
论文阅读_P-MVSNet
P-MVSNet
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Learning Patch-Wise Matching Confidence Aggregation for Multi-View Stereo |
| 作者 | Keyang Luo、Tao Guan、Lili Ju、Haipeng Huang、Yawei Luo |
| 作者单位 | Huazhong University of Science and Technology(华中科技大学)、University of South Carolina(南卡罗来纳大学)、Farsee2 Technology Ltd(远鉴科技) |
| 时间 | 2019 |
| 发表会议/期刊 | IEEE International Conference on Computer Vision (ICCV) |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 多视角 |
| 输出 | 参考视角深度图 |
| 所属领域 | MVS |
1. 摘要精简
将各向异性的平面扫描体积近似为各向同性代价体的缺陷,结合各向同性与各向异性 3D 卷积构建混合 3D U-Net。核心包含两个模块:
①patch-wise 匹配置信度聚合模块,聚合像素级特征匹配信息生成匹配置信体(MCV),提升噪声鲁棒性;
②混合 3D U-Net,从 MCV 中推断深度概率分布并预测深度图。
在 DTU 和 Tanks & Temples 基准数据集上,P-MVSNet 的重建完整性与整体质量超越现有方法,达到 SOTA 性能。
2. 引言与动机
深度图基的学习型 MVS 方法是当前主流,但现有方法存在三大关键缺陷,构成研究动机:
- 匹配度量不合理:现有方法(如 MVSNet)用 “特征方差” 计算匹配代价,平等对待所有视图的像素对贡献,未突出参考图像的核心地位 —— 若源图像像素特征相似但与参考图像不匹配,会产生低代价误导深度估计,导致错误。
- 代价体近似偏差:平面扫描生成的体积本质是各向异性的(仅深度方向可推断深度信息,其他方向无此属性),但现有方法用各向同性代价体近似,破坏几何特性,不利于后续正则化。
- 噪声鲁棒性差:现有方法直接对像素级代价体正则化或直接推断深度,未利用局部 patch 上下文信息,对低纹理、遮挡区域的噪声敏感,重建完整性不足。
传统基于平面扫描的代价体在深度和空间方向上是各向异性的,但现有方法常将其近似为各向同性,这不利于准确匹配。此外,现有匹配度量(如特征方差)对所有像素对一视同仁,容易在非参考图像中产生误导性低匹配代价。因此,P-MVSNet 强调在构建匹配置信度时应突出参考图像的重要性,并利用各向异性结构指导正则化。
3. 创新点
- 提出patch-wise 匹配置信度聚合模块:通过学习式聚合像素级匹配置信度(而非启发式方法),利用 3×3 局部 patch 与深度方向相邻 patch 的上下文信息,生成鲁棒的匹配置信体(MCV),自动调整特征通道权重,提升噪声环境下的匹配精度。
