
论文阅读_Pixel2Mesh
Pixel2Mesh
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Pixel2Mesh: Generating 3D Mesh Models from Single RGB Images |
| 作者 | Nanyang Wang、Yinda Zhang、Zhuwen Li、Yanwei Fu、Wei Liu、Yu-Gang Jiang(前三位为同等贡献作者,Yu-Gang Jiang 为通讯作者) |
| 作者单位 | Fudan University(复旦大学,Shanghai Key Lab of Intelligent Information Processing, School of Computer Science) |
| 时间 | 2018 |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 标定之后的多视角图像 |
| 输出 | Mesh |
| 所属领域 | MeshMVS |
一、 摘要精简
本文提出了一种端到端的深度学习框架,能够从单张彩色图像直接生成物体的三维三角网格模型。与以往生成体素或点云的方法不同,本工作直接在基于图的卷积神经网络中表示三维网格,通过逐步变形一个椭球体来产生正确的几何形状,并利用从输入图像中提取的感知特征进行引导。网络采用从粗到细的策略,并定义了多种与网格相关的损失函数,以保证生成视觉上逼真且物理上准确的三维几何体。
二、 引言与出发点
作者在引言中阐述了以下出发点:
- 问题与局限:近年来,深度学习技术在单图 3D 形状生成领域取得一定成功,但现有方法的输出多为体素或点云:体素表示受内存限制分辨率较低,点云缺乏点间局部连接,两者均丢失重要表面细节,且难以转换为网格模型。而网格模型具有轻量化、能建模形状细节、易于变形用于动画等优势,更适用于实际应用场景(如游戏、影视行业)。
- 核心思路:与其直接合成,不如让模型学习如何将一个平均形状(椭球体)变形为目标几何体。这样做有几个好处:深度网络更擅长预测残差变形;一系列变形可以逐步细化形状;便于将先验知识(如拓扑)编码到初始网格中。
- 目标:专注于重建亏格为0(可变形为球体)的常见物体,如汽车、飞机、椅子等,为从单图直接生成可直接使用的网格模型开辟新途径。
创新点
- 提出首个端到端神经网络架构,实现从单张 RGB 图像直接生成 3D 网格模型,无需中间转换步骤(如体素转网格、点云转网格),填补了现有方法在直接网格生成上的空白。
- 设计感知特征池化层,建立 2D 图像特征与 3D 网格几何之间的桥梁:将 3D 网格顶点投影到 2D 图像平面,通过双线性插值采样图像特征,并与 3D 网格顶点特征融合,使网格变形能精准贴合图像中的物体形状信息。
- 采用粗到细的网格生成策略:从顶点数量较少的初始椭球开始,通过图上采样层逐步增加顶点数量,在不同阶段分别优化全局结构与局部细节,既保证了变形过程的稳定性,又提升了网格的细节表现力。
- 基于网格的图结构特性,定义多种针对性损失函数(表面法向损失、拉普拉斯正则化损失、边缘长度损失),分别约束表面平滑性、顶点相对位置、顶点分布均匀性,有效避免网格自相交、飞点等问题,保证生成网格的几何合理性。
- 提出基于残差连接的图卷积网络(G-ResNet)作为核心变形模块,解决深层图卷积网络的梯度消失与退化问题,扩大特征感受野,促进顶点间的信息交换,提升变形预测的准确性。
- 设计边缘基图上采样层:在每条边的中点添加新顶点并合理连接,相比面基上采样,能保持顶点度数均衡,确保网格拓扑结构规则,为细节优化提供良好基础。
四、 网络架构构成
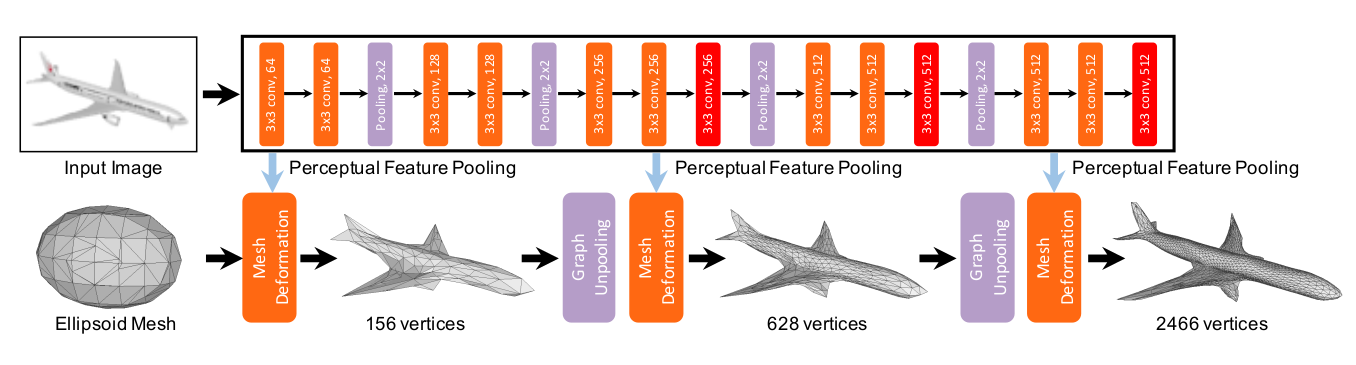
网络是一个端到端的框架,由两部分组成:
- 图像特征网络:一个类VGG-16的2D CNN,用于从输入图像中提取多层次的感知特征,具体使用 conv3_3、conv4_3、conv5_3 三层特征进行拼接。
- 级联网格变形网络:一个基于图的卷积网络,作为主体。它包含三个网格变形块,中间由两个图解池层连接。网络从一个具有156个顶点的固定椭球体开始,每个变形块接收当前网格图(包含顶点坐标和特征),输出变形后新的顶点坐标和特征。图解池层则负责增加顶点数量,以容纳更多几何细节。
五、 特征提取方法
特征提取分为 2D 图像特征提取与 3D 网格特征提取,通过感知特征池化层实现两者融合:
- 2D 图像特征提取:使用类 VGG-16 架构,对输入的 224×224 RGB 图像进行卷积操作,分别提取 conv3_3、conv4_3、conv5_3 三层特征图,将三者拼接得到维度为 1280 的图像感知特征。
