
论文阅读_MeshMVS
MeshMVS
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | MeshMVS(Multi-View Stereo Guided Mesh Reconstruction) |
| 作者 | Rakesh Shrestha, Zhiwen Fan, Qingkun Su, Zuozhuo Dai, Siyu Zhu, Ping Tan |
| 作者单位 | 西蒙弗雷泽大学(Simon Fraser University) |
| 时间 | 2021 |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 标定之后的多视角图像 |
| 输出 | Mesh |
| 所属领域 | MeshMVS |
一、 摘要精简
本文提出了一种新颖的多视角网格生成方法。与以往仅利用彩色图像语义特征的工作不同,该方法通过引入多视角立体视觉(MVS)的深度特征来显式地利用几何信息,从而提升重建准确性。具体流程是:首先从多视角彩色图像预测一个粗略的体素占用网格;然后,利用图卷积网络(GCN),以多视角立体预测的深度图与当前网格渲染深度图的对比特征作为指导,对这个粗略网格进行由粗到精的细化。该方法在ShapeNet数据集上显著优于当时的最佳方法。
二、 引言与出发点
现有深度学习 - based 3D 形状生成方法存在两大核心问题:
- 依赖彩色图像的语义特征进行形状生成,这些特征仅隐式编码 3D 几何信息,限制了重建形状的准确性,尤其在低纹理、复杂拓扑区域表现不佳;
- 多视角 Mesh 重建方法(如 Pixel2Mesh++)采用固定拓扑的初始模板(椭球体)进行变形,难以适配拓扑与模板差异较大的物体,导致后续细化模块无法修正拓扑偏差。
因此,本文的出发点是:通过显式融入多视角立体匹配的几何信息,替代单纯依赖 RGB 语义特征;采用可灵活表示复杂拓扑的体素网格作为初始形状,而非固定模板,从而突破现有方法的拓扑限制与几何信息缺失问题,提升 Mesh 重建的准确性与拓扑适应性。
四、 网络架构构成
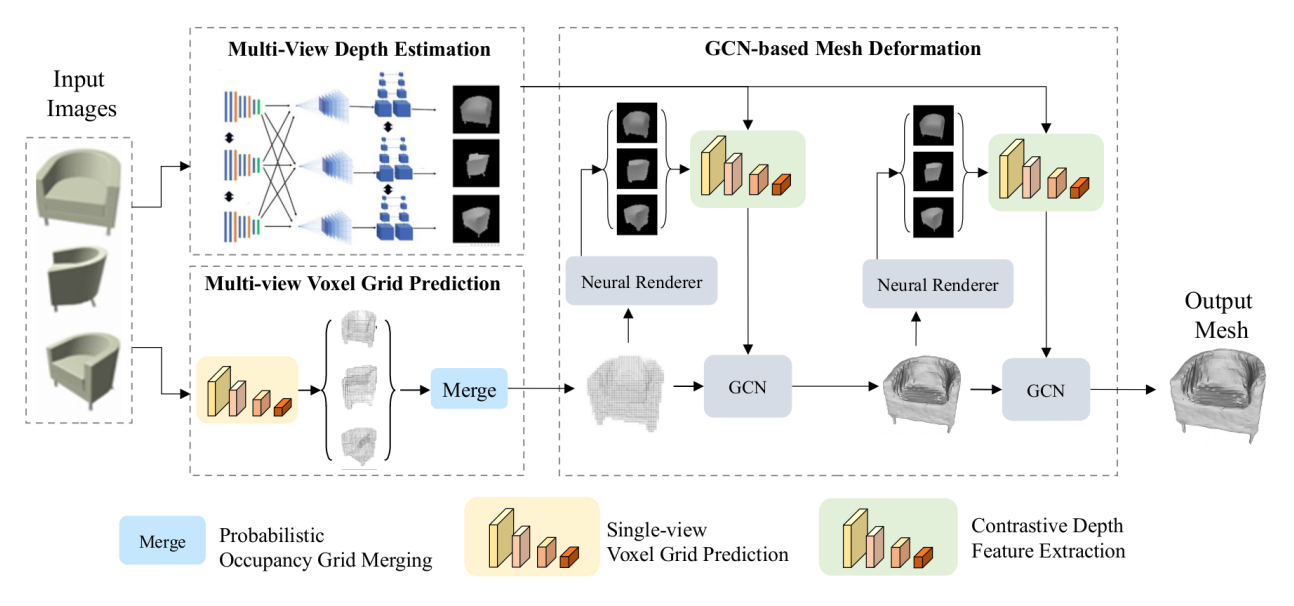
系统分为两大模块,以由粗到精的方式工作:
- 多视角体素网格预测模块:
- 对每个输入的单视角RGB图像,使用一个共享权重的网络预测一个体素占用网格
- 将所有单视角预测的体素网格变换到同一坐标系后,采用一种概率占用法进行融合,得到最终的多视角粗糙体素网格。
- 通过Cubify操作将融合后的体素网格转换为一个初始的Mesh。
- 另外通过一个MVSNet预测每个视角的真实深度图
- 网格细化模块:
- 使用一个基于图卷积网络(GCN)的细化网络,对初始网格的顶点位置进行多次迭代变形。
- GCN的顶点特征由两部分构成:顶点3D坐标 + 多视角特征。
- 多视角特征来源于对比深度特征(Mesh投影深度图+真实深度图)与RGB感知特征的结合。
- 使用基于注意力的多视角特征池化方法来融合来自不同视角的特征。
