
论文阅读_MoSca
MoSca: Dynamic Gaussian Fusion from Casual Videos via 4D Motion Scaffolds
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | MoSca: Dynamic Gaussian Fusion from Casual Videos via 4D Motion Scaffolds |
| 作者 | Jiahui Lei1 Yijia Weng2 Adam W. Harley2 Leonidas Guibas2 Kostas Daniilidis1,3 |
| 作者单位 | 宾夕法尼亚大学 斯坦福大学 Archimedes, Athena RC |
| 时间 | 20241129axiv |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 无位姿单目视频 |
| 输出 | 可渲染的动态场景,表示为一组动态高斯分布,并在相机参数未知的情况下恢复其焦距和位姿。 |
| 所属领域 | 4D重建 |
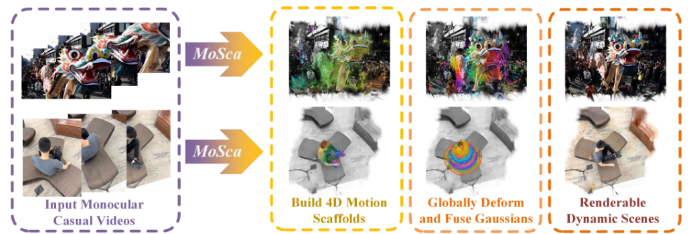
| 一句话总结做了什么 | MoSca 从任意单目视频中重建可渲染的动态场景。核心思想是将2D视频输入提升为一种新颖的4D动态场景表示形式命名为运动骨架(Motion Scaffolds, MoSca),在此表示中,所有的观测数据得以进行全局且几何一致的融合。 |
摘要
我们提出了4D运动骨架(MoSca),这是一种现代的4D重建系统,旨在从野外随意拍摄的单目视频中,重建并合成动态场景的新颖视图。为了解决这一具有挑战性且病态的逆问题,我们利用基础视觉模型中的先验知识,将视频数据格式提升到一种新颖的“运动骨架”(MoSca)表示形式,该表示紧凑且平滑地编码了底层的运动/形变。随后,场景的几何结构和外观信息从形变场中解耦,并通过融合锚定在MoSca上的高斯分布,并借助高斯点阵优化进行全局编码。此外,无需依赖其他姿态估计工具,仅通过光束法平差即可求解相机焦距和位姿。 实验表明,该方法在动态渲染基准测试中达到了最先进的性能,并在真实视频上表现出良好的有效性。
引言(没啥好看的)
由于单目拍摄视频没有位姿,这对4d重建有很大挑战:为应对这一挑战性任务,我们的
第一个洞察是利用近期预训练视觉模型的进展(见第3.2.1节),这些模型在追踪和深度估计等基础计算机视觉任务上表现出色。尽管这类知识对理解完整的动态场景至关重要,但其本身仍不充分:它无法捕捉被遮挡的场景部分,且通常存在噪声、局部性和不完整性。
我们的第二个洞察是设计一种名为MoSca的形变表示方法,该方法基于上述基础先验,并引入物理形变先验。尽管现实世界中的几何结构和外观复杂且包含高频细节,但驱动这些几何变化的底层形变通常是紧凑(低秩)且平滑的。MoSca通过将3D几何与运动解耦,利用稀疏图节点来表示形变,并通过平滑插值得以表达(见第3.1节)。
我们利用的另一个物理先验是“尽可能刚性”(as-rigid-as-possible, ARAP)形变,这可以通过MoSca的轨迹拓扑高效实现。
以上两个洞察带来了两个重要优势:
首先,MoSca可以从推断出的2D基础先验中提升至3D空间并进行优化(见第3.2.3节);
其次,所有时间步的观测结果可以进行全局融合,并用于任意查询时刻的渲染(见第3.2.4节)。当我们将不同时间观察到的所有高斯分布变形至目标查询时刻时,即可实现高斯融合,形成完整的重建结果,并通过高斯点阵(Gaussian Splatting)[44] 进行监督优化。
此外,我们的系统通过光束法平差与光度优化(见第3.2.2节)估计相机位姿和焦距,无需依赖COLMAP等外部位姿估计算法。
综上所述,本文的主要贡献可总结如下:
(1) 提出了一种可在真实场景中处理无位姿信息单目视频的全自动4D重建系统;
(2) 提出了一种新颖的运动骨架(MoSca)形变表示方法,该方法利用2D基础模型的知识构建,并通过基于物理启发的形变正则化进行优化;
