
论文阅读_R-MVSNet
Recurrent MVSNet(R-MVSNet)
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Recurrent MVSNet for High-resolution Multi-view Stereo Depth Inference |
| 作者 | Yao Yao、Zixin Luo、Shiwei Li、Tianwei Shen、Tian Fang、Long Quan |
| 作者单位 | The Hong Kong University of Science and Technology(香港科技大学) |
| 时间 | 2019 |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 多视角 |
| 输出 | 参考视角深度图 |
| 所属领域 | MVS |
1. 摘要精简
提出一种基于循环神经网络的可扩展多视图立体匹配(MVS)框架 R-MVSNet,解决传统学习型 MVS 方法中 3D CNN 代价体正则化内存消耗巨大的问题。该方法摒弃一次性正则化整个 3D 代价体的模式,通过卷积门控循环单元(GRU)沿深度方向序贯正则化 2D 代价图,将内存需求从模型分辨率的立方级降至平方级,使高分辨率和大范围场景重建成为可能。在 DTU、Tanks and Temples、ETH3D 等基准数据集上,R-MVSNet 性能达到或超越 SOTA 水平,且是首个能处理 Tanks and Temples 高级集的学习型 MVS 方法,源代码已开源(https://github.com/YoYo000/MVSNet)。
2. 研究动机与出发点
现有学习型 MVS 方法的核心瓶颈是可扩展性:3D CNN 正则化 3D 代价体时,内存消耗随模型分辨率立方增长,难以应用于高分辨率(如>5123体素)或宽深度范围场景。此前的优化方案(如 OctNet 的八叉树结构、SurfaceNet 的分治策略)仍受限于重建规模或存在全局上下文丢失、处理速度慢等问题。因此,本文提出以循环神经网络为核心的序贯正则化策略,通过沿深度方向逐步处理代价图,在保证正则化效果的同时大幅降低内存开销,实现 MVS 的高可扩展性。
3. 创新点
- 提出基于卷积 GRU 的序贯代价体正则化,替代传统 3D CNN,内存需求从H×W×D降至H×W,突破高分辨率 / 大范围重建的内存限制;
- 采用逆深度采样策略,高效适配宽深度范围场景,避免均匀采样在远深度区域精度不足的问题;
- 设计变分深度图细化算法,通过最小化多视图光度一致性和光滑项,解决 winner-take-all 策略导致的亚像素精度缺失和阶梯效应;
- 可扩展性极强,是首个能稳定处理 Tanks and Temples 高级集(复杂大型户外场景)的学习型 MVS 方法,内存利用率为 MVSNet 的 4.7-8.1 倍;
- 训练时同时采用正向(dmin→dmax)和反向(dmax→dmin)GRU 正则化,避免深度顺序偏见影响模型性能。
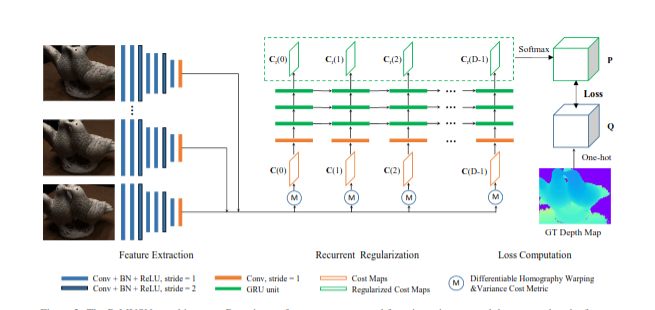
4. 网络架构
网络基于 MVSNet 扩展,整体分为五大模块,流程为 “特征提取→代价体构建→循环正则化→概率体积生成→后处理”:
- 特征提取模块:2D CNN 网络提取多视图图像的深层特征;
- 代价体构建模块:通过可微单应性变换 warp 多视图特征,并用方差代价 metric 聚合为代价体(D 个 2D 代价图沿深度方向拼接);
- 循环正则化模块:3 层堆叠的卷积 GRU,沿深度方向序贯处理每个 2D 代价图,融合空间和深度方向的上下文信息;
- 概率体积生成模块:正则化后的代价图经 softmax 生成概率体积,用于训练损失计算;
- 后处理模块:包括变分深度图细化、光度滤波、几何滤波、深度融合,最终生成高精度 3D 点云。
5. 特征提取
采用 7 层 2D CNN 构建多尺度图像特征,所有输入视图共享同一特征提取网络:
- 前 6 层为 ConvBR 结构(卷积 + 批归一化 + ReLU):前 2 层核大小 3×3、步长 1,输出 8 通道;第 3 层核大小 5×5、步长 2,输出 16 通道;第 4-5 层核大小 3×3、步长 1,输出 16 通道;第 6 层核大小 5×5、步长 2,输出 32 通道;
- 最后 1 层为纯卷积层(核大小 3×3、步长 1),输出 32 通道特征图;
- 最终特征图尺寸为输入图像的 1/4(经两次步长 2 下采样),为后续代价体构建提供紧凑且富含语义的特征表示。
6. 代价体构建
