
论文阅读_NeuralRecon
NeuralRecon
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | NeuralRecon |
| 作者 | Jiaming Sun, Yiming Xie, Linghao Chen, Xiaowei Zhou, Hujun Bao |
| 作者单位 | 浙江大学 |
| 时间 | 2021 |
| 发表会议/期刊 | 2021年,发表于CVPR (IEEE/CVF Conference on Computer Vision and Pattern Recognition) |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 标定之后的多视角图像 |
| 输出 | Mesh |
| 所属领域 | MeshMVS |
摘要精简
NeuralRecon是一个从单目视频进行实时、连贯3D场景重建的新框架。该方法摒弃传统 “逐帧估计深度图再融合” 的思路,直接通过神经网络增量重建局部片段的稀疏 TSDF(截断符号距离函数)体积。其核心是一个基于门控循环单元的学习型TSDF融合模块,用于融合历史片段信息。该设计使得网络在顺序重建时能捕捉3D表面的局部平滑性和全局形状先验,从而实现准确、连贯且实时的表面重建。粗到细的稀疏卷积策略,逐步优化 TSDF 精度;局部片段联合重建,避免深度图不一致和冗余计算。实验表明,NeuralRecon 在 ScanNet 和 7-Scenes 数据集上,重建精度超越现有 SOTA 方法,同时达到 33 帧 / 秒的实时速度,是首个能实时生成密集连贯 3D 几何的学习型系统。
引言:动机与出发点
传统实时3D重建流水线多采用“深度图融合”方法,即先在每个关键帧上单独估计单目深度图,再通过多视角一致性等准则滤波后融合到TSDF体积中。这种方法存在两个主要缺陷:
- 深度不一致性:每个关键帧的深度估计是独立进行的,即使视角重叠很大,也不会利用之前的估计结果。这导致不同视图间的深度尺度可能不一致,重建结果容易出现分层或散乱。
- 计算冗余:同一3D表面在不同关键帧中被反复估计,造成冗余计算。
NeuralRecon的出发点是为了克服上述问题,提出一种能够联合重建与融合、直接输出体积化表示、并保持局部与全局连贯性的实时单目重建框架。
创新点
- 直接体积化预测与联合重建-融合范式:摒弃了“先深度图,后融合”的两步式流水线,直接以局部片段(一组连续关键帧)内的所有图像为输入,联合预测一个局部TSDF体积。这迫使网络学习自然的表面先验,保证了局部片段的几何一致性。
- 基于GRU的学习型TSDF融合:提出使用3D卷积变体的门控循环单元作为融合模块。GRU的更新门和重置门以数据驱动的方式,决定将多少历史重建信息(隐藏状态)融合到当前片段特征中,以及将多少当前信息更新到隐藏状态。这替代了传统TSDF融合中简单的线性运行平均操作,实现了更智能、选择性更强的跨片段信息融合,保证了全局尺度的一致性。
