
论文阅读_PSGN
PSGN: A Point Set Generation Network for 3D Object Reconstruction from a Single Image
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | A Point Set Generation Network for 3D Object Reconstruction from a Single Image |
| 作者 | Haoqiang Fan, Hao Su, Leonidas Guibas |
| 作者单位 | 清华大学 (Haoqiang Fan),斯坦福大学 (Hao Su, Leonidas Guibas) |
| 时间 | 2017 |
| 发表会议/期刊 | CVPR |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 单张RGB图像(或RGB-D图像) |
| 输出 | 无序三维点云(如1024个点) |
| 所属领域 | 单视图三维物体重建 |
1. 摘要精简
本文提出了一种用于三维物体重建的点云生成网络(PSGN),可以直接从单张图像生成点云坐标。与使用体素网格或多视角图像等规则表示的现有方法不同,点云表示保留了三维形状在几何变换下的自然不变性,且避免了其他问题。本文的网络输出形式为点云,这带来了一个独特问题:输入图像对应的真实形状可能存在歧义。针对这种非常规输出形式和真实数据的固有歧义性,本文设计了新颖且有效的网络架构、损失函数和学习范式。最终方案是一个条件形状采样器,能够从一个输入图像预测多个合理的三维点云。实验表明,该系统不仅在单图像三维重建基准上优于当时的最先进方法,而且在三维形状补全任务上表现出强大性能,并具有生成多个合理预测的潜力。

2. 研究动机与出发点
引言指出,将深度学习成功应用于三维领域面临根本性的表示问题。现有的深度网络架构非常适合处理规则采样的数据(如图像、音频),但常见的三维几何表示(如网格或点云)是不规则结构,难以直接套用现有架构。因此,大多数工作转而使用体素网格或多视角图像。然而,这些表示在采样分辨率和网络效率之间存在权衡,并且量化伪影会掩盖数据在刚体运动下的自然不变性。
本文探索基于点云表示的三维几何生成网络。点云表示虽然不如CAD模型或网格高效,但优势明显:它是一个简单、统一的结构,更容易学习(无需编码基元或组合连接性);在几何变换和形变时操作简单(无需更新连接性)。因此,本文目标是从单张图像重建物体的完整三维形状,输出为点云,如图1所示。
本文还指出,从单张图像恢复三维结构是一个病态问题,存在真实形状的歧义性(同一图像可能对应多个同样合理的三维形状)。这与经典的回归/分类问题不同,后者每个训练样本有唯一的真实标注。因此,需要设计能够处理这种歧义性的方法。
3. 创新点与相关工作对比
创新点总结:
- 首次研究基于深度学习的点集生成问题,开辟了新方向。
- 提出新颖的网络架构、损失函数和学习范式,专门用于点云生成和处理真实形状歧义。
- 将单视图三维重建任务构建为条件采样器,能够为单张输入图像生成多个合理的三维点云预测。
- 在单视图重建任务上显著超越当时最先进方法,并在形状补全任务上表现强劲。
与相关工作对比:
- 与早期ShapeFromX方法[13,1]及基于学习的方法[12,21]对比:指出这些方法要么对形状或光照做出强假设,要么只能处理简单几何结构,无法从单张图像鲁棒地重建完整、高质量的形状,缺乏更强的形状先验。
