
论文阅读_ROMA
RoMa: Robust Dense Feature Matching
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | RoMa: Robust Dense Feature Matching |
| 作者 | Johan Edstedt1 Qiyu Sun2 Georg B¨okman3 M˚arten Wadenb¨ack1 Michael Felsberg1 |
| 作者单位 | Link¨oping University, 2East China University of Science and Technology华东理工大学, 3Chalmers University of Technology |
| 时间 | 2023 |
| 发表会议/期刊 | cvpr2024 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 两帧图像 |
| 输出 | 图一中每个像素移动到图二的位置,以及置信度 |
| 所属领域 | DenseMatching |
背景
创新点
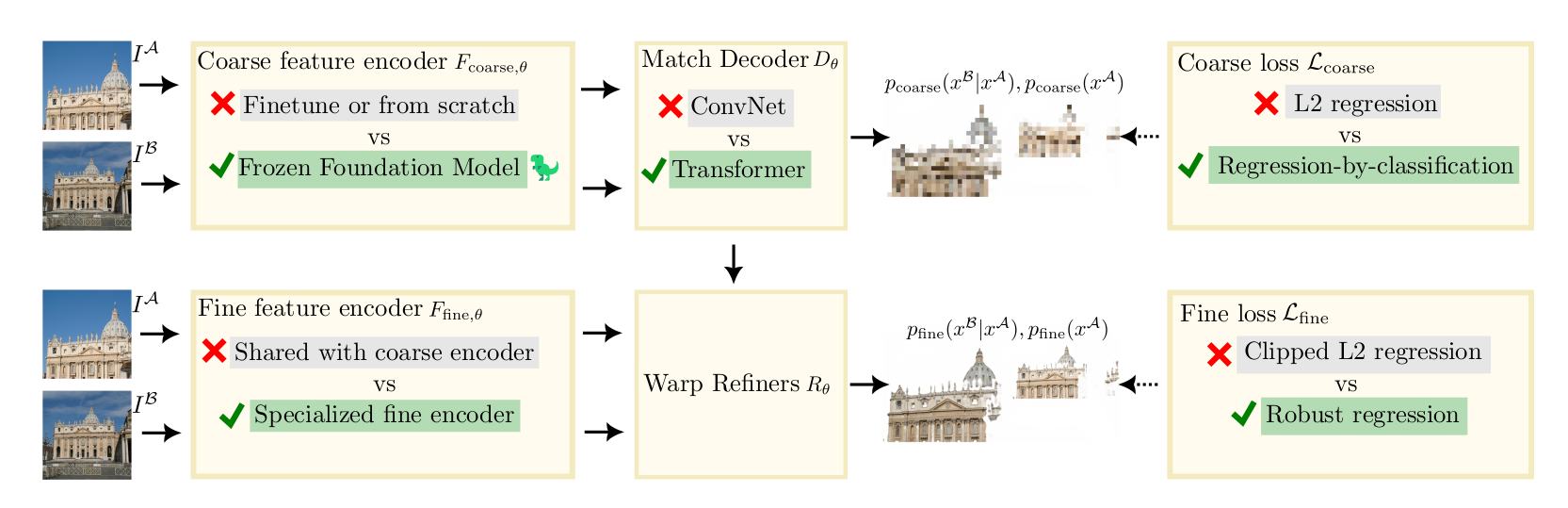
- 提出了 RoMa,这是一种用于密集特征匹配的模型,它对比例、照明、视点和纹理的各种具有挑战性的现实世界变化具有鲁棒性。
网络架构
摘要
特征匹配是一项重要的计算机视觉任务,涉及估计 3D 场景的两个图像之间的对应关系,而密集方法估计所有这些对应关系。目的是学习一个稳健的模型,即能够在具有挑战性的现实世界变化下匹配的模型。在这项工作中,我们提出了这样一个模型,**利用基础模型 DINOv2 中的冻结预训练特征。尽管这些特征比从头开始训练的局部特征要稳健得多,但它们本质上是粗略的。因此,我们将它们与专门的 ConvNet 精细特征相结合,创建一个可精确定位的特征金字塔。为了进一步提高鲁棒性,我们提出了一种定制的 transformer 匹配解码器,用于预测锚点概率,使其能够表达多模态。最后,我们提出了一种通过分类回归和随后的稳健回归来改进的损失公式。**我们进行了一套全面的实验,表明我们的方法 RoMa 取得了显着的收益,树立了新的最先进技术。特别是,我们在极具挑战性的 WxBS 基准测试上实现了 36% 的改进。