- 3D 网格特征提取:初始阶段,网格顶点特征仅为其 3D 坐标(3 维);经过第一个变形块后,顶点特征更新为 128 维的形状特征;后续阶段,顶点特征为 128 维形状特征,与图像感知特征融合后用于进一步变形。
- 特征融合:通过感知特征池化层实现。对于每个 3D 网格顶点,利用相机内参将其 3D 坐标投影到 2D 图像平面,得到对应像素位置;采用双线性插值采样该位置附近 4 个像素的图像感知特征(1280 维),与当前顶点的 3D 特征(初始为 3 维,后续为 128 维)拼接,得到 1408 维的融合特征,输入 G-ResNet 进行顶点位置与特征更新。
六、 Mesh生成流程
Mesh是通过一个渐进式、由粗到细的变形流程生成的:
- 初始化:从一个位于相机坐标系中固定位置、固定大小的椭球体网格开始,中心位于相机前方 0.8m 处,三轴半径分别为 0.2m、0.2m、0.4m,包含 156 个顶点和 462 条边,顶点初始特征为其 3D 坐标。
- 变形与上采样:
- 第一个变形块读取初始椭球体,利用其特征和从图像中池化的感知特征,通过G-ResNet预测顶点的第一次位移,得到 156 个顶点的粗粒度网格,初步贴合物体全局结构。
- 第一个图解池层通过在每条边的中点添加新顶点的方式,将网格顶点数量增加约4倍,并建立新连接,网格顶点数从 156 增加到 628,保持三角网格拓扑。
- 第二、第三个变形块与图解池层重复此过程:变形 -> 上采样 -> 再变形。
- 输出:经过三个阶段的变形和两次上采样后,最终输出一个具有2466个顶点的、细节更加丰富的三角网格。
七、 Loss函数设计
除了基础的倒角距离损失,论文引入了多个针对网格特性的损失函数进行正则化,总损失为加权和:
其中 。
- 倒角距离损失:使预测网格顶点靠近真实表面。
- 法向损失:约束预测网格的局部表面朝向与真实表面一致,促进平滑。
- 拉普拉斯正则化损失:定义为变形前后顶点拉普拉斯坐标的差异,保留顶点的局部相对关系,防止网格在变形过程中过度扭曲和自相交。
- 边长度正则化损失:惩罚过长的边,防止出现“飞点”。
八、 训练与测试数据集
- 训练数据集:使用Choy等人提供的ShapeNet数据集子集。包含13个类别的3D CAD模型渲染图。
- 测试数据集:
- 同上,在ShapeNet测试集上进行定量评估。
- 在Online Products数据集和互联网真实图像上进行定性测试,以验证模型的泛化能力。
九、 输入输出与部署
- 训练/推理输入:单张
224x224分辨率的RGB图像,以及已知的相机内参(用于特征投影)。 - 输出:一个三角网格模型(顶点坐标和面片连接关系)。
- 部署变化:训练和推理阶段输入输出形式一致。论文提到在Nvidia Titan X上,推理一个网格(2466顶点)耗时约15.58毫秒。
十、 消融实验测试的组件
论文通过消融实验验证了各组件的重要性:
- 图解池层:移除后,网络从头到尾使用高分辨率网格,导致初期变形错误难以修正,出现明显伪影。
- G-ResNet中的残差连接:将G-ResNet换成普通GCN后,所有评估指标大幅下降,证明了残差连接对于有效训练深层图网络至关重要。
- 各损失项:
- 移除法向损失:网格表面平滑度和局部细节变差。
- 移除拉普拉斯正则化:导致网格局部拓扑剧变,产生自相交。
- 移除边长度正则化:产生“飞点”和长边,破坏表面完整性。
- 变形块数量:实验了2、3、4个块。增加块数能提升精度,但3个块之后收益饱和。最终选择3块以平衡性能与效率。
三、 创新点总结
- 开创性的端到端单视角网格生成框架:首次提出了一个完整的、能从单张RGB图像直接生成可用的3D三角网格的深度学习模型,摆脱了体素、点云等间接表示的局限。
- 感知特征投影层:设计了一个可微分的模块,将2D图像特征通过相机投影“粘贴”到3D网格顶点上,实现了图像语义信息对3D几何形变的直接、有效引导。
- 基于图的从粗到细生成策略:
- 渐进变形:采用级联GCN,从低分辨网格开始,逐步变形并上采样,使优化过程更稳定。
- 图解池操作:设计了基于边的图向上采样方法,均匀增加顶点,保持了网格的规整性。
- 网格特异性损失函数:充分利用了网格的图结构,定义了法向、拉普拉斯、边长度等损失,从不同几何层面约束生成质量,这是体素或点云表示难以实现的。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 This is a 部落格 of outbreak_sen!
 微信
微信- 支付宝