- 与基于CAD模型库的方法[22,14]对比:这些方法需要高质量的图像-形状对应,而这本身就是一个具有挑战性的病态问题。
- 与最相关的3D-R2N2[5]对比:
- 输出表示不同:3D-R2N2预测体素体积,而PSGN预测点云。实验证明点集为神经网络形成了更优的形状空间,预测的形状更完整、自然。
- 处理歧义性的能力:PSGN允许为单张输入图像生成多个重建候选,反映了单张图像无法完全确定三维形状的事实。3D-R2N2是确定性输出。
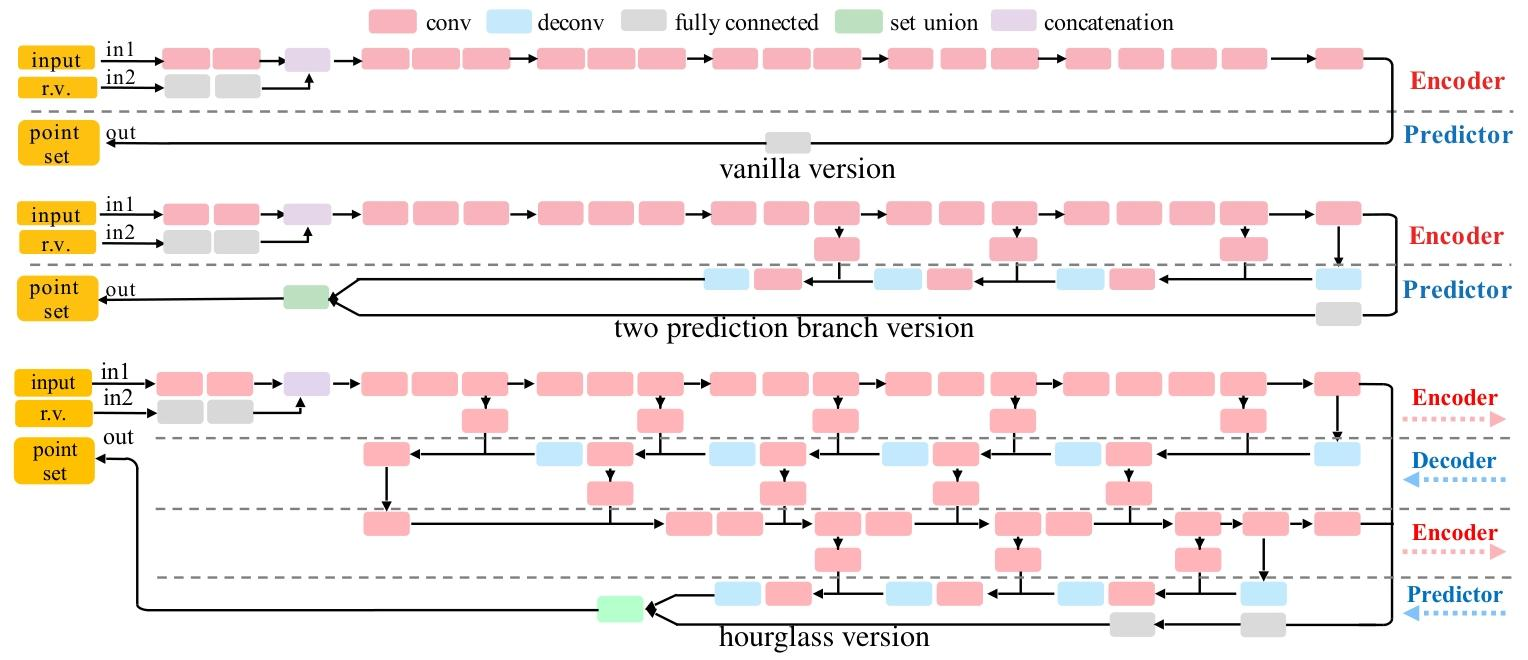
4. 网络架构构成
网络整体是一个条件生成网络,其目标是学习一个从输入图像 和随机噪声 到点云 的映射:
其中 是网络参数, 是用于引入变化的随机变量(服从标准正态分布)。
网络结构(如图2所示)包含一个编码器(Encoder) 和一个预测器(Predictor):
- 编码器:由卷积层和ReLU层组成,将输入图像 和随机向量 映射到一个嵌入空间。
- 预测器:生成一个 的矩阵 ,每一行代表一个点的三维坐标。预测器设计有不同版本:
- 基础版本:仅使用全连接层预测所有点坐标。
- 改进版本(核心设计):包含两个并行的分支:
- 全连接(fc)分支:预测 个点(如256个)。灵活性高,擅长捕捉复杂结构。
- 反卷积(deconv)分支:预测一个 的三通道“图像”,每个像素的三个值对应一个点的坐标,从而生成 个点(如768个)。通过权重共享和空间连续性,更擅长捕捉大而平滑的表面,参数更高效。
- 沙漏(Hourglass)版本:在改进版本基础上引入堆叠的编码-解码结构,以混合全局和局部信息,获得更强的表示能力。
两个分支的预测结果合并,形成最终的点云。网络中还加入了跳跃连接以促进信息流动。
5. 特征提取方法
特征提取由编码器完成。编码器是一个标准的卷积神经网络(CNN),由多个卷积层和ReLU激活层堆叠而成。它将输入图像(尺寸为)编码成一个低维的特征向量。同时,一个随机向量 被并入编码过程,以使网络能够产生多样化的输出。这个融合了图像信息和随机噪声的特征向量,随后被送入预测器进行点云坐标的生成。
6. 三维生成步骤详解
网络以端到端的方式直接从图像生成点云:
- 编码:输入图像 和随机向量 通过编码器CNN,被转换成一个融合了内容信息(来自图像) 和变化信息(来自噪声) 的潜在特征向量。
- 并行预测:该特征向量被同时送入两个预测分支:
- 在反卷积分支,特征通过反卷积层上采样,生成一个具有空间结构的“点图”,其中的点自然具有局部连续性。
- 在全连接分支,特征通过全连接层直接映射为一组点的坐标,这组点之间没有预设的空间关系,灵活性更强。
- 合并与输出:将两个分支预测出的点集(例如,deconv分支的768个点 + fc分支的256个点)合并,形成一个包含 (如1024) 个点的无序点云 。每个点由其三维坐标 定义。
- 多样化生成:通过在输入中引入不同的随机噪声 ,网络可以在测试时为同一张图像生成多个不同的、但都合理的点云样本,从而捕捉三维重建中固有的歧义性。
7. 数据集、对比方法与结果
训练数据集:
- 合成数据:使用ShapeNet[4]数据集的一个子集(约220K个模型,覆盖2000个类别)。对每个CAD模型进行归一化,并使用Blinn-Phong着色模型和随机环境贴图渲染生成二维图像。
测试数据集与对比实验:
-
单视图RGB图像重建:
- 对比方法:3D-R2N2[5](当时基于深度学习的SOTA)。
