
论文阅读_MVSNet
MVSNet
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | MVSNet: Depth Inference for Unstructured Multi-view Stereo |
| 作者 | 姚姚1罗子欣1,李世薇1,天方2,以及 Long Quan |
| 作者单位 | 香港科技大学 |
| 时间 | 2018 |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 标定之后的多视角图像 |
| 输出 | 场景的点云图,每个视角的法线和深度图 |
| 所属领域 | MVS |
1. 摘要精简
本文提出一种端到端深度学习架构 MVSNet,用于从多视图图像推断深度图。流程为:先提取深度视觉图像特征,通过可微单应性扭曲在参考相机视锥上构建 3D 代价体,再用 3D 卷积正则化并回归初始深度图,结合参考图像优化得到最终结果。该架构通过基于方差的代价度量适配任意 N 视图输入,在大规模室内 DTU 数据集上,经简单后处理显著优于现有方法且速度快数倍;在复杂室外 Tanks and Temples 数据集上(2018 年 4 月 18 日前)无需微调即排名第一,展现强泛化能力。
2. 引言中的研究出发点
多视图立体匹配(MVS)是计算机视觉核心问题,需从重叠图像估计密集表示。传统方法依赖手工设计的相似性度量(如归一化互相关)和工程化正则化(如半全局匹配),虽在理想朗伯场景效果较好,但存在明显局限:低纹理、镜面和反射区域导致密集匹配困难,重建不完整,现有顶尖算法在重建完整性上仍有较大提升空间。
卷积神经网络(CNNs)的成功为立体重建提供新方向:基于学习的方法可引入全局语义信息(如镜面、反射先验)实现更稳健匹配,且在双视图立体匹配中已超越传统方法。但将双视图学习扩展到多视图面临挑战:MVS 输入图像相机几何结构任意,难以直接应用学习方法;现有少数基于 CNN 的 MVS 方法(如 SurfaceNet、LSM)采用规则网格体素表示,受 3D 体素巨大内存消耗限制,难以规模化(仅处理低分辨率数据或需耗时分治策略),当前 MVS 基准测试领先位置仍由传统方法占据。因此,本文提出 MVSNet 以解决上述痛点。
3. 创新点
- 基于参考相机视锥构建 3D 代价体,而非传统规则欧氏空间,更适配深度图推断任务。
- 提出基于方差的代价度量,将多个特征映射为单个代价特征,实现对任意数量输入视图的灵活适配。
- 将 MVS 重建解耦为 “单视图深度图估计” 的小问题,突破体素表示的内存限制,支持大规模场景重建。
- 引入可微单应性扭曲操作,将相机几何信息隐式编码到网络中,连接 2D 特征提取与 3D 正则化网络,实现端到端训练。
4. 网络架构构成
MVSNet 架构遵循相机几何规则,核心流程分四步,整体为 “特征提取→代价体构建→代价体正则化→深度图生成与优化”:
