
论文阅读_Point-MVSNet
Point-MVSNet(Point-Based Multi-View Stereo Network)
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Learning Patch-Wise Matching Confidence Aggregation for Multi-View Stereo |
| 作者 | Rui Chen、Songfang Han、Jing Xu、Hao Su |
| 作者单位 | Tsinghua University(清华大学) |
| 时间 | 2019 |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 多视角 |
| 输出 | 参考视角深度图 |
| 所属领域 | MVS |
1. 摘要精简
提出一种新颖的基于点云的深度多视图立体匹配(MVS)框架 Point-MVSNet,区别于传统代价体方法,直接以点云作为场景表示,采用 “粗到精” 的流程实现 3D 重建。首先生成粗深度图并转换为点云,再通过创新的 PointFlow 模块,融合 3D 几何先验与多视图 2D 纹理信息,迭代预测每个点的深度残差,逐步优化得到精确密集的点云。该方法在精度、计算效率和灵活性上优于代价体基方法,在 DTU 和 Tanks and Temples 数据集上实现了 SOTA 重建效果,源代码和训练模型已开源(https://github.com/callmeray/PointMVSNet)。
2. 研究动机与出发点
现有基于学习的 MVS 方法多依赖 3D CNN 处理固定分辨率的代价体,存在内存消耗随分辨率立方增长的瓶颈;虽有方法通过八叉树结构优化,但仍存在量化伪影和误差累积问题。此外,传统方法需处理整个 3D 空间,计算冗余且难以灵活适配局部区域细化需求(如机器人视觉交互场景)。因此,本文提出以点云为核心表示的框架,利用点云天然保留表面连续性、仅聚焦物体表面有效信息的优势,解决 3D CNN 的效率与精度矛盾,同时提供更高的灵活性。
3. 创新点
- 采用点云作为场景核心表示,避免固定分辨率代价体的内存瓶颈,自然保留表面结构连续性,提升高精度重建能力;
- 提出 PointFlow 模块,通过迭代预测深度残差(类似 ResNet 的残差学习)优化点云位置,动态适配场景几何;
- 设计点假设生成策略,沿参考相机方向生成多组假设点,捕捉不同深度的邻域特征与几何关系,辅助深度残差预测;
- 动态特征提取机制,结合多尺度图像特征金字塔与 3D 点坐标,根据迭代更新的点位置自适应提取多视图特征,聚焦感兴趣区域;
- 支持 “聚焦深度推断”(foveated depth inference),可仅对感兴趣区域(ROI)进行细化,大幅节省计算资源,适配特定应用场景。
4. 网络架构构成
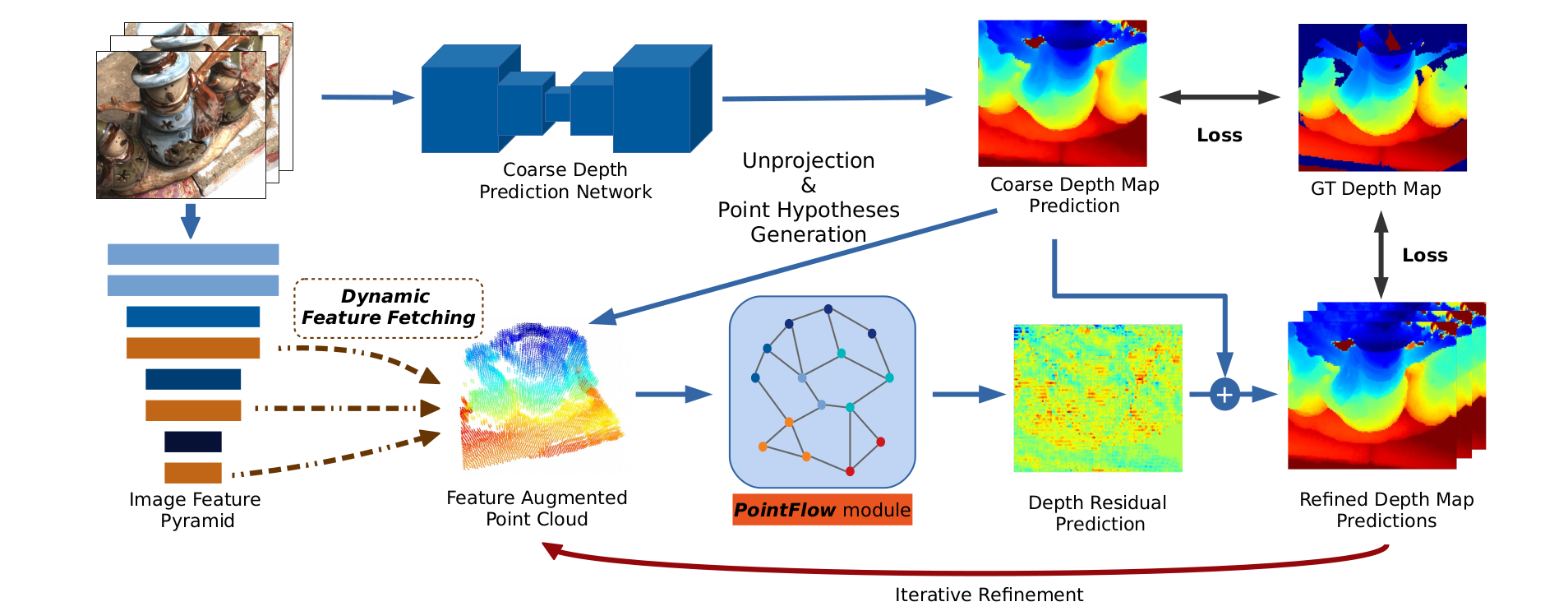
网络分为两大核心步骤,整体为 “粗预测 - 迭代细化” 结构:
- 粗深度预测:采用简化版 MVSNet 生成低分辨率粗深度图,该阶段特征图尺寸为原图 1/8,虚拟深度平面数量更少,深度平面数:训练时48,评估时96,内存消耗仅为 MVSNet 的 1/20;用多尺度 3D CNN 对低分辨率代价体进行简单正则化,再通过