- 设计混合 3D U-Net:浅层用 1×3×3(聚合平面内信息)和 7×1×1(深度方向大感受野,低计算成本)各向异性卷积,深层用 3×3×3 各向同性卷积,适配代价体的各向异性特性,高效融合上下文信息。
- 提出深度置信度与一致性过滤准则:①深度置信度准则(过滤概率分布无单峰的低置信度深度);②深度一致性准则(过滤多视图间不一致的深度),提升点云重建的准确性与完整性。
- 在 DTU 和 Tanks & Temples 数据集上实现 SOTA:DTU 上完整性最优(0.434mm)、整体质量第一(0.420mm);Tanks & Temples 上(2019 年 2 月 19 日前)均值 F-score 55.62,排名第二,泛化性强。
4. 网络架构
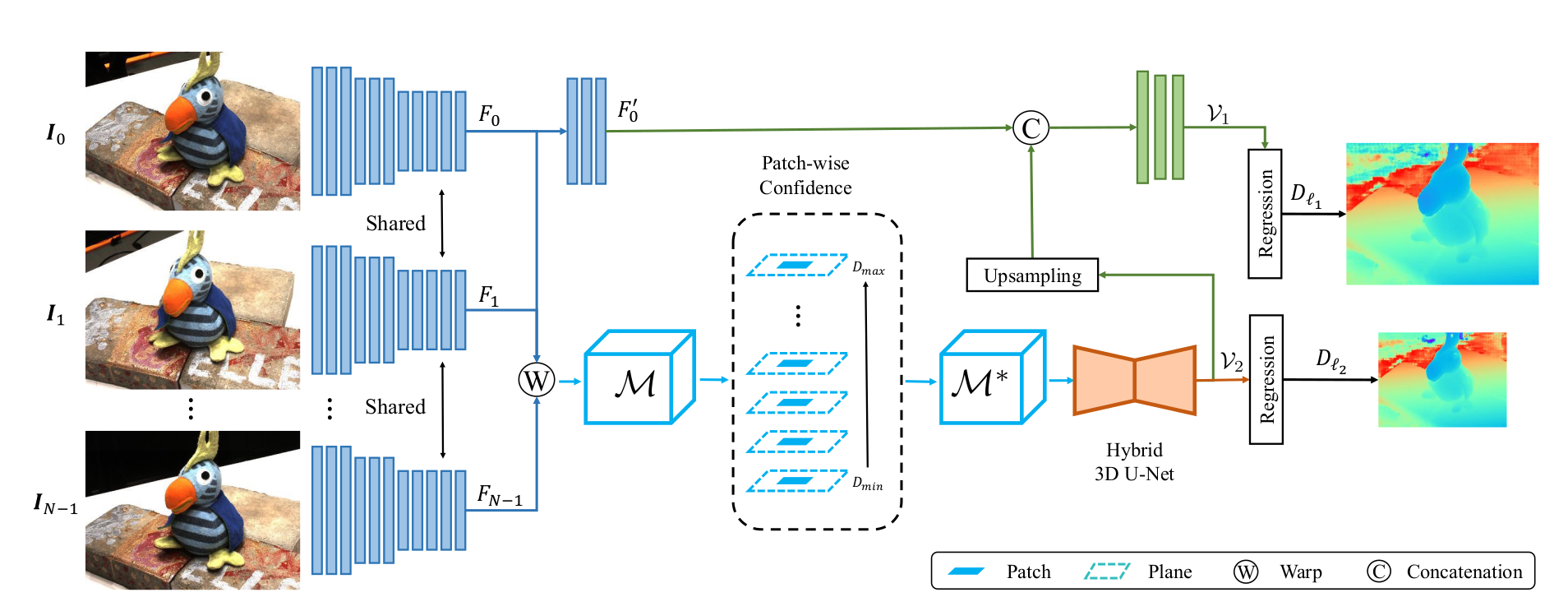
P-MVSNet 整体为端到端结构,包括:
- 权重共享特征提取器:对所有输入图像提取多尺度特征(ℓ₂低分辨率特征、ℓ₁高分辨率特征);
- patch-wise 匹配置信度聚合模块:基于ℓ₂特征构建像素级匹配置信体(MCV),再聚合为 patch-wise MCV;
- 混合 3D U-Net:对 patch-wise MCV 正则化,输出潜在概率体(LPV);
- 深度精炼结构:结合ℓ₁特征,将低分辨率深度图(ℓ₂)提升为高分辨率深度图(ℓ₁),最终输出高精度深度图。
5. 特征提取
- 特征提取采用权重共享的编码器 - 解码器架构,仅对参考图像输出高分辨率特征,流程如下:
- 输入:N 张输入图像(1 张参考图I0,N-1 张源图I1:N−1),尺寸H×W;
- 编码器(所有图像共享):11 个 2D 卷积块,含残差连接,输出ℓ₂特征(低分辨率):
- 前 3 层:3×3 卷积(步长 1),输出 8 通道H×W特征;
- 第 4-6 层:5×5 卷积(步长 2)+ 2 个 3×3 卷积(步长 1),输出 16 通道H/2×W/2特征(conv1 2 无 BN/ReLU);
- 第 7-11 层:5×5 卷积(步长 2)+ 2 个 3×3 卷积(步长 1),add conv2 0 与 conv2 2 特征后,经 1×1 卷积(无 BN/ReLU)输出 16 通道H/4×W/4的ℓ₂特征Fi(i=0:N−1);
- 解码器(仅参考图像):3 个 2D 卷积块,输出ℓ₁特征(高分辨率):
- 第 1 层:3×3 转置卷积(步长 2),输出 16 通道H/2×W/2特征;
- add 转置卷积结果与 conv1 2 特征,经 2 个 3×3 卷积(步长 1,最后一层无 BN/ReLU),输出 16 通道H/2×W/2的ℓ₁特征。
6. 代价体构建
P-MVSNet 认为,一个点的匹配是否可靠,应该看看它邻居们的表现。如果 p 点本身匹配一般,但它周围的所有点都匹配得很好,那么网络通过 学习到这些邻居的“支持”信息后,会提升 p 点的整体置信度。反之,如果只有 p 点自己匹配好,周围都很差,它的置信度就会被拉低。这极大地增强了在弱纹理、重复纹理区域的鲁棒性。
光在同一个深度平面上看还不够,P-MVSNet 还要在深度方向上看一看,真正的物体表面在深度上是连续的。通过查看深度方向上的邻居,网络可以更好地判断当前这个深度假设是否处于一个平滑的表面附近,从而抑制那些孤立的、跳动的错误深度假设。。它取当前深度 d 及其相邻的两个深度,共三个深度平面上的对应块, 一个 3x3x3 的 3D 卷积,负责融合深度方向上的相邻信息。然后通过一个激活函数获得深度范围置信度**