- 特征提取:用共享权重的 8 层 2D CNN 处理参考图像与源图像,输出多组 32 通道特征图。
- 代价体构建:通过可微单应性扭曲将所有特征图映射到参考相机的不同正面平行平面,形成特征体;再用基于方差的度量聚合为 3D 代价体。
- 代价体正则化:采用类 3D UNet 的四尺度编码器 - 解码器结构,通过 3D 卷积精炼代价体,经 softmax 得到概率体。
- 深度图生成与优化:从概率体通过 “软 argmin” 得到初始深度图,再用深度残差学习网络结合参考图像优化边界,得到最终深度图;同时计算初始与优化深度图的损失以训练网络。
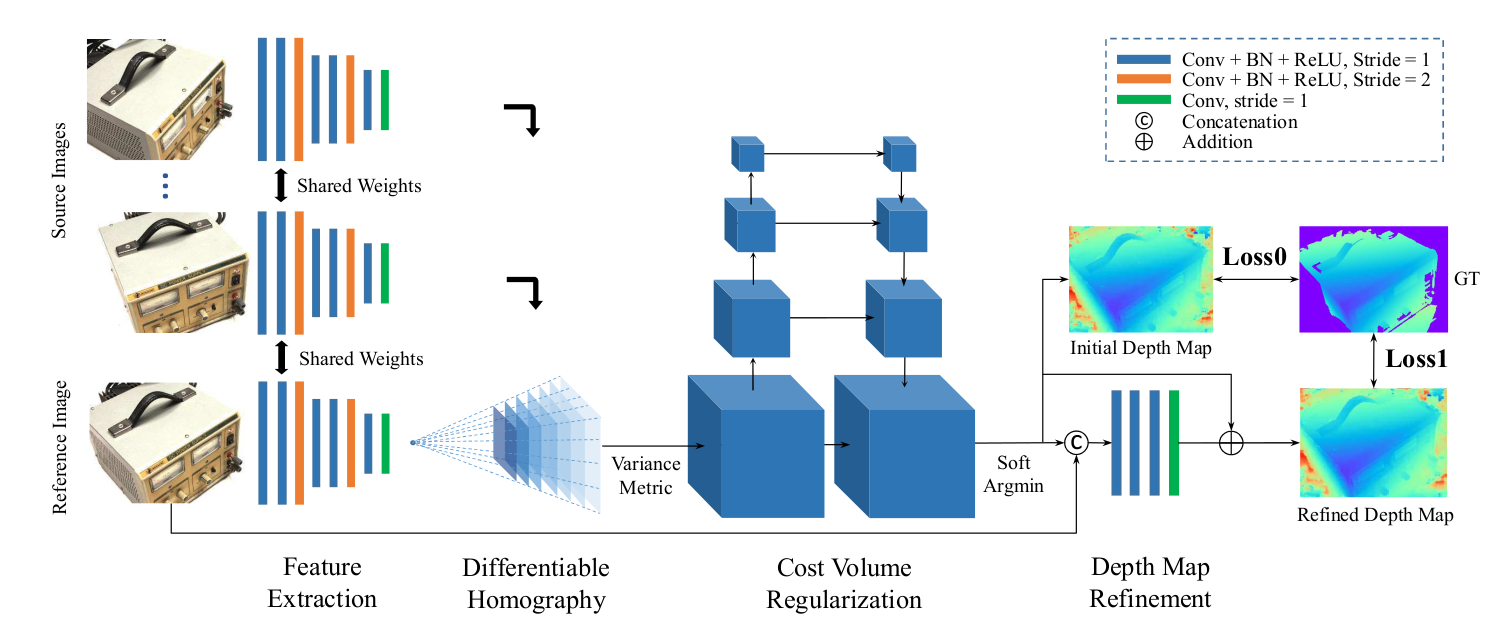
5. 网络中的特征提取
MVSNet 采用 8 层 2D CNN 提取输入图像(共 N 张,含 1 张参考图、N-1 张源图)的深度特征,具体设计如下:
- 网络分层与尺度:第 3、6 层步长设为 2,将特征塔分为三个尺度;每个尺度内包含 2 个卷积层,用于提取更高层次图像表示。
- 激活与归一化:除最后一层外,每个卷积层后紧跟批量归一化(BN)层和 ReLU 激活函数,增强训练稳定性与非线性表达。
- 权重共享与输出:所有图像的特征提取网络共享参数,提升学习效率;最终输出 N 张 32 通道特征图,各维度尺寸为输入图像的 1/4(因步长压缩)。
6. 代价体构建
- 使用可微单应性变换将源图像特征变换到参考相机视锥体中:
- 使用方差度量融合多视角特征体:
设特征体尺寸为
7. 代价体正则化
-
使用类似 3D U-Net 的四尺度编码器-解码器结构进行正则化。
-
通过 3D CNN 将代价体转换为概率体,最后一层使用 softmax 沿深度方向归一化。
-
网络结构:采用类 3D UNet 的四尺度编码器 - 解码器结构,编码器通过步长为 2 的 3D 卷积缩小特征图尺寸、扩大感受野,解码器通过上采样与编码器特征融合,聚合邻域信息。
-
通道与计算优化:为降低内存与计算成本,第一个 3D 卷积层将 32 通道代价体缩减为 8 通道,且每个尺度内的卷积层数量从 3 层减至 2 层。
-
概率归一化:最后一个卷积层输出 1 通道体素,沿深度方向应用 softmax 函数,得到概率体P——P(d)表示某像素属于深度d的概率。该概率体既可用于深度估计,也能衡量估计置信度。
8. 深度图生成
- 不采用不可微的 “赢者通吃”(argmax)操作,而是通过 “软 argmin”(概率加权求和)计算深度,公式为:初始深度图通过概率体的期望值计算(soft argmin):
- 使用参考图像引导的 2D CNN 对初始深度图进行细化,提升边界精度。深度方向的概率分布可反映估计质量:正确匹配的像素概率集中于单一峰值,虚假匹配的像素概率分散。基于此,计算 “概率图”—— 对每个像素,求和其 4 个最近深度假设的概率,作为该像素深度估计的置信度,用于后续异常值过滤。