soft argmin操作(与 MVSNet 一致),回归得到参考图I0的粗深度图D(0)。随后根据相机内参和外参,将粗深度图反投影为初始点云。 - 迭代深度细化:包含 2D-3D 特征提升和 PointFlow 模块两部分。首先通过特征金字塔提取多尺度图像特征,再通过动态特征提取将 2D 纹理与 3D 点坐标融合为增强特征;PointFlow 模块基于增强特征迭代预测深度残差,每次迭代对深度图上采样并减小假设点的深度间隔,逐步提升分辨率和精度。
6. 迭代深度细化PointFlow module
迭代细化中的多尺度图像特征金字塔构建
图像特征金字塔构建:对每张输入图像,采用 stride=2 的 2D 卷积进行下采样,提取下采样前的三层特征 ,所有输入图像共享该金字塔结构,以获取多尺度上下文信息。
动态特征获取(Dynamic Feature Fetching)
针对当前迭代的点云(含反投影点p和点假设),为每个点动态提取多视图特征:
- 可微反投影:根据点的 3D 坐标和相机参数,将点投影到各视图的特征金字塔上,因不同尺度特征图分辨率不同,需对相机内参做对应缩放;
- 多视图特征聚合:用方差代价 metric 聚合多视图特征(避免单视图遮挡 / 噪声影响),对金字塔第j层,方差计算为:对每个3D点 ,从多视图特征金字塔中提取特征计算特征方差作为代价度量:,为多视图第 j 层特征的均值
- 特征增强:将聚合后的 3 尺度外观特征与归一化的 3D 点坐标拼接,得到最终的点增强特征作为 PointFlow 模块的输入。
点假设生成(Point Hypotheses)
过 “点假设生成→边缘卷积→深度残差计算”3 步,实现点云精度提升:
因 2D 图像特征无法直接反映 3D 空间邻近关系,沿参考相机方向(归一化方向t)为每个反投影点p生成2m+1个 “假设点”(m=2,共 5 个)对于每个3D点 ,沿相机方向生成候选点:
其中::归一化相机方向。:深度间隔(随迭代减小每轮迭代减小:第 1 轮 8mm,第 2 轮 4mm,第 3 轮 0.8mm)。:假设点数量(通常为2)
边缘卷积(Edge Convolution)图神经网络处理
为利用 3D 局部几何关系,对 “特征增强点云”Cp(含反投影点和假设点)构建k 近邻(kNN)有向图(k=16),通过边缘卷积聚合邻域特征,对每个点假设 ,寻找k近邻点(k=16),构建有向图用于特征传播,公式为:
EdgeConv特征聚合
hΘ为可学习非线性函数(MLP)同时考虑中心点特征和相对几何关系
为对称聚合操作(支持最大池化 / 平均池化,性能相近);
Cp−Cq是关键:捕捉中心店p与邻域点q的几何差异,确保聚合的是 “3D 空间邻近” 的特征(区别于 MVSNet 的 “2D 图像邻近”)。
深度残差预测
用 3 层 EdgeConv 提取多尺度邻域特征,通过 shortcut 连接融合所有 EdgeConv 输出,再用共享 MLP 将特征转换为 “假设点概率”(softmax 归一化),最终通过 “概率加权和” 计算点p的深度残差:
对每个原始点 的所有假设点 通过MLP计算每个假设点的概率 ,然后就可以深度残差计算
加权求和得到每个点的深度位移
步骤5:迭代更新
-
深度图更新
-
然后使用最近邻上采样提高深度图分辨率,减小深度间隔 以捕捉更精细细节(第 1 轮 160×120→320×240,第 2 轮→640×480);
-
通常进行2-3次迭代,每次迭代:分辨率加倍,深度间隔减半
7. 代价体正则化
- 在粗深度预测阶段使用3D CNN对代价体进行正则化,回归初始深度图。
