
论文阅读_Pixel2Mesh++
Pixel2Mesh++
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Pixel2Mesh++: 3D Mesh Generation and Refinement from Multi-View Images |
| 作者 | Chao Wen, Yinda Zhang, Chenjie Cao, Zhuwen Li, Xiangyang Xue, Yanwei Fu |
| 作者单位 | Fudan University(复旦大学,Shanghai Key Lab of Intelligent Information Processing, School of Computer Science) |
| 时间 | 2021 |
| 发表会议/期刊 | IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 标定之后的多视角图像 |
| 输出 | Mesh |
| 所属领域 | MeshMVS |
一、 摘要精简
本文提出一种基于图卷积神经网络的框架,从少量多视角 RGB 图像(带或不带相机姿态)生成 3D 网格模型。该方法不直接构建图像到 3D 形状的映射,而是通过多视图变形网络(MDN)迭代优化粗网格形状。MDN 受传统多视图几何方法启发,在每个顶点周围采样变形假设,利用多视图感知特征统计推理最优变形。模型支持端到端训练,适配可变输入视图数,可结合可微渲染进行测试时优化,且对初始网格质量、相机姿态误差具有鲁棒性。实验表明,生成的 3D 形状不仅在输入视角下视觉合理,在任意视角下也能精准对齐,跨语义类别、输入视图数的泛化能力优异,在 ShapeNet 数据集上取得当前最优性能。
二、 引言与出发点
作者在引言中阐述了以下出发点:
- 单视图方法的局限:基于单张图像的方法由于视角有限,通常在被遮挡区域只能产生粗糙的几何形状,并且在泛化到训练域之外时(如跨类别)表现不佳。
- 多视图的潜力与挑战:多视图图像能提供更多信息,但简单地扩展单视图方法(如融合多个单视图预测结果或拼接多视图特征)效果不佳,无法有效利用跨视图信息。
- 核心思路:继承Pixel2Mesh“通过变形生成”的思想,但不再依赖从单图像中学习形状先验,而是设计一个受传统多视图几何方法启发的网络架构(MDN),使其能够像寻找对应点一样,根据跨视图的关联性来推理几何形状。这样能产生更精确的几何形状,并提升泛化能力。
创新点
- 提出多视图变形网络(MDN):通过在每个顶点周围采样变形假设,结合多视图感知特征统计推理最优变形,模仿传统多视图几何的对应关系搜索,而非依赖数据驱动的形状先验,提升跨场景泛化能力。
- 设计可微 3D 软 argmax 模块:将非可微的假设选择转化为加权求和,使 MDN 支持端到端训练,避免随机优化带来的次优解问题。