9. 损失函数
使用初始深度图和细化深度图的绝对差异损失:MVSNet 的损失函数同时考虑 “初始深度图” 与 “精炼深度图” 的误差,确保两者均逼近真值,具体设计如下:
- 损失类型:采用平均绝对误差(MAE),对异常值更鲁棒,避免平方误差放大极端值影响。
- 有效像素约束:仅计算 “有有效真值标签的像素”
其中 。
10. 测试数据集
- DTU 数据集:大规模室内多视图数据集,含 100 + 场景(不同光照条件),提供带法向信息的真值点云。实验设置:79 个场景为训练集,18 个为验证集,22 个为测试集;输入视图数N=5,图像尺寸 1600×1184,深度采样数D=256。定量评估用 “距离度量”(平均距离,值越小越好)和 “百分比度量”(1mm/2mm 阈值下的准确率、完整性、F1 分数,值越大越好),结果显示 MVSNet 在完整性和整体质量上显著优于 Gipuma、SurfaceNet 等方法。
- Tanks and Temples 数据集:复杂室外多视图数据集,场景含自然景观、人造建筑等,更贴近真实环境。实验设置:使用 DTU 训练的模型,无需微调,输入视图数N=5,图像尺寸 1920×1056,深度范围由 OpenMVG(SfM 软件)恢复的稀疏点云和相机位置确定。结果显示,2018 年 4 月 18 日前,MVSNet 在该数据集中间集的所有提交中排名第一,优于 Pix4D(商业软件)、COLMAP(开源方法)等。
11. 消融实验
- 消融实验以 “验证损失” 为衡量指标(基于 DTU 的 18 个验证集场景,设置N=3、图像尺寸 640×512、D=256),测试 4 个核心组件的作用:
- 输入视图数量:测试三种情况2,3,5,结果显示视图数越多,验证损失越低;且训练时用N=3的模型,在N=5测试时性能仍优于N=3,证明模型可灵活适配不同视图数。
- 图像特征提取方式:对比 “8 层 2D CNN” 与 “单一层 7×7 卷积(模拟传统补丁特征)”,前者验证损失显著更低,证明基于学习的特征提取能提升重建质量。
- 代价度量类型:对比 “方差度量” 与 “均值度量”,方差度量收敛更快且验证损失更低,证明显式衡量多视图特征差异的合理性。
- 深度图优化模块:对比 “有无深度残差学习”,优化模块虽对验证损失影响较小,但在 DTU 测试集上,1mm 阈值 F1 分数从 75.58 提升至 75.69,2mm 阈值从 79.98 提升至 80.25,证明其能改善边界精度。
其他创新点
- 概率图用于质量评估:通过概率分布衡量深度估计质量,用于后处理滤波。
- 高效运行速度:在 DTU 数据集上比传统方法快数倍至数百倍。
- 无需微调泛化能力强:在 Tanks and Temples 上排名前列,无需针对该数据集训练。
 微信
微信- 支付宝