创新点
核心创新点
- 概率多视角体素网格融合:借鉴机器人领域的占用图构建技术,将各视角预测的体素网格通过对数几率(log-odds)转换进行概率融合,解决单视角遮挡导致的可见性限制,生成拓扑更准确的粗粒度体素模型。
- 对比深度特征引导细化:引入 MVS 网络预测的深度图与中间 Mesh 的渲染深度图,构建对比输入,通过 VGG-16 提取对比深度特征,为 GCN 提供显式几何约束,引导 Mesh 顶点向真实几何位置变形。
- 注意力机制多视图特征融合:采用多头注意力机制融合多视角的 RGB 特征与对比深度特征,该机制对输入视角的顺序和数量具有不变性,适配不同视角配置。
- 粗到精 GCN Mesh 变形:以体素网格转换的粗 Mesh 为初始,通过多阶段 GCN 迭代细化,每阶段利用融合特征优化顶点位置,同时约束表面法向量与边长,避免 “飞点” 和不规则面。
网络架构构成
网络整体采用 “粗模型预测→细模型细化” 的两阶段架构,流程如下:
- 输入:多视角彩色图像(已知相机内参和外参)、各视角对应的渲染深度真值(训练阶段)。
- 多视角体素网格预测:
- 单视角体素分支:通过 ResNet 提取特征,全卷积网络预测 48×48×48 分辨率的体素占用网格;
- 概率融合:将各视角体素网格转换为对数几率(log-odds),求和后通过 sigmoid 函数得到多视角融合的体素占用概率网格。
- 粗 Mesh 生成:对融合后的体素网格执行 cubify 操作,转换为初始粗 Mesh。
- Mesh 细化模块:
- MVS 深度预测:扩展 MVSNet,预测所有输入视角的深度图;
- 对比深度特征提取:拼接 MVS 预测深度图与当前阶段 Mesh 的渲染深度图,通过 VGG-16 提取特征;
- 多视图特征融合:采用多头注意力机制聚合多视角的 RGB 特征与对比深度特征;
- GCN 迭代细化:3 个 GCN 块依次对粗 Mesh 进行变形,每块输出更精细的 Mesh。
- 输出:最终结构化三角形 Mesh(顶点集 V + 面集 F)。
五、 特征提取方法
特征提取涵盖 RGB 语义特征、对比深度特征两大类型,结合多视图融合策略,具体如下:
- RGB 语义特征:通过 ResNet 提取每个视角彩色图像的层级特征,捕捉图像的语义与纹理信息,为 Mesh 变形提供外观约束。
- 对比深度特征:
- 深度输入构建:每个视角包含两类深度图 ——MVSNet 预测的真实场景深度图、当前 GCN 阶段 Mesh 的渲染深度图(通过可微分渲染生成);
- 特征提取:将两类深度图拼接后输入 VGG-16,提取 4800 维 / 视角的层级特征,捕捉几何差异信息;
- 多视图融合:通过 5 个注意力头组成的多头注意力机制,聚合所有视角的对比深度特征与 RGB 特征,输出 480 维融合特征(对视角数量和顺序不敏感)。
- 顶点特征构建:将融合后的多视图特征,与 Mesh 顶点的 3D 世界坐标拼接,作为 GCN 的节点特征,实现几何与外观信息的联合约束。