(3) 提出了一种高效且显式的基于高斯的动态场景表示方法,由MoSca驱动,能够融合输入视频中所有时刻的观测信息,从而渲染出任意新视角和任意目标时刻的画面;
(4) 在动态场景渲染基准测试中实现了最先进的性能。
创新点
相关工作
- Dynamic Novel-View Synthesis
- 现有作品 都假设可用的同步多视图视频输入。另一行作品解决了单目输入的更实际设置,其中有限观察的模糊性使问题进一步复杂化。
- 神经辐射场和 3D 高斯是新视图合成的有前途的方法。后者的显式基于点的表示特别适合动态设置。我们采用 3D 高斯进行长期的全局聚合。
- Non-Rigid Structure-from-Motion非刚性
- 从单个摄像机构建非刚性变形场景是一个长期存在的问题,古早的方法是关注特制定形状的物体
- 为了对非刚性变形进行建模,最先进的方法使用嵌入式变形图[89],其中空间上的密集变换使用一组稀疏的基变换进行建模。
- 在 MoSca 中,我们扩展了经典的嵌入式图,将先验从 2D 基础模型连接到动态高斯
- 2D Vision Foundation Models
方法
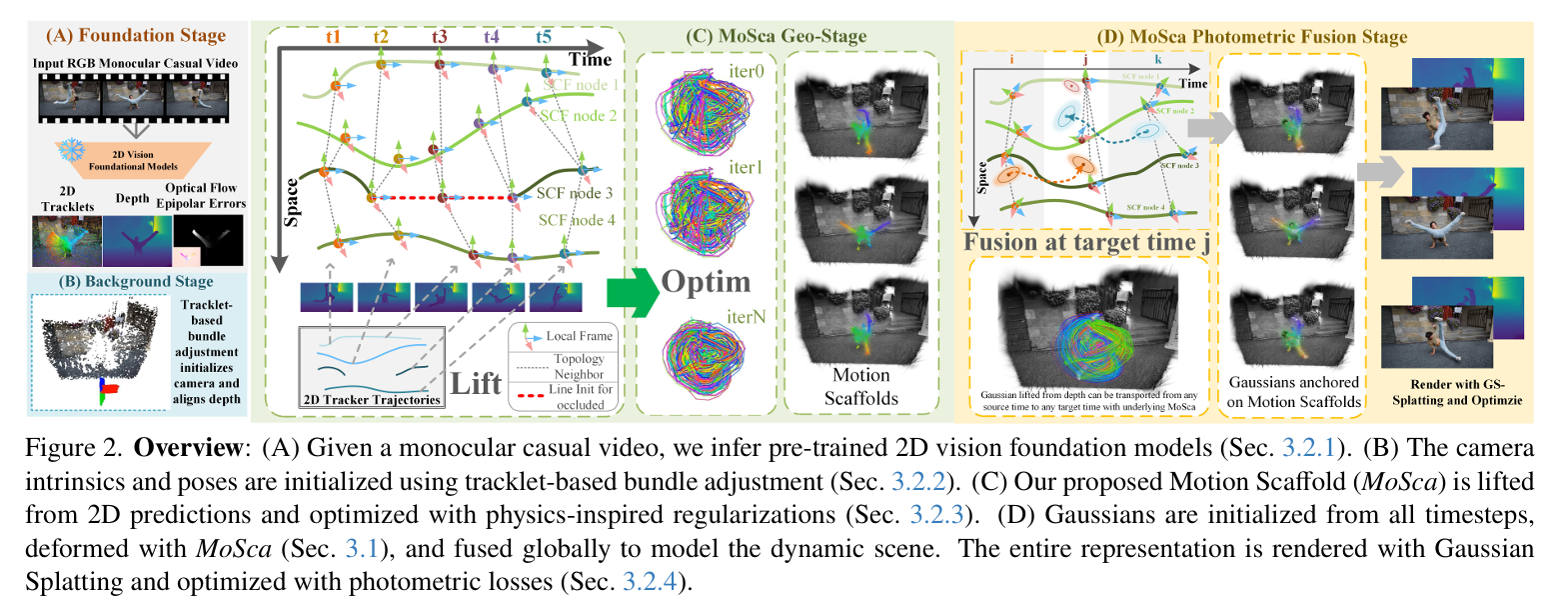
总体:
给定一个包含𝑇帧的随意拍摄的单目动态场景视频 I = [𝐼₁, 𝐼₂, …, 𝐼ₜ],重建该场景的几何结构与外观,表示为一组动态高斯分布,并在相机参数未知的情况下恢复其焦距和位姿。我们的核心思想是将2D视频输入提升为一种新颖的4D动态场景表示形式,命名为运动骨架(Motion Scaffolds, MoSca),在此表示中,所有的观测数据得以进行全局且几何一致 geometrically的融合。
- 输入单目视频,利用基础模型估计点跟踪,深度,光流RAFT
- 然后基于跟踪点的使用BA光束平差法初始化相机内外参数,通过3DGS重建背景
- (C)优化mosca
- (D)初始的3dGS+mosca=4dgs,这个3dgs从所有时间全局渲染,3dgs通过mosca变形场全局融合就获得了动态场景
3.1. Deformation Representation with MoSca
如前面描述,这里的MoSca是一个之前非刚性形变里面的一种嵌入图(Embedding Graph)的表示,这个图的表示:
- 图(Graph) 是由节点(Nodes/Vertices) 和边(Edges) 组成的数据结构。图是一个轨迹,这个轨迹上有很多节点,轨迹之间是边
- 节点Nodes是代表空间中的关键点或控制点,例如物体表面的某些特征位置。MoSca中的节点一个六自由度的轨迹,每个节点有一个全局变换和控制半径。嵌入图通过引入稀疏控制点(图节点)来降低自由度,并通过边上的约束(如ARAP:As-Rigid-As-Possible)施加物理合理性,防止过度扭曲。
- 边Edges 表示节点之间的空间或时间上的连接关系,可以编码邻近性、运动一致性或物理约束。MoScan中边表示的是估计的局部邻域。对于图中未定义节点的空间位置,可以通过基于边权重的插值(如拉普拉斯坐标插值、径向基函数RBF)计算其形变,从而恢复出稠密的每帧几何。
- 为什么说是嵌入图,因为指的是将高维、复杂的运动信息(如像素级光流、深度变化、3D位移)映射到一个低维、结构化的表示空间中。
- 嵌入图提供了一个时空一致的参考框架。不同时间步观测到的3D点(如来自SLAM或立体匹配)可以“锚定”到图节点上,实现全局优化和长期一致性。
- 至于MoSca是如何定义节点和边的,看下面的截图
在MoSca中:
假设你要重建一个人跳舞的视频:
- 原始输入:单目视频,每一帧都是2D图像,无深度、无相机位姿。
- 构建嵌入图:
- 使用特征跟踪找到一些稳定的关键点轨迹。
- 将这些轨迹聚类或采样,形成图的节点(如头部、手臂、腿部各设一个节点)。
- 节点之间按身体结构连接成边。
- 每个节点存储一个“形变嵌入向量”,表示该部位随时间的运动模式。
- 所有其他非节点位置的形变,通过插值得到。
- 最终,整个人体的非刚性运动就被这个“嵌入图”高效地表示出来。