- 特征 warp:将所有源视图的 32 通道特征图,通过可微单应性变换(Differentiable Homography Warping)映射到参考相机视锥体的正平行平面,形成 N 个 3D 特征体Vi(d)(d为深度维度);
- 多视图特征聚合:采用方差代价 metric 处理任意数量的视图输入,将 N 个特征体映射为单一代价体C,每个深度d对应一张 2D 代价图C(d),方差计算逻辑与 MVSNet 一致,确保多视图特征的一致性聚合;$$ \mathbf{C} = \text{Variance}({\mathbf{V}i}{i=1}^N) $$
- 代价体形态:代价体可视为D张尺寸为H/4×W/4×32的 2D 代价图沿深度方向拼接而成,为后续序贯正则化奠定基础。
7. 代价体正则化
核心为 3 层堆叠的卷积 GRU,沿深度方向序贯处理每个 2D 代价图C(d),融合当前代价图信息与历史正则化结果:
其中更新门和重置门计算为:
层间配置:第 1 层 GRU 将 32 通道代价图映射为 16 通道,第 2 层降至 4 通道,第 3 层输出 1 通道正则化代价图Cr(d);
8. 深度图生成(变分深度图优化)
- 初始深度估计:测试时对正则化后的代价图序列采用 winner-take-all 策略,选择概率最大的深度值作为对应像素的初始深度D1;通过赢家通吃选择从正则化代价图中检索深度图$$dinitial§=argmax_dP(d,p)$$由于使用离散深度分类,只能达到像素级精度
- 变分优化:为提升亚像素精度,在小深度范围内最小化总重投影误差,基于多视图光度一致性在小的深度范围内细化深度图:$$ E^i(\mathbf{p}) = E^i_{photo}(\mathbf{p}) + E^i_{smooth}(\mathbf{p}) $$
- 后处理优化:
- 光度滤波:过滤概率体积中置信度(对应深度的概率值)低于 0.3 的像素;
- 几何滤波:保留至少 3 个视图可见且深度一致的像素;
- 深度融合:采用基于可见性的融合和均值融合,生成最终 3D 点云。
单独具体讲解变分深度图优化
优化目标函数
总能量函数定义为所有视图和所有像素的加权和:
其中每个像素的能量函数包含两个部分:
-
光度一致性项$$ E^i_{photo}(\mathbf{p}) = \mathcal{C}(\mathbf{I}1(\mathbf{p}), \mathbf{I}{i\to 1}(\mathbf{p})) $$
-
平滑性约束项$$ E^i_{smooth}(\mathbf{p}) = \sum_{\mathbf{p}’\in\mathcal{N}(\mathbf{p})} \mathcal{S}(\mathbf{p},\mathbf{p}’) $$
如何计算:
- 图像重投影,将源图像 通过当前深度图 投影到参考视图:$$ \mathbf{I}_{i\to 1} = \text{warp}(\mathbf{I}_i, \mathbf{D}_1, \Pi_1, \Pi_i) $$
其中:, 分别是参考相机和第i个源相机的投影矩阵,使用双线性插值保证可微性
- 相似度度量,使用零均值归一化互相关(ZNCC)计算光度一致性:
ZNCC对光照变化具有鲁棒性,计算公式为:
- 平滑约束,使用双边权重保持边缘:
双边权重计算:
梯度计算
光度项梯度推导对于像素 ,其对应的3D点为:
在源图像中的投影为:
光度项梯度为:
其中 是投影矩阵 的雅可比矩阵。
平滑项梯度推导
迭代优化过程
梯度下降更新
步长衰减策略
固定迭代次数对所有实验固定迭代20次,每次迭代更新深度图和所有重投影图像
9. 损失函数
将深度预测视为多分类问题,采用交叉熵损失,而非传统回归任务的L1损失:
其中:
- P为图像空间坐标,P(i,p)为概率体积中(i,p)位置的概率值(softmax 输出);
- Q为地面真值(GT)的二进制占据体积,通过对 GT 深度图进行独热编码生成,Q(i,p)为对应位置的标签值;
- 采用逆深度采样适配宽深度范围,通过后续变分细化弥补分类任务的离散化深度缺陷。
10. 测试数据集
- DTU数据集:室内物体扫描,用于主要评估
- Tanks and Temples:复杂室外场景,包括中级和高级集
- ETH3D:包含低分辨率和高分辨率场景
11. 消融实验测试组件
(1)网络架构组件
在 DTU 验证集上测试不同正则化和特征提取组合的效果:
- 2D CNNs + 3D CNNs:用 MVSNet 的 3D CNN 替代 GRU 正则化(基准);
- 2D CNNs + GRU:R-MVSNet 核心配置;
- 2D CNNs + Spatial:用 3 层 32 通道 2D CNN 实现简单空间正则化;
- 2D CNNs + Winner-Take-All:用 1 层 1 通道 2D CNN 直接映射代价图,无时序聚合;