- 这种“对比”机制让网络能够直接学习当前网格渲染深度与真实几何推测深度之间的差异,从而更精准地指导顶点变形。
六、 Mesh生成方式
Mesh是通过渐进式变形生成的:
-
初始Mesh生成:由融合后的粗糙体素网格通过
Cubify操作直接转换而来,拥有正确的初始拓扑,将每个占用体素转换为小立方体(含 8 个顶点和 12 条边),所有小立方体拼接形成初始粗 Mesh,该过程可微分,支持端到端训练。 -
GCN 迭代细化:
- 图结构定义:Mesh 的顶点作为 GCN 节点,边作为图连接,节点特征为 “多视图融合特征 + 顶点 3D 坐标”;
- 特征传播:每个 GCN 块通过图卷积传播邻域顶点特征
- GCN变形:在每个GCN块中,顶点特征通过图卷积在邻域间传播,最终通过一个顶点细化层更新顶点坐标。公式如下:
其中 是当前顶点坐标, 是该顶点的特征向量, 是可学习参数。通过多个GCN阶段的逐步变形,得到最终精细的网格。
-
最终 Mesh 输出:经过 3 个 GCN 块细化后,输出满足几何约束(法向量一致、边长合理)的结构化三角形 Mesh,训练时可选择是否添加边长正则以避免 “飞点”。
七、 Loss函数设计
总损失函数是多个加权损失的加权和:
具体包括:
- 网格损失:监督最终输出,与真值网格比较。
- 倒角距离损失 (): 度量预测 Mesh 与真值 Mesh 顶点的最近邻距离,约束整体形状一致性,近预测网格与真值网格点云的距离。
- 法向损失 (): 度量预测 Mesh 与真值 Mesh 顶点法向量的差异,约束表面平滑性,保证局部表面朝向正确。
- 边长度损失 (): 正则化项,防止出现过长边和“飞点”,使网格更美观。
- 深度损失 ():BerHu 损失,度量 MVSNet 预测深度与渲染深度真值的差异,平衡 L1 与 L2 损失
- 对比深度损失 ():使用BerHu损失最小化网格渲染深度与MVS预测深度之间的差异,这是驱动网格向准确几何变形关键。
- 体素占用损失 ():交叉熵损失,监督体素占用概率与真值的差异,约束粗模型拓扑准确性,
8. 网络在哪些数据集上测试了
测试数据集为 ShapeNet 子集(源自 3DR2N2 的数据集划分):
- 数据规模:50K 3D CAD 模型,涵盖 13 个语义类别(沙发、橱柜、椅子、枪支、汽车等);
- 数据形式:每个模型从 24 个随机相机视角渲染彩色图像(透明背景),同步提供相机内参、外参,测试时使用渲染的深度图作为真值;
- 评估指标:F1-score(阈值τ=10−4m2和2τ)、Chamfer 距离(越小越好);
- 测试设置:按 Mesh R-CNN 的训练 / 测试 / 验证划分,评估不同视角数量、初始形状、特征提取方式对性能的影响。
9. 网络在哪些数据集上训练了
训练数据集与测试数据集一致,即 ShapeNet 子集:
- 训练数据:79 个训练扫描对应的 3D 模型及 24 视角渲染图像、深度真值;
- 训练流程:先独立训练 MVSNet 深度预测模块 30 个 epoch,冻结其权重后,联合训练整个 Mesh 生成网络 40 个 epoch;