- 特征统计编码策略:对多视图池化特征计算均值、最大值、标准差并拼接,实现输入视图数和顺序的不变性,自然适配可变数量的输入图像。
- 相机姿态估计网络:采用 6D 连续旋转表示 + 1D 平移的 7D 紧凑编码,支持在未知相机姿态时自动估计,降低真实场景应用门槛。
- 重采样 Chamfer 损失:通过三角形面积比例均匀采样网格表面点,解决传统 Chamfer 损失在顶点分布不均时的偏差问题,提升表面精度。
- 迭代优化与可微渲染集成:MDN 可迭代运行逐步提升形状质量,且能结合可微渲染通过图像轮廓约束进一步优化 3D 形状,适配少视图场景。
- 兼容多源粗网格初始化:支持 Pixel2Mesh(固定拓扑)、DISN(隐式表示,任意拓扑)等多种粗网格生成方法,对初始网格噪声和拓扑变化具有鲁棒性。
四、 网络架构构成
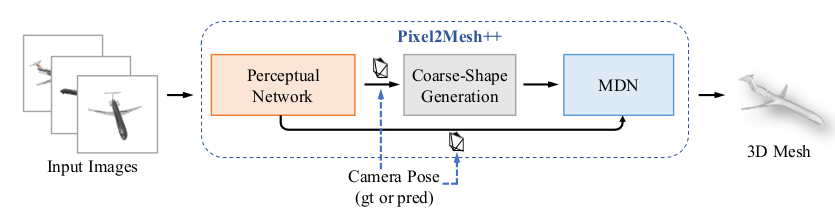
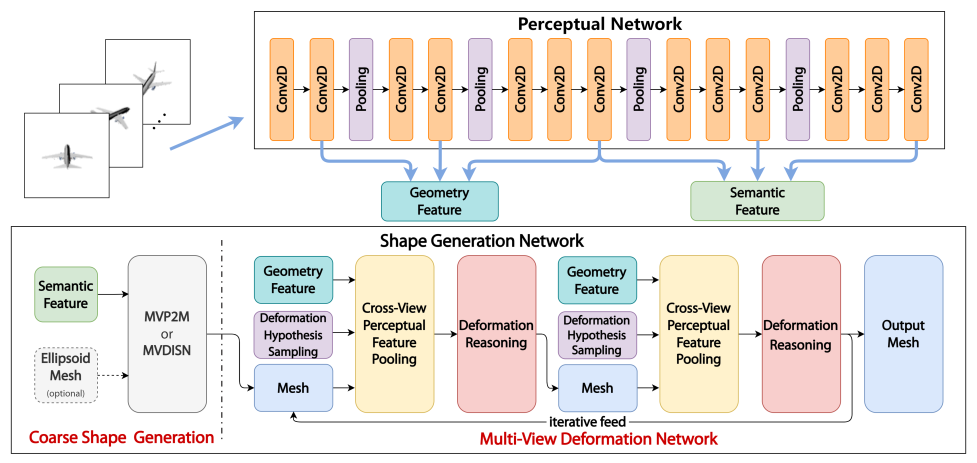
整体流程:输入多视图 RGB 图像→(可选)相机姿态估计→粗网格生成→MDN 迭代优化(可结合可微渲染)→输出高精度 3D 网格。
网络整体分为两部分核心模块,采用 “粗到细” 策略,支持端到端训练:
-
3D 形状预测模块:包含粗网格生成和多视图变形网络(MDN)。粗网格生成由 MVP2M(muilt iew Pixel2Mesh)或 MVDISN(多视图扩展的 DISN)实现,输出初始粗网格;MDN 是核心优化模块,包含变形假设采样、跨视图感知特征池化、变形推理、可微渲染(可选)四个子组件,负责迭代细化网格。
-
相机姿态估计模块:使用一个CNN来预测从规范坐标系到相机坐标系的6D旋转和1D平移,含图像特征提取层和两个分支(6D 旋转预测、1D 平移预测),用于未知相机姿态时的参数估计。
多视图变形网络(MDN - 核心):该网络对粗形状进行迭代优化。对于网格中的每个顶点:
- 变形假设采样:在顶点周围采样一组(42个)可能的变形目标位置,形成一个局部假设图。
- 跨视图感知特征池化:将所有假设点投影到每一张输入图像上,并从VGG网络的早期层(如conv1_2, conv2_2, conv3_3)池化高分辨率特征。然后计算这些多视图特征的统计量(均值、最大值、标准差)作为该假设点的特征,使其与输入视图的数量和顺序无关。
- 可微变形推理:一个GCN(评分网络)处理局部假设图,为每个假设预测一个权重。通过可微的soft argmax(加权求和)计算出该顶点的最终变形位移。
五、 特征提取方法
特征提取的核心在于跨视图感知特征池化,它与Pixel2Mesh有显著区别:
- 特征来源层:使用VGG-16的早期卷积层(
conv1_2,conv2_2,conv3_3),因为这些层的特征空间分辨率高,保留了更多低层次的几何和纹理细节,有利于精确的几何对齐。 - 多视图特征融合::利用相机内参和外参(已知或预测),将 3D 网格顶点(及变形假设点)投影到每张输入图像的特征图上,通过双线性插值采样 4 个相邻像素的特征;对所有视图的池化特征计算均值、最大值、标准差,拼接后得到与视图数无关的特征向量/统计量(均值 、最大值 、标准差 )。