引言
-
特征匹配是从两个图像中估计对应于同一 3D 点的像素对的计算机视觉任务。它对于 3D 重建[43]和视觉定位[40]等下游任务至关重要。密集特征匹配方法[17,36,49,52]旨在找到图像之间所有匹配的像素对。这些密集方法采用从粗到细的方法,首先在粗略水平上预测匹配,然后以更精细的分辨率依次细化。以前的方法通常使用 3D 监督来学习粗略特征[17,41,44,52]。虽然这允许专门的粗略特征,但它也有缺点。特别是,由于收集真实世界的 3D 数据集成本高昂,可用数据量有限,这意味着模型存在过度拟合训练集的风险。这反过来又将模型的鲁棒性限制在与训练期间看到的场景显着不同的场景。限制过度拟合的一种众所周知的方法是冻结所使用的主链[29,47,54]。然而,使用在 ImageNet 分类上预训练的冻结主干,开箱即用的性能不足以进行特征匹配(见表 1 中的实验)。冻结预训练特征最近一个有希望的方向是使用掩蔽图像建模(MIM)进行大规模自监督预训练[24,37,56,62]。这些方法,包括 DINOv2 [60]比分类预训练[60]更好地保留局部信息,并且已被证明可以生成能够很好地推广到密集视觉任务的特征。然而,由于缺乏精细特征,DINOv2 在密集特征匹配中的应用仍然很复杂,而精细特征需要细化。
我们通过利用冻结的 DINOv2 编码器来处理粗略特征,同时使用建议的专用 ConvNet 编码器来处理精细特征,从而克服了这个问题。这样做的好处是结合了 DINOv2 出色的一般特征,同时具有高精度的精细特征。我们发现,专门用于粗略匹配或细化的特征明显优于为这两个任务共同训练的特征。这些贡献在第 3.2 节中进行了更详细的介绍。我们还提出了一种 Transformer 匹配解码器,它在提高基线性能的同时,当用于预测锚点概率而不是与 DINOv2 粗编码器结合使用时,可以特别提高性能。第 3.3 节进一步阐述了这一贡献。