- 测试数据:使用与3D-R2N2论文相同的数据集(ShapeNet子集,13个类别)。
- 评估指标:CD、EMD和IoU。为了公平比较,将3D-R2N2的体素输出和PSGN的点云输出相互转换后计算指标。
- 结果:
- 如图7和表1所示,PSGN在单视图设置下,在全部13个类别上的平均IoU (0.640) 显著高于 3D-R2N2单视图的结果 (0.560),甚至优于3D-R2N2使用5个视图的结果 (0.631)。
- 在CD和EMD指标上,PSGN也全面领先。
- 可视化对比(图6):PSGN能更好地保留物体的薄结构(如家具的腿),而3D-R2N2的体素表示和体素级损失函数往往会惩罚错位的薄结构,导致其缺失。
-
三维形状补全(RGB-D输入):
- 任务:给定RGB-D图像(包含部分深度信息),补全物体的完整形状。
- 结果:如图8所示,网络能成功猜测物体的缺失部分,利用从物体库中学习到的形状先验(如对称性、功能性)。
-
生成多个合理形状:
- 方法:通过改变输入噪声 ,从训练好的网络中进行多次采样。
- 结果:如图9所示,网络能够揭示其不确定性。对于确定的部分(如物体轮廓),不同预测间点位置变化小;对于存在歧义的部分(如物体的厚度),变化则较大。
8. 消融实验
作者进行了多项消融实验以验证设计选择:
- 网络架构设计(图14):
- 对比基础FC网络、FC+Deconv网络、Hourglass网络。
- 结果:引入反卷积分支显著提升了性能(CD和EMD值降低)。进一步堆叠沙漏结构也能带来性能增益。证明了双分支结构和更深层网络的有效性。
- 双分支功能分析(图11, 12):
- 可视化:反卷积分支倾向于生成包裹物体的连续表面,擅长捕捉物体的“主体”。全连接分支的输出则更无序,擅长补充细节部件(如枪尖、机尾、沙发扶手)。这证明了两分支的互补性。
- 损失函数对比(图15):
- 对比使用CD损失和EMD损失训练的网络。
- 结果:
- CD训练的网络:倾向于在不确定区域分散一些点,但能更好地保留细节形状。
- EMD训练的网络:产生更紧凑的结果,但有时会过度收缩局部结构。
- 这与在合成数据上的“平均形状”实验(图3)结论一致:CD鼓励“飞溅”状分布以覆盖可能性,而EMD倾向于产生一个位于可能性中间的“平均”形状。
其他创新点
- 处理真实形状歧义性的学习范式:除了使用随机噪声输入,文章还提出了两种明确处理训练集里“一对多”映射问题的方法:
- Mo2 (Min-of-Two) Loss:在训练时,对每个输入图像,从数据集中选取两个不同的真实形状,计算预测与两者间的损失,并取最小值。这鼓励网络预测落在两个可能形状之间的某个合理结果。
- 条件变分自编码器 (CVAE):如图5所示,引入一个编码真实形状分布的隐变量,使网络能够学习并采样条件分布 。
- 损失函数的设计与应用:针对点云这一无序集合的输出形式,系统地探索并应用了倒角距离 (CD) 和推土机距离 (EMD) 作为损失函数,分析了它们的不同特性,并提供了高效的(近似)计算方案以用于深度学习。
总结
PSGN是首个专门研究使用深度神经网络生成三维点云的工作。它通过创新的双分支网络架构、专门为点集设计的损失函数、以及处理真实歧义性的训练策略,成功实现了从单张图像进行高质量、且可能包含多个合理结果的三维重建。其实验结果在多个指标和任务上显著超越了之前的SOTA方法,特别是在保留物体细节结构方面表现突出。这项工作为后续的点云生成和处理研究奠定了重要基础。
 微信
微信- 支付宝