- 网格特征融合:将统计编码后的图像特征(维度适配后)与网格顶点的 3D 坐标(3 维)或形状特征拼接,形成融合特征,输入 MDN 的图卷积层进行变形推理。
- 优势:
- 维度固定:最终特征维度与输入视图数量无关。
- 顺序无关:对输入图像的顺序具有不变性。
- 显式编码关联:统计量(如标准差)能显式地反映不同视图间特征的差异与一致性,有助于网络推理跨视图信息。
六、 Mesh生成流程
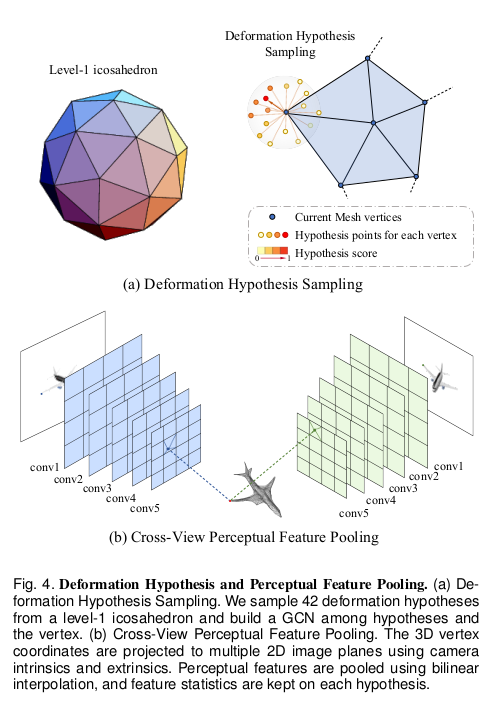
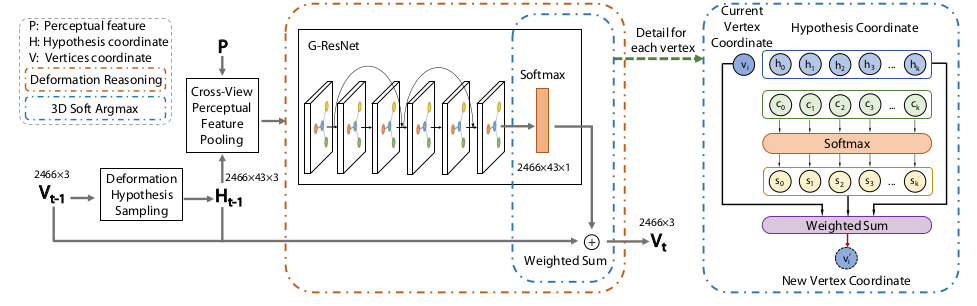
Mesh是通过**“粗预测 + 迭代精修”** 的流程生成的:
- 粗网格初始化:由 MVP2M 或 MVDISN 生成粗网格。MVP2M 输出 2466 个顶点的固定拓扑网格,MVDISN 输出任意拓扑的粗网格,均已融合多视图特征初步贴合物体形状。
- 变形假设采样:对粗网格的每个顶点,以该顶点为中心、尺度 0.02 的 1 级二十面体为模板,采样 42 个变形假设点,与原顶点组成含 43 个节点、162 条边的局部图。
- 跨视图特征融合:将每个假设点投影到所有输入图像,池化图像特征并计算统计量,与假设点 3D 坐标拼接形成融合特征。
- 变形推理:通过 6 层图残差卷积层GCN为每个假设点打分,经 softmax 归一化后,以加权求和(3D 软 argmax)得到顶点的最优新位置。
- 迭代优化:重复步骤 2-4,迭代 3 次后网格质量趋于饱和;可选接入可微渲染,通过匹配多视图轮廓进一步优化顶点位置,最终输出高精度 3D 网格。
七、 Loss函数设计
在Pixel2Mesh的损失函数基础上进行了重要改进:
总损失函数为加权和:
其中 。
- 重采样倒角距离损失:关键改进。原始倒角距离只计算顶点间的距离,当网格顶点分布不均时效果不好。本文在计算损失前,先对预测网格进行均匀重采样4000 个点(每个三角形采样数与面积成正比)。给定三角形及其顶点 ,使用如下公式在三角形内均匀采样点 :
其中 。然后在重采样得到的点云上计算倒角距离,使损失更能反映整个表面的拟合质量。
- 法向损失、边长度正则化、拉普拉斯正则化:与Pixel2Mesh定义相同,用于保证表面光滑、防止异常长边和保持局部细节。
- 相机姿态估计损失:计算真实相机变换与预测相机变换作用于规范点云后的 L2 距离。当训练位姿估计网络时,使用损失比较预测位姿和真实位姿变换后的点云差异。
- 可微分渲染器损失(测试时优化可选):在推理阶段,如果有多视图轮廓图,可结合可微分渲染器,通过最小化预测形状与输入轮廓之间的2D差异来进一步优化3D形状。
八、 训练与测试数据集
- 训练数据集:使用Choy等人提供的ShapeNet数据集子集,包含13个类别的3D CAD模型多视图渲染图像及相机参数。