- 数据增强:无额外数据增强,依赖多视角融合与多损失约束提升泛化性。
10. 推理和部署在数据输入输出有什么变化
- 训练阶段输入:多视角(如3视图)的RGB图像 + 对应的相机内外参数。
- 训练阶段真值:物体的3D网格模型(用于计算网格损失)、渲染的深度图(用于计算深度损失)。
- 推理/部署阶段输入:多视角RGB图像 + 对应的相机参数。
- 推理/部署阶段输出:预测的物体三角形网格 ( )。
十、 消融实验测试的组件
论文进行了详尽的消融实验以验证各组件贡献:
- 初始形状的影响:对比了使用单位球体、由预测深度图反投影得到的点云生成的体素、以及本文提出的CNN预测+概率合并的体素作为初始形状的效果。本文方法最优。
- 方法组件的增量贡献:逐步添加“多视角体素预测”、“对比深度特征输入”、“注意力池化”、“对比深度损失”等组件,均带来精度提升。
- 对比深度特征的形式:比较了“输入拼接”、“输入差值”、“特征拼接”、“特征差值”、“仅用预测深度特征”、“仅用渲染深度特征”等多种特征构造方式。“输入拼接”(即本文方法)效果最好。
- 输入视角数量的影响:测试了训练和测试时使用不同数量视图(2,3,4,5,6)的效果。增加训练视图数能持续提升性能;测试时,视图数少于训练时会显著下降,多于训练时则提升不明显。
- 深度预测分辨率:测试了不同深度假设平面数量(即深度图分辨率)的影响,发现在一定范围内对最终网格精度影响不大。
- 泛化能力:测试了在训练集中剔除某个类别后,模型在该类别上的重建性能,证明了较好的跨类别泛化能力。
三、PPT展示
- 输入输出
训练阶段输入:多视角的RGB图像 + 对应的相机内外参数。
训练阶段真值:物体的3DMesh、渲染的深度图。
部署阶段输入:多视角RGB图像 + 对应的相机参数。
部署阶段输出:预测的物体三角形网格Mesh。 - 系统分为两大模块,以由粗到精的方式工作:
- 多视角体素网格预测模块:
对每个输入的单视角RGB图像,使用一个共享权重的网络预测一个体素占用网格484848
利用这些已知的相机位姿将所有单视角预测的体素网格变换到同一坐标系后,采用一种概率占用法进行融合,得到最终的多视角粗糙体素网格。
通过Cubify操作将融合后的体素网格转换为一个初始的Mesh。
另外通过一个MVSNet预测每个视角的真实深度图 - 网格细化模块:
使用一个基于图卷积网络(GCN)的细化网络,对初始网格的顶点位置进行多次迭代变形。但是无法创建新顶点或改变连接方式,只能改距离。
GCN的顶点特征由两部分构成:顶点3D坐标 + 多视角特征。最后的mesh分辨率不超过484848
多视角特征来源于对比深度特征(Mesh投影深度图+真实深度图)与RGB感知特征的结合。
使用基于注意力的多视角特征池化方法来融合来自不同视角的特征。
- 多视角体素网格预测模块:
- 训练/测试数据集为 ShapeNet 子集
- Loss包含:Mesh的顶点倒角距离,顶点法向,MVSNet深度损失,体素占用损失
 微信
微信- 支付宝