3.2. Reconstruction System
3.2.1 Leveraging Priors from 2D Foundation Models
这里讲了有哪些先验,单目视频输入到哪些基础模型获得了哪些信息。

3.2.2 Camera Initializaition
提出了一种基于轨道的束调整,以稳健地初始化相机焦距和位姿。
- 首先根据光流的估计找到轨迹上不是前景的像素点,也就是找到场景里不动的点
- 然后不动的点根据深度图就可以获得三维点了
- 然后不就可以通过这些三维点最小化重投影误差估计相机内参和相机位姿,当然这里也有一些其他的操作,具体就是说怎么解决深度图估计的错误


3.2.3 Geometric Optimization of MoSca
这个Arxiv版本和实际发布版本不一样,我两个结合着看所以会跳。
3D Lift and Initialization.
其实就是
- 首先光流图上首先通过基线误差估计出这个像素轨迹T中不是前景的部分,也就是不会动的部分
- 然后不会动的跟踪像素,并且是可见的像素通过深度值从图像二维变为三维
- 然后如何说这个跟踪像素在这一帧不可见,那么就通过前后帧进行插值获得三维坐标
- 然后这样一个不会动的跟踪像素变成了一个不会动的跟踪三维信息Pt,这个Pt还要乘以相机逆和相机位姿
- 然后利用这个Pt和初始化旋转和初始化控制半径就组成了[I,Pt,r],这不就是一个节点吗,这样就初始化了MoSca
Geometry Optimization.
这里是说如何对初始化之后的MoSca进行几何优化,


3.2.4 Photometric Optimization of MoSca
这里是讲的光度优化了
Dynamic Scene Representation.
MoSca 的一个重要特点是,其全局变形场可以全局随时变换点,从而能够将所有观察到的视频帧融合成一个单一的相干表示。在系统的最后一步,优化后的 MoSca 收集从所有时间步长的反向投影前景深度点初始化的 3D 高斯。这里定义了3dgs的属性

Photometric Optimization.

NodeControl.

- 微信
- 支付宝

