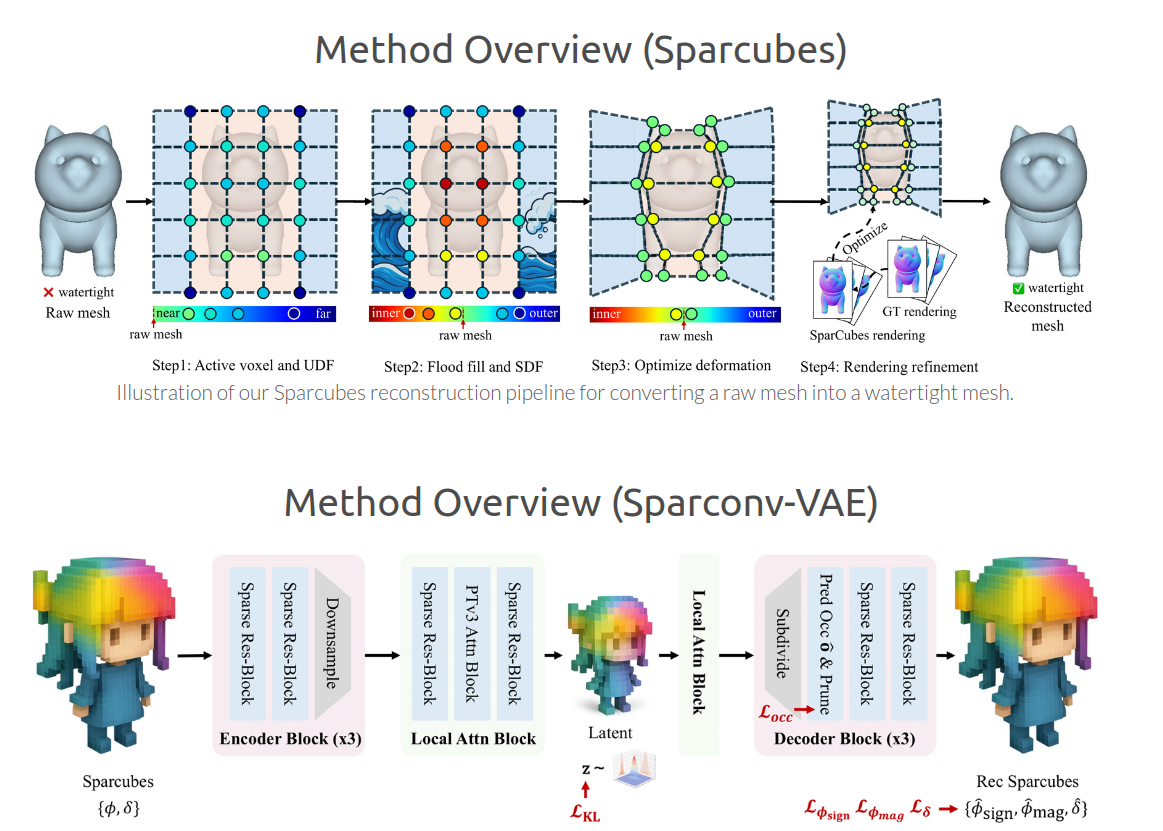
-
Sparcubes:快速、近乎无损的水密化算法
- 稀疏表示:仅对输入表面附近的稀疏体素进行计算和存储,内存高效。
- 高质量重建:通过洪水填充进行粗符号标记,并利用基于梯度的变形优化和可选的基于渲染的细化,精准恢复几何细节和任意拓扑,支持 的高分辨率。
- 速度快:在 分辨率下仅需约30秒,比先前方法快3倍,且不丢失任何小部件。
-
Sparconv-VAE:模态一致的稀疏卷积VAE
- 消除模态差距:编码器和解码器直接处理相同的Sparcubes参数(SDF值和变形向量),无需进行耗时的模态转换(如点云/特征到SDF)。
- 轻量级架构:基于稀疏卷积网络,避免了高消耗的全局注意力机制,显著降低了模型复杂度和训练成本。
- 自剪枝解码器:在解码过程中预测子体素占用率,并动态剪枝,进一步提升效率。
-
无缝集成生成框架
- 学到的稀疏潜在表示可以自然地与现有潜在扩散模型(如TRELLIS)结合,作为其VAE组件,直接提升生成物体的分辨率和细节。
网络架构构成
Sparc3D 框架由两个核心组件构成(如图3所示):
-
Sparcubes (重建模块):
- 输入:原始、非水密的三角网格。
- 处理流程:
- 活跃体素提取与UDF计算:在表面附近窄带内识别稀疏活跃体素,计算其角点顶点的无符号距离。
- 洪水填充进行粗符号标记:从已知外部区域开始填充,为每个点分配内部/外部标签,构建初始符号距离场。
- 基于梯度的变形优化:沿UDF梯度方向微调体素角点位置,使稀疏立方体网格更好地贴合隐式表面。
- (可选)基于渲染的细化:利用可微分渲染,通过深度和法线损失进一步优化几何对齐。
- 输出:一个包含SDF值和变形向量的稀疏立方体网格表示,可直接提取出水密网格。
-
Sparconv-VAE (编码/生成模块):
- 编码器:一系列稀疏残差卷积块,逐步下采样输入特征。在最粗分辨率处,一个轻量级局部注意力模块聚合邻域信息,输出潜在变量 。
- 解码器:与编码器对称,包含自剪枝上采样块。它逐步恢复分辨率,并预测原始的 Sparcubes 参数:SDF值 () 和变形向量 ()。解码过程中会预测子体素占用率并动态剪枝。
- 损失函数:包含多个监督项,共同优化占用率、SDF符号、SDF幅度、变形向量以及潜在分布的KL散度:
特征提取
- 几何特征提取 (Sparcubes):核心是提取稀疏的、表面附近的体素角点及其无符号距离。通过洪水填充获得粗略的符号信息,再通过梯度优化获得几何变形的位移向量。整个过程高度稀疏且高效。
- 潜在特征提取 (Sparconv-VAE):编码器接收 Sparcubes 输出的参数(SDF值和变形向量)作为输入。这些参数本身已经是在空间上对齐的、模态一致的特征。编码器通过稀疏卷积在保持空间结构的同时,逐步抽象和压缩这些局部特征,最终形成紧凑的稀疏潜在特征 。
三维物体生成步骤
Sparc3D 本身主要是一个表示和重建框架,但其 Sparconv-VAE 可以与扩散模型结合用于生成。完整的生成流程如下:
- 训练阶段:
- 使用 Sparcubes 将大量原始训练网格转换为高质量的水密稀疏表示(作为GT)。
