
论文阅读_MVSFormer
MVSFormer
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | MVSFormer: Multi-View Stereo by Learning Robust Image Features and Temperature-based Depth |
| 作者 | Chenjie Cao, Xinlin Ren, Yanwei Fu |
| 作者单位 | 复旦大学数据科学学院 |
| 时间 | 2023 |
| 发表会议/期刊 | CVPR |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 多视角 |
| 输出 | 参考视角深度图 |
| 所属领域 | MVS |
摘要
本文提出 MVSFormer,一种基于预训练 Vision Transformer(ViT)增强的多视图立体(MVS)方法。核心创新包括:利用 ViT 的长距离依赖建模能力提升反射和无纹理区域的特征表示;提出高效多尺度训练策略,适配不同输入分辨率;通过温度调节策略统一分类式(鲁棒但精度有限)和回归式(精度高但置信度不可靠)深度预测的优势。MVSFormer 包含两种变体:微调分层 ViT(Twins)的完整版,以及冻结自监督 ViT(DINO)权重的轻量版(MVSFormer-P)。该方法在 DTU 数据集上实现 SOTA 性能,在 Tanks and Temples 的 Intermediate 和 Advanced 集均排名第一,泛化性优异。
引言动机
现有 MVS 方法面临三大核心痛点,推动作者开展研究:
-
特征表示不足:传统 FPN(含预训练 CNN)难以建模反射、无纹理区域,缺乏全局语义理解,限制泛化能力;
-
ViT 潜力未发掘:ViT 在 2D 视觉任务中表现突出,具备长距离依赖建模和 patch 级特征匹配优势,但尚未被系统应用于 MVS 的特征学习;
-
深度预测权衡:分类式方法(argmax)能生成可靠置信度图但深度精度有限,回归式方法(soft-argmin)精度高但置信度不可靠,难以兼顾两者优势。
作者旨在通过 ViT 增强特征提取、多尺度训练适配高分辨率、温度策略统一两类预测方法,解决上述问题,实现高精度、高泛化性的 MVS 重建。
创新点
1. 预训练ViT增强的特征提取
- 首次系统探索预训练ViT在MVS中的应用
- 使用层次化ViT (Twins)和普通ViT (DINO)两种变体
- ViT特征与FPN特征互补,结合全局理解和局部细节
2. 高效多尺度训练策略
- 针对 ViT 缺乏平移不变性、易过拟合特定分辨率的问题,设计动态分辨率训练:输入分辨率在 512-1280 间随机采样,长宽比 0.67-0.8,结合梯度累积平衡批次大小与内存消耗;
- 使用梯度积累平衡不同分辨率的批次大小
- 该策略使模型能泛化到训练时未见过的高分辨率(如 2K),无需额外微调,解决 MVS 对不同输入尺度的适配难题。
3. 基于温度的深度预测
- 训练时采用分类损失(交叉熵)优化,保证置信度可靠性;测试时通过温度参数t调节概率分布
- 早期阶段使用高温度(类似CLA)(如 5),模拟分类式全局区分能力;
- 后期阶段使用低温度(类似REG)(如 1),模拟回归式局部平滑精度,实现 “先分类后回归” 的优势融合。
- 温度设置:
4. ViT 增强的双轨特征提取架构
- 提出两种 ViT 融合方案,互补 FPN 的局部特征与 ViT 的全局特征:
- MVSFormer(完整版):采用分层 ViT(Twins)作为骨干,微调预训练权重,其高效注意力机制(分离式局部分组注意力 + 全局子采样注意力)适配多尺度特征学习,输出与 FPN 最高层特征元素相加融合;可训练的Twins ViT,性能最优
- MVSFormer-P(轻量版):冻结自监督 ViT(DINO)权重,利用 [CLS] token 的注意力图(含语义分割先验),通过 GLU 模块保护关键特征并降维,避免重训练的高计算成本。冻结的DINO ViT,计算效率高
网络架构
其实就是一个加了VIT特征的VISMVSNet,然后transformer特征太小,需要加进去的话需要操作一下,用GLU
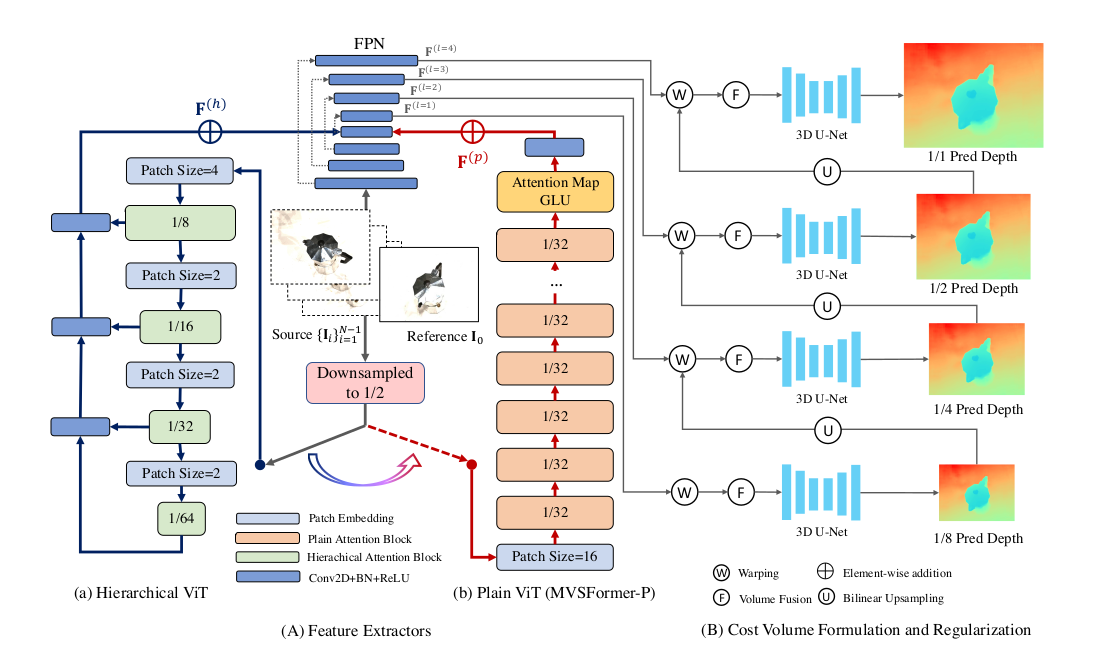
MVSFormer 遵循 “特征提取→代价体构建→正则化→深度生成” 的经典 MVS 流程,核心分为三大模块:
-
特征提取模块:FPN 与 ViT(Twins/DINO)双轨融合,输出 4 个尺度(1/8~1×)的增强特征;
-
代价体处理模块:含多阶段代价体构建(warping、相关性计算、可见性融合)与 3D U-Net 正则化;
-
深度生成模块:基于温度调节的概率期望计算,输出最终深度图。
输入为 1 张参考图 + N 张源图(含内参 / 外参),流程为:多尺度特征提取→逐阶段代价体构建与正则→温度调节深度预测→置信度过滤与点云融合。
特征提取
-
FPN主干:提取多尺度特征 ,分辨率从1/8到原始尺寸 4 个尺度特征
-
ViT增强:
-
MVSFormer:层次化VIT Twins-small 处理 1/2 分辨率输入,输出多尺度特征经额外 FPN 上采样至 1/8 分辨率,与 FPN 最高层特征元素相加;
-
MVSFormer-P:DINO 处理 1/2 分辨率输入,提取 [CLS] 注意力图,与 DINO 特征拼接后经 GLU 降维,双转置卷积上采样至 1/8 分辨率,与 FPN 最高层特征相加;使用GLU融合注意力图公式:
-
代价体构建
采用经典的多视图立体代价体构建方法:
-
可微扭曲:
-
分组相关性:
将参考特征与 warped 源特征按通道分为 G 组,计算每组内积得到相关性特征Ci,平均后降维至 G 通道;
-
视图权重融合:
可见性加权融合:训练 2D CNN 预测像素级视图权重Wi(基于相关性熵),加权融合多源相关性特征,公式为:
代价体正则化
使用3D U-Net对代价体进行正则化输出正则化后的代价体
每个阶段使用不同的深度假设数:32-16-8-4
深度图生成
训练阶段:基于分类策略,使用CLA(交叉熵损失)和掩码处理,通过 argmax 选取概率最大的深度假设,用交叉熵损失优化;
测试阶段:采用温度调节策略,按阶段动态设置t(如t1=5,t2=2.5,t3=1.5,t4=1),计算概率期望得到Dtmp:
损失函数
训练采用交叉熵损失(CLA 损失),仅优化分类式深度预测,公式为:
L=−∑p,jQ(p,j)logP(p,j)
- Q(p,j)为真值深度的 one-hot 编码,仅在真值对应的深度假设位置为 1;
多任务损失,包含所有阶段的深度图:
- :初始深度预测损失
- :第k阶段第i次迭代的深度损失
- 使用L1损失函数
测试数据集