- 局部片段设计与稀疏卷积:系统以“片段”为单位增量式处理视频流,每个片段包含数帧(如9帧)关键帧。这既提供了足够的视差,又避免了处理过大3D体积带来的计算负担。同时,整个网络采用3D稀疏卷积处理TSDF体积,仅对靠近表面的非空体素进行计算,极大地提升了效率。
- 由粗到精的稀疏TSDF预测:网络采用三级由粗到精的结构逐步细化TSDF预测。每一级预测的TSDF体积包含占用分数和SDF值。通过设定阈值对低置信度体素进行稀疏化,上一级稀疏化的输出经过上采样后与下一级更精细的图像特征体积拼接,输入GRU进行融合和进一步预测。
网络架构与输入输出
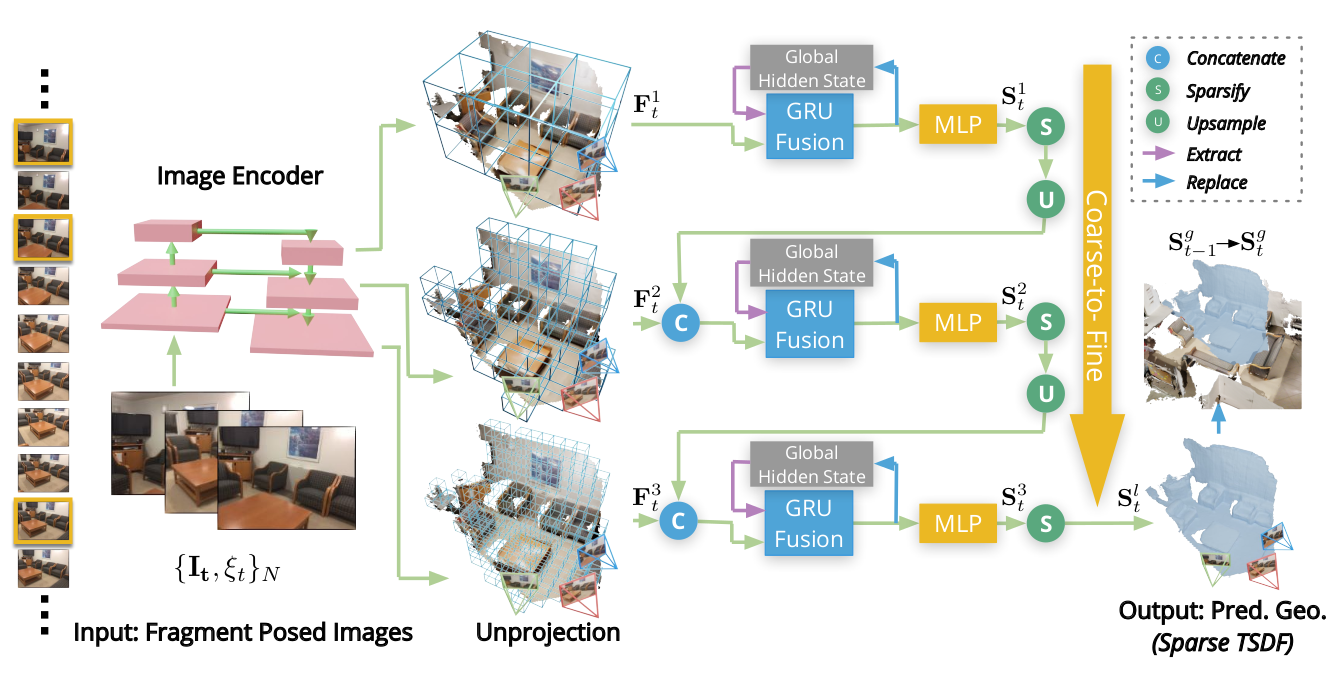
输入:一个单目视频序列的图像 及其由SLAM系统提供的相机位姿轨迹 。
输出:全局TSDF体积 ,可通过移动立方体算法实时提取网格。
架构组成
网络为端到端框架,核心由 5 个模块构成:
- 图像编码模块:基于 MnasNet(ImageNet 预训练)+ 特征金字塔网络(FPN),提取多尺度图像特征,支撑粗到细重建。
- 特征反投影模块:将多视图图像特征沿相机射线反投影到 3D 空间,按体素可见性权重(观测视图数)平均,得到 3D特征体积 。
- 由粗到精的GRU融合与TSDF预测:
- 网络包含三个由粗到精的级别。
- 在第一级,将通过稀疏卷积提取几何特征,并与初始隐藏状态(或历史隐藏状态)通过GRU融合,随后通过MLP预测稠密的TSDF体积 (包含和)。
- 在第二、三级,对上一级预测的进行稀疏化(剔除的体素)和2倍上采样,然后与当前级的图像特征体积 拼接。同样经过稀疏卷积、GRU融合和MLP,预测更精细的 。
- GRU的隐藏状态 会更新到一个在全局坐标系下维护的全局隐藏状态 中。
- 全局集成:在最后一级()预测的稀疏TSDF体积 ,经过坐标变换后,直接替换全局TSDF体积 中的对应体素。
特征提取
特征提取分为两步:
- 2D图像特征提取:使用在ImageNet上预训练的、集成了特征金字塔网络(FPN)的轻量级MnasNet变体作为主干,从输入的关键帧图像中提取多尺度2D特征图。
- 3D特征体积构建:将每个关键帧的多层级2D特征,根据相机位姿反投影到3D空间。对于世界坐标系下的一个3D体素,收集所有能观察到该体素的关键帧所反投影过来的特征,并按其可见性(能被多少视图看到)进行加权平均,最终形成3D图像特征体积 。
三维场景生成步骤
-
初始化:系统开始运行,初始化全局TSDF体积和全局隐藏状态为空。
-
片段循环:随着视频流入,当新帧与最近关键帧的相对平移 > 0.1m 或相对旋转 > 15° 时,选为关键帧;由 N 个关键帧组成局部片段,界定片段边界体积,仅覆盖所有关键帧视锥交集。
-
局部重建:对于当前片段,执行上述网络架构流程:提取特征、将片段内所有关键帧的多尺度图像特征,反投影到 FBV 内,构建 3D 特征体积 、进行三级由粗到精的GRU融合与TSDF预测,得到当前片段的局部TSDF体积 。