- 测试数据集:
- 上述ShapeNet测试集,用于定量评估。
- ABC数据集:用于测试模型的跨数据集泛化能力。
- Online Products数据集和互联网真实图像:用于定性评估在真实图像上的表现。
九、 输入输出与部署
- 训练输入:少量(如3张)多视角RGB图像,以及(可选的)相机位姿真值。
- 推理输入:少量多视角RGB图像。相机位姿可以是已知的,或由网络预测的,甚至是有噪声的。
- 输出:一个优化的3D三角网格模型。
- 部署变化:训练和推理输入形式基本一致。论文提到在NVIDIA Titan Xp GPU上,生成一个网格耗时约0.32秒。推理时可以利用可微分渲染器进行实例级的测试时优化。
十、 消融实验测试的组件
论文进行了详尽的消融实验和分析:
- 统计特征 vs. 拼接特征:对比使用统计特征池化和直接拼接多视图特征。统计特征方法在支持可变视图输入的同时,取得了更好的性能,表明其能更有效地编码跨视图关联。
- 重采样倒角损失 vs. 原始倒角损失:使用原始顶点计算的倒角距离会导致指标下降。重采样损失能更好地处理顶点稀疏或不规则的区域,提升整体表面质量。
- MDN迭代次数:分析迭代应用MDN的效果。性能随迭代次数增加而提升,在3次后趋于饱和。
- 泛化能力测试:
- 跨类别泛化:训练时剔除某个类别,测试时在该类别上仍能有效提升粗形状,证明MDN不依赖于特定类别的形状先验。
- 输入视图数量泛化:使用固定视图数训练的MDN,在不同数量视图的测试集上表现稳健,且更多训练视图能带来增益。
- 鲁棒性分析:
- 初始形状鲁棒性:对粗形状添加噪声、平移或使用其他方法(如3D-R2N2体素)生成的网格,MDN仍能有效优化。
- 相机位姿鲁棒性:使用预测的(有误差的)相机位姿,MDN依然能工作并提升结果。
三、 创新点总结
- 多视图变形网络(MDN):核心创新。提出了一个受传统多视图几何启发的网络模块,通过采样变形假设并利用跨视图特征统计量来推理顶点位移,实现了从“学习形状先验”到“推理几何对应”的范式转变,从而提升了精度和泛化能力。
- 面向多视图的统计特征池化:设计了将多视图图像特征编码为统计量的方法,使网络能够处理任意数量和顺序的输入视图,并显式地建模视图间的特征关联,这是有效融合多视图信息的关键。
- 可微变形推理与迭代优化框架:通过可微的soft argmax实现从假设到最终变形的可微推理,使整个系统能端到端训练。MDN可以迭代应用,实现对网格的逐步精修。
- 灵活的输入与强大的泛化:系统对输入要求宽松,支持已知/未知/有噪声的相机位姿。MDN展现出优秀的跨语义类别、跨输入视图数量、跨初始网格质量的泛化能力。
- 重采样倒角距离损失:改进了基于网格的损失函数,通过对网格表面进行均匀重采样来计算倒角距离,使损失更能准确反映整个表面的重建质量,改善了网格均匀性。
- 与可微分渲染器的互补:展示了MDN可以与可微分渲染器结合,在测试时利用轮廓图进行实例优化,为获得更高精度提供了途径。
 微信
微信- 支付宝