代价体为patch-wise匹配置信体(MCV),分"像素级MCV构建"与"patch-wise聚合"两步:
6.1 像素级匹配置信体()
基于平面扫描与MSE度量,突出参考图像权重,公式为:
- :深度假设(对应平面 ), 为深度假设数量(实验中 )
- :参考图像特征的像素坐标,:源图像 中与对应的像素(双线性插值计算)
- :特征通道()
- 物理意义:指数函数将MSE转化为置信度(值越接近1,匹配度越高),仅计算源图像与参考图像的差异,突出参考图像核心地位
6.2 patch-wise匹配置信体聚合()
聚合局部patch与深度方向上下文信息,提升抗噪声能力:
- :取深度平面 上以 为中心的3×3 patch
- :取深度方向以 为中心的3个相邻patch
- :1×1×1 3D卷积(BN+ReLU),融合单像素多通道置信度
- :1×3×3 3D卷积(BN+ReLU),融合3×3 patch内邻域信息
- :3×3×3 3D卷积(BN),融合深度方向相邻patch信息
- 激活:将置信度归一化到 ,增强数值稳定性
最终patch-wise MCV尺寸为 ,作为混合3D U-Net的输入
构建像素级匹配置信度体积 ,公式为:
然后通过可学习的块级聚合函数将其转为块级匹配置信度体积 ,增强鲁棒性。
7. 代价体正则化
MVSNet是简单的CNN,直接使用了一个标准的、各向同性的3D U-Net进行正则化,然而,通过平面扫描算法生成的代价体本质上是各向异性的:每个值代表一个不同的深度假设,是离散的、非连续的。相邻深度之间的关系是几何投影关系,而非像图像空间那样的表观连续关系。用一个 的卷积核同时处理这三个性质迥异的维度,效率不高,且可能混淆不同性质的信息。
通过混合 3D U-Net实现代价体正则化,核心是适配代价体的各向异性特性,高效融合上下文:
a) 浅层网络:使用各向异性卷积
在网络的浅层,它使用了两种不同形状的卷积核,分别处理空间信息和深度信息:
- 卷积
- 这个卷积核只在空间维度(H, W)上进行卷积,在深度维度(D)上不做任何融合。
- 作用:专注于在同一个深度假设平面内进行滤波,平滑噪声,聚合同一深度平面上的局部上下文信息。这相当于对每一张深度切片单独进行图像增强。
- 卷积
- 这个卷积核只在深度维度(D)上进行卷积,在空间维度上不做任何融合。
- 作用:专注于在深度方向上扩大感受野。一个像素点在不同深度假设下的置信度分布,可以通过这个长条形的卷积核进行高效的整合。它能捕捉到深度概率分布的全局模式(比如是单峰还是多峰),这对于最终确定正确深度至关重要,而且计算量远小于使用大核的各向同性卷积。
这个阶段的妙处在于:它像用两个不同的工具分别处理不同的问题, 的“抹刀”处理平面内的不平整, 的“探针”深入深度方向去探查分布规律,两者分工明确,高效且精准。
b) 深层网络:使用各向同性卷积
在网络的深层,特征图经过浅层处理后已经变得更加抽象和规整。此时,P-MVSNet再使用标准的 各向同性卷积。
- 作用:在更深层,需要融合更加复杂的、混合了空间和深度信息的全局上下文,以做出最终的判断。此时各向同性卷积是合适的,因为它能平等地考虑所有维度上的信息,进行高层次的特征融合。