- 第一级:对 应用稀疏卷积,预测 dense TSDF 体积,输出占用率 o 和 SDF 值 。
- 第二、三级:将上一级 TSDF 上采样 2 倍,与当前级 3D 特征体积接,输入 GRU 融合模块(融合历史隐藏状态),再经稀疏卷积和 MLP 预测当前级 TSDF,并稀疏化低置信度体素(o<0.5)。
-
全局融合:将局部TSDF体积 (已是与历史信息融合后的结果)变换到全局坐标系,直接替换/更新全局TSDF体积 中的对应体素。
-
网格提取:在任意时刻,都可以对当前的全局TSDF体积 运行 Marching Cubes 算法,提取出三角网格模型。整个过程是增量、实时的。
损失函数
使用两种损失进行监督,并应用于所有三个由粗到精的级别:
- 占用损失(Occupancy Loss):预测的占用值与真实占用值之间的二元交叉熵(BCE)。
- SDF损失(SDF Loss):预测的SDF值与真实SDF值之间的L1距离。在计算L1损失前,对预测值和真实值都进行对数变换,减少极端值影响:
训练与测试数据集
训练数据集:主要在ScanNet数据集(包含1613个室内场景)上进行训练。
测试数据集:在ScanNet数据集和7-Scenes数据集上进行性能评估。
推理与部署的输入输出变化
- 训练阶段:通常使用一个完整序列的图像和位姿,以片段为单位进行训练,但可以访问整个序列的上下文(用于构造真值TSDF)。
- 推理/部署阶段:系统以在线、流式方式工作。输入是实时到达的视频帧和SLAM提供的实时位姿。输出是不断更新、增长的全局TSDF体积,并可实时提取网格。系统只能利用当前和历史信息,无法访问未来帧。
消融实验测试的组件
- GRU融合的有效性:对比了 (i)传统线性TSDF融合(无GRU)、(ii)对几何特征进行平均融合、(iii)使用GRU在占用区域融合、(iv)使用GRU在片段边界体积内融合。实验表明,GRU融合比平均融合效果更好,且在片段边界体积内融合能产生更完整、更一致的重建结果。
- 融合区域:对比了在“占用区域”融合与在“片段边界体积”内融合。后者能利用边界上下文信息,减少地面等区域的伪影,提高完整性和一致性。
- 局部片段中的视图数量:测试了片段包含5, 7, 9, 11个视图的效果。结果表明,使用9个视图时取得了最佳的F-score,视图过少(信息不足)或过多(可能引入不相关特征)都会导致性能下降。
其他创新点
- 实时性能:通过联合重建-融合、局部片段处理、稀疏卷积等一系列设计,在保持高精度的同时,实现了每关键帧30毫秒(33 FPS)的实时处理速度,比离线方法Atlas快约10倍,比一些实时深度估计方法快数十倍。
- 泛化能力:仅在ScanNet上训练的模型,在未见过的7-Scenes数据集上测试,仍能取得有竞争力的性能,展现了良好的泛化能力。
 微信
微信- 支付宝