最后,我们研究了如何最好地训练密集特征匹配器。最近的 SotA 密集方法,如 DKM [17],使用非鲁棒回归损失进行粗匹配和细化。我们认为这不是最佳的,因为粗略阶段的匹配分布通常是多模态的,而条件细化更有可能是单峰的。因此需要不同的培训方法我们从第 3.4 节中的理论框架中激发了这一点。我们的框架促使将粗损和精细损失划分为单独的范式,使用粗略特征对全局匹配进行分类回归,使用精细特征进行鲁棒回归。我们称之为 RoMa 的完整方法对于极具挑战性的现实案例具有鲁棒性。
综上所述,我们的贡献如下:
(a)我们整合了基础模型 DINOv2 [37]中的冻结特征,以实现密集特征匹配。我们将 DINOv2 的粗略特征与 ConvNet 的专用精细特征相结合,生成一个精确定位但稳健的特征金字塔。参见第 3.2 节。
(b)我们提出了一种基于 Transformer 的匹配解码器,它预测锚点概率而不是坐标。参见第 3.3 节。
(c) 我们改进损失表述。特别是,我们对粗略的全局匹配使用按分类的回归损失,而对细化阶段使用稳健的回归损失,这两者都是我们从理论分析中获得的。参见第 3.4 节。
(d) 我们对我们的贡献进行了广泛的消融研究,并在一组多样化和有竞争力的基准上进行了 SotA 实验,发现 RoMa 树立了新的最先进技术。特别是,在困难的 WxBS 基准测试上实现了 36% 的收益。见第 4 节。
相关工作
-
Sparse → Detector Free → Dense Matching
- 传统上,特征匹配是通过关键点检测和描述,然后匹配描述来实现的[4,14,33,39,41,53]。最近,无检测器方法[7,12,44,46]用粗略尺度的密集匹配取代了关键点检测,然后是相互最近邻提取,然后是细化。密集方法[17、34、36、50、51、63]而是估计一个密集的扭曲,旨在估计每个可匹配的像素对。
-
自监督视觉模型
- 受语言 Transformers[15]的启发,在大量数据上进行预训练的基础模型[8]最近在通过自监督学习学习各种视觉模型的通用特征方面显示出巨大的潜力。Caron 等[11]观察到,自监督 ViT 特征比监督模型捕获更多独特的信息,这通过无标记自蒸馏得到了证明。iBOT [62]在自蒸馏框架中探索 MIM,以开发语义丰富的可视化分词器,从而产生在各种密集的下游任务中有效的强大功能。DINOv2 [37]表明,自监督方法在经过足够数据集的训练后,无需微调即可产生适用于各种图像分布和任务的通用视觉特征。