输出:潜在概率体(LPV)V2,尺寸Z×H/4×W/4,表示每个像素沿深度方向的潜在概率分布。
8. 网络中最后深度图的生成
深度图生成为"低分辨率()"与"高分辨率()"两步,基于概率加权求和(软argmin):
8.1 低分辨率深度图()
- 概率体积生成:对 沿深度方向应用softmax,得到概率体积 :
- 软argmin计算深度:
尺寸为 ,实现亚像素级深度估计。
8.2 高分辨率深度图()
结合各特征提升分辨率:
-
输入构建:将上采样后的 (双线性插值至 )与 特征 拼接,形成 通道输入
-
2D卷积插值:经1个 通道、2个 通道2D卷积(前两层BN+ReLU,最后一层无),输出高分辨率潜在概率体
-
深度计算:同理对 做softmax得 ,软argmin计算 ,尺寸为 (比 分辨率高2倍)
9. 网络中的损失函数设计
采用多尺度L1损失,联合优化低分辨率与高分辨率深度图,公式为:
- 、:、 特征的有效GT像素集(排除无GT的区域)
- 、:对应尺度的GT深度图
- :权重系数(实验中 ),平衡高低分辨率损失贡献
- 优势:L1损失对异常值鲁棒,避免平方损失放大极端误差,多尺度优化确保低分辨率深度图均逼近GT
10. 测试数据集
- DTU数据集:室内场景,124个场景,用于训练与评估。
- Tanks & Temples:真实复杂场景,用于测试泛化能力。
11. 消融实验
11.1 测试组件 1:patch-wise 匹配置信度聚合模块
- 实验设计:对比 “完整 P-MVSNet” 与 “移除聚合模块的 P-MVSNet(w/o P)”;
- 结果(以ℓ₂深度图为例):
- 平均绝对深度误差:完整版本 5.26mm vs w/o P 5.82mm(误差降低 9.6%);
- 预测精度(3σ):完整版本 90.88% vs w/o P 88.71%(精度提升 2.4%);
- 结论:patch-wise 聚合能有效利用局部上下文,降低噪声干扰,提升匹配精度。
11.2 测试组件 2:混合 3D U-Net
- 实验设计:对比 “完整 P-MVSNet(混合 U-Net)” 与 “替换为通用 3D U-Net 的 P-MVSNet(H→G)”;
- 结果(以ℓ₂深度图为例):
- 平均绝对深度误差:混合 U-Net 5.26mm vs 通用 U-Net 5.54mm(误差降低 5.0%);
- 预测精度(3σ):混合 U-Net 90.88% vs 通用 U-Net 89.25%(精度提升 1.8%);
- 结论:混合 U-Net 的各向异性卷积适配代价体几何特性,比通用 U-Net 更高效融合上下文。
11.3 与 MVSNet 的对比
- 结果:P-MVSNet(完整版本)平均绝对深度误差 5.26mm vs MVSNet 7.25mm(误差降低 27.4%),预测精度(3σ)90.88% vs MVSNet 87.96%(精度提升 3.3%);
- 结论:P-MVSNet 的两个核心模块显著优于 MVSNet 的像素级方差代价体与通用 3D U-Net。
其他创新点
- 提出“深度一致性优先”策略,提升多视图深度一致性。
- 使用两阶段训练策略(Adam → SGD),提升泛化能力。
 微信
微信- 支付宝

