
论文阅读_MoVieS
MoVieS: Motion-Aware 4D Dynamic View Synthesis in One Second
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | MoVieS: Motion-Aware 4D Dynamic View Synthesis in One Second 一秒钟内实现运动感知 4D 动态视图合成 |
| 作者 | Chenguo Lin1∗, Yuchen Lin1,3∗, Panwang Pan2†, Yifan Yu2, Honglei Yan2, Katerina Fragkiadaki3, Yadong Mu ∗:平等贡献;†:项目负责人;‡:通讯作者。 |
| 作者单位 | 北京大学、字节跳动、卡内基梅隆大学 |
| 时间 | 20250714axiv |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 单目视频 |
| 输出 | 4D 动态新颖视图: |
| 所属领域 | 新视角生成 |
| 一句话总结做了什么 | 设计了前馈模型可在一秒钟内从单目视频中合成动态高斯然后合成4D 动态新颖视图,首次允许对外观、几何形状和运动进行统一建模 |
摘要
引言
创新点
- 在VGGT基础上,MoVieS,这是第一个前馈框架,它联合对外观、几何形状和运动进行建模,以从单目视频中感知 4D 场景。
- 提出动态飞溅像素将动态三维场景表示为可渲染的变形三维粒子,桥接新颖的视图合成和动态几何重建: 每个输入像素都映射到一个 3D 高斯图元,其 3D 位置由预测深度决定。为了对动力学进行建模,MoVieS 将每个像素的运动位移回归到任意查询时间戳,从而能够对每个飞溅像素进行时间跟踪。这种设计有助于跨摄像机视点和时间帧对 3D 几何体和外观进行连贯重建。
- MoVieS 为 4D 重建提供了强大的性能和数量级的加速,并且自然地以零样本方式实现了广泛的应用: 在各种 4D 感知任务中都取得了有竞争力的性能,同时比现有技术水平快了几个数量级。此外,通过作为代理任务的新颖视图综合,MoVieS 能够通过稀疏跟踪监督实现密集运动理解。这自然会产生各种零样本应用,进一步拓宽我们方法的潜力。
相关工作
- Feed-forward 3D Reconstruction
- DUSt3R率先将规范空间中的像素对齐点图从图像对直接回归。随后的工作通过结合特征匹配[49]、支持多视图输入[50、51、52、53]、适应流视频[54、55]或与 3DGS 桥接视图合成[56、57、52、53]来改进该框架
- VGGT通过使用更强大的图像编码器和多个特定于任务的头来预测从少至一个到数百个视图的所有关键 3D 属性。
- Dynamic Geometry Reconstruction动态几何重建
- 一种方式是工程性的:以即插即用的方式将 DUSt3R 框架扩展到动态设置[58],或者通过结合单眼深度[4,61]、光流[62]或二维点跟踪[19]来利用基础模型。
- 另一种方法是做动态点图:动态点图[63]是一项并行工作,通过预测每个视点在另一个时间戳处的点图,提出了一种时不变的 DUSt3R 变体。