- ZNCC + Winner-Take-All:传统平面扫描策略,用 ZNCC 替代学习型特征和代价 metric。
(2)后处理组件
测试后处理各步骤对最终重建质量的影响(DTU 评估集):
- 变分细化(Ref.):有无该步骤对亚像素精度的影响;
- 光度滤波(Pho.):基于概率图的低置信度像素过滤;
- 几何滤波(Geo.):多视图深度一致性校验;
- 深度融合(Fus.):多视图深度图融合策略。

额外创新点补充
- 内存利用率优势显著:在相同重建规模下,R-MVSNet 的内存利用率(单位内存处理的数据量)是 MVSNet 的 4.7-8.1 倍,可在 11GB GPU 上处理 3072×2048 分辨率图像;
- 深度采样自适应调整:通过逆深度采样公式d(i)=((dmin1−dmax1)D−1i+dmax1)−1,自适应平衡不同深度区域的采样密度,确保近 / 远深度均有足够精度;
- 泛化性强:仅在 DTU 数据集上训练,无需微调即可在 Tanks and Temples、ETH3D 上取得优异性能,适配室内外多种场景。
一、为什么 RMVSNet 要用独热编码的 Loss
RMVSNet 采用独热编码(One-hot Encoding)构建标签并结合交叉熵损失,核心是适配其逆深度采样策略与循环正则化的多分类任务定位,解决传统回归型 Loss 在宽深度范围场景的局限性,具体原因如下:
适配逆深度采样的离散深度假设
RMVSNet 为处理宽深度范围场景(如 Tanks and Temples 高级集),采用逆深度采样生成离散的深度假设,即深度样本在逆深度空间均匀分布,而非原始深度空间。这种采样方式导致深度假设是离散的 “类别”(每个深度假设对应一个类别),而非连续的回归目标。此时用独热编码将地面真值(GT)深度图转换为二进制占据体积 Q(仅 GT 对应深度类别为 1,其余为 0),能自然匹配 “离散类别标签” 的形式,使交叉熵损失可直接计算预测概率与 GT 类别的差异(文档 2-45、2-46)。
规避传统回归型 Loss 的适配问题
传统 MVS 方法(如 MVSNet)用 L1 损失或 soft argmin(回归),需深度样本在原始深度空间均匀分布,且依赖 “期望计算” 拟合连续深度。但 RMVSNet 的逆深度采样打破了原始深度空间的均匀性,若强行用回归型 Loss:
- 远深度区域的深度样本间隔更大,回归误差易被放大;
- soft argmin 需计算整个概率体积的加权期望,与 RMVSNet 序贯处理代价图的 “低内存” 核心目标冲突(会增加计算与内存开销)。
- 而将深度预测视为 “从 D个离散深度类别中选最优” 的多分类问题,用独热编码标签 + 交叉熵损失,能完全适配逆深度采样的离散特性,且计算更高效(文档 2-46、2-47)。
强化深度类别的概率区分度
独热编码标签使交叉熵损失专注于 “当前深度假设是否为 GT 类别”,迫使网络学习更清晰的概率分布(GT 类别概率趋近于 1,其余趋近于 0)。这种强监督信号有助于循环正则化过程中,GRU 更精准地聚合深度方向的上下文信息,减少模糊预测(文档 2-37、2-41)。
二、为什么初始深度图用 argmax 而非soft argmin
RMVSNet 测试阶段用 argmax(Winner-Take-All) 生成初始深度图,核心是平衡效率、内存开销与后续精度补偿,而非不合理选择,具体原因如下:
适配测试阶段的序贯处理与低内存目标
RMVSNet 的核心优势是沿深度方向序贯正则化代价图,使内存需求从 H×W×D 降至 H×W。测试时,若用 soft argmin(本质是计算概率体积的加权期望,公式为 ∑d=1Dd⋅P(d)),需先存储完整的概率体积 P(H/4×W/4×D 维度),再遍历所有深度计算期望 —— 这会打破 “序贯处理” 的低内存优势,增加内存与计算耗时。
而 argmax 仅需在序贯处理每个深度代价图时,实时记录当前最大概率对应的深度,无需存储完整概率体积,完全契合 RMVSNet“高效、低内存” 的设计目标(文档 2-47、2-54)。
后续变分细化弥补 argmax 的精度缺陷
argmax 的核心问题是 “亚像素精度缺失”(仅选择离散深度假设中的一个,忽略相邻深度的概率信息),但 RMVSNet 设计了变分深度图细化模块(文档 2-54 至 2-60):在初始 argmax 深度图基础上,通过最小化多视图光度一致性误差(ZNCC 度量)和深度光滑项,在小深度范围内微调深度值,最终实现亚像素精度。
这意味着 “初始 argmax 深度图” 仅需提供 “大致正确的深度范围”,后续细化会弥补其精度不足,无需在初始阶段用 soft argmin 增加计算成本(文档 2-47、2-60)。
 微信
微信- 支付宝