-
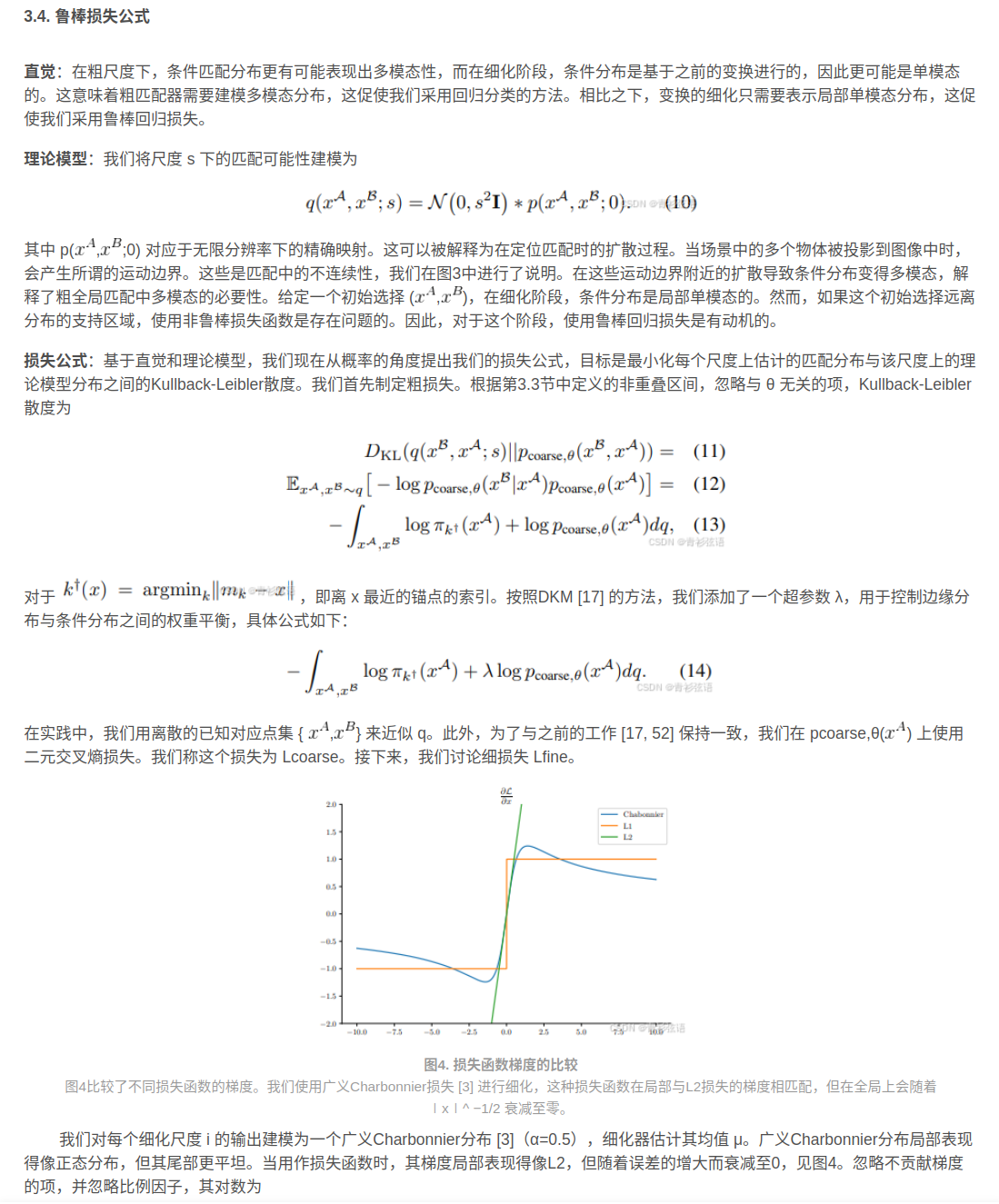
稳健损失公式
- Robust Regression Losses: 鲁棒损失函数提供内限分布(通常高度集中)和异常分布(宽而平坦)之间的连续转换。例如,鲁棒损耗已被用作光流的正则化器[5,6]、鲁棒平滑[18]和损失函数[3,32]。
- Regression by Classification:按分类的回归[48,57,58]涉及将回归问题转换为分类,例如,分箱。这对于运动中具有尖锐边界的回归问题特别有用,例如立体视差[19,22]。Germain 等[20]使用分类回归损失进行绝对位姿回归。
- Classification then Regression: Li 等[27]和 Budvytis 等[9]提出了用于视觉定位的分层分类回归框架。Sun 等[44]优化了互最近邻的模型对数似然,然后进行了基于 L2 回归的细化以进行特征匹配。
方法
从第 3.1 节中密集特征匹配的初步和符号开始。然后,我们将 DINOv2作为粗编码器,以及在第 3.2 节中专门的精细特征。我们在第 3.3 节中介绍了我们提出的 Transformer 匹配解码器。最后,我们在第 3.4 节中提出的损失表述。
3.1 密集特征匹配的预备知识


3.2鲁棒且可精准定位的特征

3.3 Transformer匹配解码器

损失函数
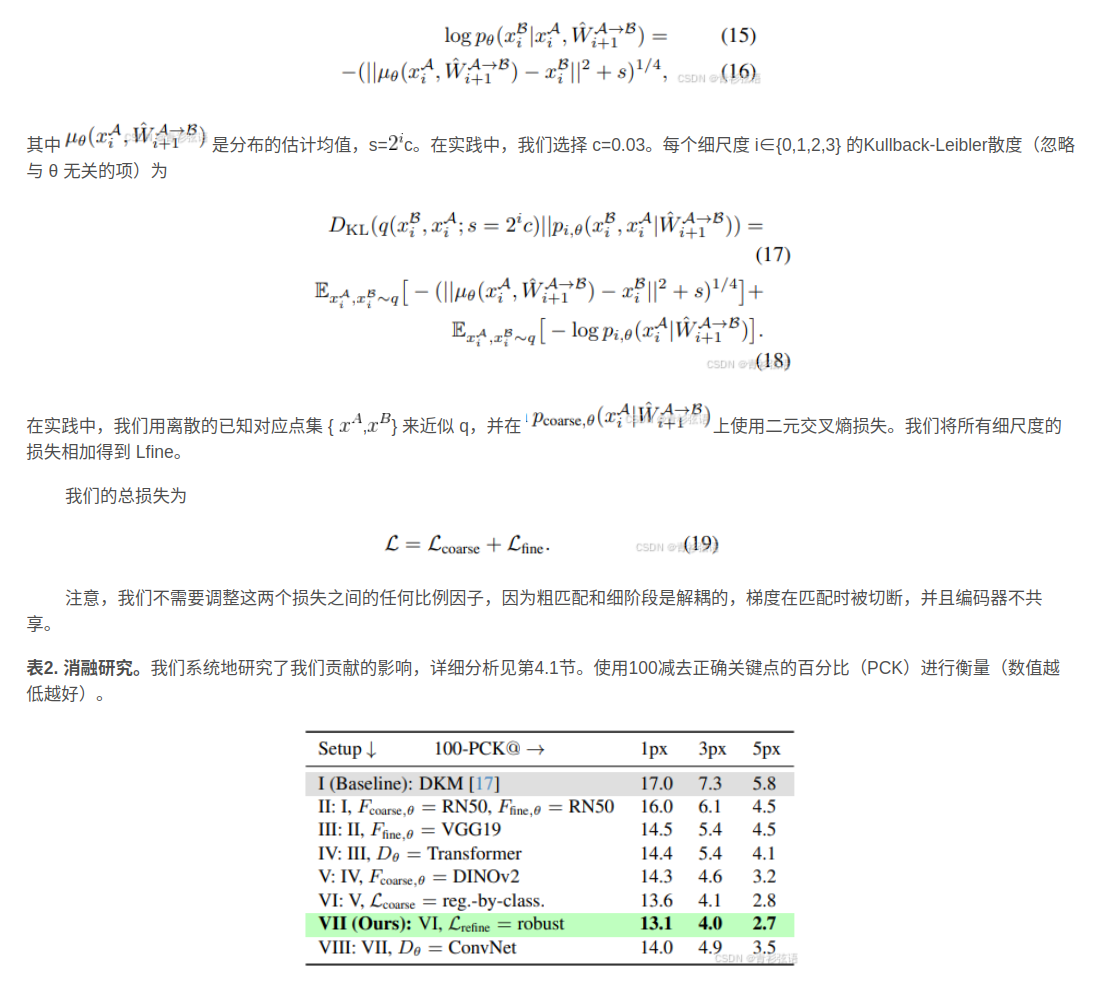
实现
发现使用标准高斯噪声,即 N(0,I),如 DDPM [23],将引入太强的噪声,无法进行细化。因此,我们将阶段 m 的高斯噪声设置为 N(0,σI)来控制噪声尺度。具体来说,当在 DTU 上训练时,我们将第 2 阶段的细化设置为 σ= 0.5,在第 3 阶段的细化设置为 σ= 0.1。【
 微信
微信- 支付宝