- DynaDUSt3R为模型动态几何体增加了像素级运动监督。然而仅限于两帧输入,并且仅生成点云,而没有高质量的视觉重建。
- CUT3R超越两个视图使用递归模型从静态和动态场景的流视频中增量更新场景表示。
- 其他方法将动态重建视为条件视频生成,微调扩散模型以概率估计点图。但是,这些要求每个视频多个网络通行证。
- Dynamic Novel View Synthesis
- 早期的尝试利用神经辐射场NERF来表示动态场景,无论是来自多视图视频还是单目视频。
- 3DGS作为一种更高效的可渲染表示,已应用于使用具有时间维度或附加可变形场的 4D 基元进行动态视图合成。 利用场景运动的低维性质表达了运动,并学习了单目帧的高斯轨迹。然而这些方法是从头开始训练的,需要迭代优化才能适应场景。现成的点跟踪或光流模型对于提供监督信号也是必不可少的。
- 与我们最相关的工作是 BTimer和 NutWorld,它们都利用前馈方法从单目视频中估计 3DGS 属性。 然而,BTimer 在不对帧关系进行建模的情况下预测每个时间戳的独立高斯块,并且需要一个增强器模块来实现平滑的中间帧。NutWorld 对高斯运动进行建模,但缺乏明确的监督,严重依赖预训练的深度和流动,并使用正交相机,这可能会进一步导致投影失真。
方法
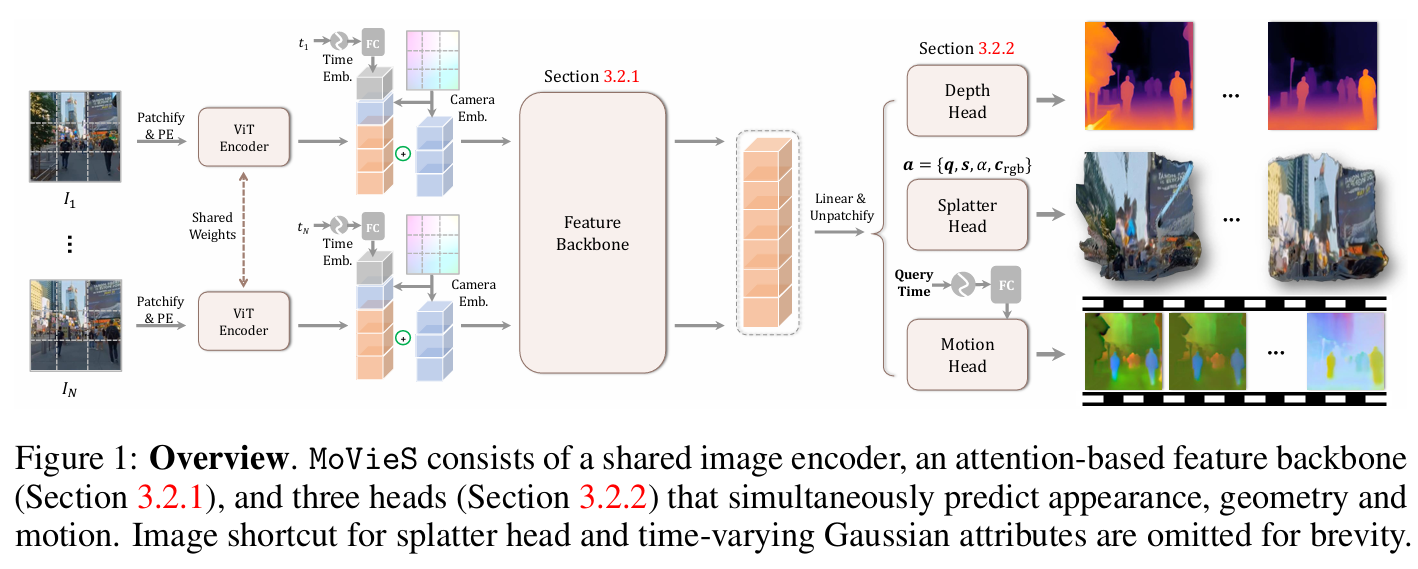 总体:一个大规模的预训练 Transformer 主干之上独立编码每个视频帧,并通过注意力聚合其信息,可同时预测外观、几何形状和运动。(1)深度头估计每个输入帧的深度,(2)飞溅头预测每像素 3D 高斯外观属性,例如颜色和不透明度,用于新颖的视图渲染,(3) 运动头估计高斯图元朝向目标时间戳的时间条件运动,使我们能够跟踪其时间演变。
总体:一个大规模的预训练 Transformer 主干之上独立编码每个视频帧,并通过注意力聚合其信息,可同时预测外观、几何形状和运动。(1)深度头估计每个输入帧的深度,(2)飞溅头预测每像素 3D 高斯外观属性,例如颜色和不透明度,用于新颖的视图渲染,(3) 运动头估计高斯图元朝向目标时间戳的时间条件运动,使我们能够跟踪其时间演变。
3.1 Dynamic Splatter Pixel
将动态场景分解为一组静态高斯基元及其相应的变形场。
- 一个视频输入,第i帧的每个像素和一个Splatter Pixel g对应,这样一个g也是在第1帧的坐标系下表示的,这样一个g有{x,a}两个属性,x是规范空间canonical space的位置,a是一个11维度的特征,有4维旋转四元数q,3维尺度s,1维不透明度α,3维颜色。但是这是静态的
- 额外的时间相关的场(time-dependent deformation field)来表征运动,一个g有一个对应的场属性m(t),m(t)={Δx(t),Δa(t)},Δx(t)是t时刻规范空间canonical space的运动向量是一个变速运动,Δa(t)是t时刻a的变化。那也就是说每个时刻t的x和a都是0时刻加一个直接的增量而不是t-1时刻的增量?没错
- 这不就是说在t时刻,一个高斯的性质是x ← x + ∆x(t), a ← a + ∆a(t)
- 在实践中发现仅使缩放和旋转属性与时间相关,即 ∆a(t)是一个7维的,不需要不透明度颜色的变化,足以表示动态飞溅像素。这就效果足够了