- 在PointFlow中,使用EdgeConv对点云进行局部特征聚合,替代传统的3D CNN正则化。
8. 深度图生成
-
初始深度图由粗预测网络生成。
-
通过PointFlow模块迭代优化:
-
点云反投影:将当前深度图(粗预测或前一次细化结果)根据相机参数反投影为 3D 点云;
-
深度残差预测:PointFlow 模块通过点增强特征,预测每个点沿参考相机方向的深度残差Δdp,计算方式为,其中为点假设,s为位移步长,为假设点的概率权重(通过 softmax 输出);
-
深度图更新:将残差Δdp叠加到当前深度图,得到更新后的深度图,同时对深度图上采样,减小下一轮迭代中假设点的深度间隔;
-
最终融合:经过多轮迭代后,融合所有视图的预测深度图,生成最终的密集点云。
-
生成点假设:沿相机方向生成多个假设点
-
使用EdgeConv聚合局部特征,预测每个点的深度残差:
-
每次迭代后上采样深度图并减小深度间隔 ,逐步提升分辨率与精度。
-
9. 损失函数
使用 损失,对所有迭代阶段的深度图进行监督:
为有效地面真值(GT)像素集;
l为迭代次数;
为第 i 次迭代的预测深度,为对应 GT 深度;
为损失权重(训练时设为 1.0);
为缩放因子,用于平衡不同迭代步骤的损失贡献。
10. 测试数据集
- 主要测试数据集:DTU 数据集,包含 124 个场景,7 种光照条件,49 或 64 个拍摄位置,分为训练集、验证集和评估集,用于量化和定性性能评估;
- 泛化性测试数据集:Tanks and Temples 数据集(intermediate 子集),为大型户外复杂场景数据集,用于验证模型在真实复杂环境中的泛化能力。
11. 消融实验
- 边缘卷积(EDGE):替换为无几何感知的特征聚合(仅使用邻域点特征Cq),重建精度和完整性显著下降,验证几何关系建模的重要性;
- 欧氏最近邻分组(EUCNN):替换为图像空间邻域分组(相邻像素对应点),因遮挡导致特征聚合无关信息,性能下降;
- 特征金字塔(PYR):仅使用单层特征而非金字塔,多尺度上下文信息缺失,性能明显下降;
- 点假设数量(m):测试 m=1、2、3 三种情况,m=2 时完整性和整体质量最优;
- 输入视图数量(N):测试 N=2、3、5 三种情况,视图数量越多,重建质量越好,符合 MVS 基本规律;
- kNN 搜索优化:验证限制 kNN 搜索范围(仅在k×k×(2m+1)邻域内搜索)的有效性,降低O(N2)的计算开销,同时保证性能。
12. 其他创新点
- foveated深度推断:支持仅对感兴趣区域进行高分辨率重建,节省计算资源。
- 泛化能力强:在Tanks and Temples数据集上提升明显,-score 从43.48提升至48.27。
- 内存与速度优势:相比MVSNet,在相同分辨率下内存更小,支持更高分辨率输出。
- 对初始深度图噪声的鲁棒性:在初始深度图添加≤6mm 的高斯噪声时,重建误差增长缓慢且优于 MVSNet,说明迭代细化机制可抵消部分初始噪声影响;
- 点云上采样优势:相比 PU-Net 等传统点云上采样方法,通过融合多视图图像信息,重建精度(Acc. 0.361mm vs 1.220mm)和完整性(Comp. 0.421mm vs 0.667mm)大幅提升;
- 灵活的分辨率与效率权衡:通过调整迭代次数,可在不同深度图分辨率(160×120 至 640×480)、GPU 内存消耗(7219MB 至 8731MB)和运行时间(0.34s 至 3.35s)之间灵活权衡,适配不同应用场景。
 微信
微信- 支付宝