- 使用这些数据训练 Sparconv-VAE,学习将稀疏表示编码为潜在变量 ,并能从中解码。
- 在 VAE 的潜在空间 上训练一个扩散模型(如流匹配模型),学习从条件(如图像、文本)生成潜在代码的分布。
- 推理阶段 (单图像到3D):
- 给定输入图像,通过预训练的扩散模型在潜在空间中采样,生成一个与图像对应的潜在代码 。
- 将 输入 Sparconv-VAE 的解码器,解码出对应的 Sparcubes 参数(预测的SDF值和变形向量)。
- 从这个预测的稀疏表示中,通过移动立方体算法提取出最终的水密三角网格。
训练与测试数据及对比结果
- 训练数据:从 Objaverse 和 Objaverse-XL 中选取的 50万 个高质量3D资产。
- 测试数据:
- ABO 和 Objaverse 数据集中最具挑战性的样本(包含遮挡部件、复杂细节、开放表面)。
- 独立收集的 “Wild” 数据集,包含来自网络的多组件物体。
- 对比方法与结果:
- 水密化重建 (Sparcubes):在 Chamfer距离 (CD)、法向一致性 (ANC)、F1分数上,均显著优于 Dora-wt 等先前方法。其
wt-512的结果甚至优于先前方法的wt-1024结果。方法 ABO (CD↓) Objaverse (CD↓) Wild (CD↓) Dora-wt-1024 1.07 4.35 63.7 Ours-wt-512 1.01 3.09 0.47 Ours-wt-1024 1.00 3.01 0.46 - VAE重建 (Sparconv-VAE):在相同测试集上,其重建质量(CD, ANC, F1)全面优于 TRELLIS, Craftsman, Dora, XCubes 等SOTA VAE。
- 生成质量:将 Sparconv-VAE 与 TRELLIS 的扩散模型结合微调后,在相同架构和规模下,生成的3D形状在细节和保真度上明显优于原始 TRELLIS(如图6所示)。
- 水密化重建 (Sparcubes):在 Chamfer距离 (CD)、法向一致性 (ANC)、F1分数上,均显著优于 Dora-wt 等先前方法。其
消融实验分析
- 转换成本:Sparcubes 算法显著更快。在 分辨率下仅需约15秒,在 下约30秒,相比先前方法有 3倍加速。此外,由于模态一致,VAE训练时无需额外的SDF重采样步骤,又节省了20-70秒。
- 训练成本:得益于模态一致和轻量架构,Sparconv-VAE 的训练在 2天内 收敛,比 TRELLIS、Dora 等需要约7天的方法快 约4倍。
- 2D渲染监督的有效性:实验表明,在 Sparconv-VAE 的训练中加入2D渲染损失(掩膜、深度、法线)带来的提升可以忽略不计。这与 Dora 的结论一致,表明足够密集的3D监督本身已包含必要信息。
其他关键技术点
- 孔洞填充:为解决解码器预测的占用率可能不完美而产生的小孔洞,提出了一种基于边界边检测和“耳切”算法的后处理步骤。通过计算顶点处的几何得分 来识别并填充最尖锐的凸“耳朵”,从而封闭所有小边界环。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 This is a 部落格 of outbreak_sen!
 微信
微信- 支付宝