3.2 MoVieS: Unify Appearance, Geometry and Motion
3.2.1 Feature Backbone
- 输入一个视频,视频是一个t个时刻,视角P,相机内参K,一共N帧I的输入
- 每一帧I通过预训练的Encoder获得特征
- 相机参数通过两种方法嵌入
- Plücker embedding: 相机位姿P和相机内参K通过空间加法对图像特征进行下采样并与图像特征融合,提供了相机几何形状的密集且空间对齐的编码
- Camera token:相机位姿P和相机内参K都经过线性层生成一个相机令牌,附加到图像令牌的序列中。通过注意力与图像令牌进行全局交互,从而实现更全面的特征推理。
- 消融实验的结果:
- 使用正弦位置编码对每个时间 t∈ [0, 1]进行编码,以生成一个时间标记,然后将其与上述图像和相机标记连接起来。
- 使用 VGGT的几何预训练注意力块来实现跨视频帧的图像标记之间的交互
3.2.2 Prediction Heads
token输入三个并行的DPT head,分别估计深度,高斯特征,变化场,这里讲了其他名字外观,几何形状和运动。
- . Depth and Splatter Head:深度头是通过VGGT的深度图进一步微调,高斯特征头是从零训练的
- Motion Head:
- 通过在应用DPT卷积之前,通过自适应层归一化将正弦编码的查询时间t注入图像token,从而实现时间变化。什么意思
- 对于N个输入帧和M个查询时间戳什么意思,这生成了形状为M × N × 3 × H × W的运动图。

训练
如何训练和推理:MoVieS 可以在具有静态和动场景的大规模数据集以及点跟踪数据集上进行训练。在推理时,MoVieS 拍摄单目视频,无论是描绘静态还是动态场景,并重建每像素 3D 高斯基元及其在任何目标时间戳处的运动属性,从而在单个模型中实现新颖的视图合成、深度估计和 3D 点跟踪。
损失函数:

- Depth and Rendering Losses :深度损失计算为预测深度图和真实深度图之间的均方误差 (MSE) 及其空间梯度。深度损失计算为预测3dgs图和真实rgb图之间的像素 (MSE)和perceptual loss这个感知损失是什么?。
- Motion Loss: 在3D 点跟踪数据集,真实的 ∆x 定义为任意两帧之间每个跟踪点的 3D 位移。由于所有 3D 点都是在世界坐标中定义的,并且大多数跟踪点保持静态,这意味着它们相应的运动矢量趋于零。我们在预测运动和真实运动之间应用逐点 L1 损失,以在过滤掉输入帧中不可见的点后提高稀疏性。此外,为了补充直接的点对点对齐,引入了分布损耗,鼓励预测的运动矢量在每帧内保留内部相对距离结构。最终运动损耗定义为逐点和分布级监督的组合,就是下面这个公式。
- Normalization :与 VGGT类似,通过从每个 3D 点到规范世界坐标系原点的平均欧几里得距离来归一化 3D 场景比例。因此与其他一些重建方法不同,我们不对深度或运动损失进行额外的归一化。为了简单起见,我们还省略了置信度感知权重。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 This is a 部落格 of outbreak_sen!
- 微信
- 支付宝