- DTU:室内数据集,测试分辨率1152×1536
- Tanks & Temples:室外数据集,包含Intermediate和Advanced集合
- ETH3D:高分辨率场景数据集
- 在DTU上训练,在BlendedMVS上微调,其他数据集直接测试
消融实验
1. 不同预训练模型
- ResNet50:改进有限,无法处理反射区域
- DINO-small:冻结权重,性能竞争
- Twins-small:可训练,性能最优
- MAE-base:性能中等
2. 多尺度训练
- 显著提升ViT模型的泛化能力
- 对CNN模型改进有限
- 比固定高分辨率微调更有效
3. DINO注意力图和GLU
- 使用[CLS] token的注意力图提升性能
- GLU融合优于简单拼接
- 保护重要特征信息
4. REG vs CLA分析
- CLA提供更可靠的置信度图
- REG在深度指标上略优
- 基于温度的方案平衡两者优势
5. 温度设置
- 设置达到最佳平衡
- 早期阶段高温度(类似CLA)
- 后期阶段低温度(类似REG)
6. 视图数量
- 增加源视图数量提升性能
- Tanks & Temples上使用20个视图达到最佳
7. ViT 预训练的重要性:
- 对比 Twins 从头训练与预训练微调,证明预训练权重能提供有效先验;
其他
ViT 特征的 “非逐像素” 根源:无论是 MVSFormer 用的 Twins,还是 MVSFormer-P 用的 DINO,输入 ViT 前都会先将图像下采样到 1/2 分辨率(如原始 H×W→H/2×W/2),再经 patch embedding(如 16×16 步长)得到更低分辨率的特征(如 DINO 输出 H/32×W/32,Twins 输出 H/8×W/8),这使得 ViT 特征天然是 “非逐像素” 的低维特征,必须通过上采样匹配 FPN 的逐像素特征尺度(FPN 输出 1/8~1× 分辨率的特征图)。
两种融合方案的适配设计:
- 对于 MVSFormer(完整版,用 Twins 分层 ViT):Twins 本身输出多尺度特征(H/8、H/16 等),文档中提到 “用额外 FPN 将 Twins 的多尺度特征上采样至 H/8×W/8”(公式 1:F(h)=FPN(F(h,1),F(h,2),F(h,3),F(h,4))),最终与 FPN 最高层(1/8 分辨率)特征元素 - wise 相加,利用 Twins 的全局注意力特征增强 FPN 的局部细节特征(、);
- 对于 MVSFormer-P(轻量版,冻结 DINO):DINO 输出 H/32×W/32 的特征,文档中设计了 GLU 模块(公式 2:F§=Swish(ConvBNl([Fdino;A])⊙Swish(ConvBNr([Fdino⊙A^]))),先结合 [CLS] token 的注意力图(含语义分割先验)保护关键特征,再通过双转置卷积上采样至 H/8×W/8,与 FPN 最高层特征相加,避免冻结 ViT 时的特征信息丢失。
FPN(即使带预训练 CNN)只能捕捉局部纹理,难以处理反射、无纹理区域;而 ViT 的 patch 级特征和长距离注意力能提供全局语义(如 “无纹理墙面的全局连续性”“反射区域与背景的语义区分”),通过上采样融合后,让 CNN 特征同时具备局部细节和全局上下文,这也是文档中提到 “ViT 特征与 FPN 特征互补” 的关键
 微信
微信- 支付宝

