
论文阅读_MVSAnywhere
MVSAnywhere (Multi-View Stereo Anywhere)
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | MVSAnywhere (Multi-View Stereo Anywhere) |
| 作者 | Sergio Izquierdo, Mohamed Sayed, Michael Firman, Guillermo Garcia-Hernando, Daniyar Turmukhambetov, Javier Civera, Oisin Mac Aodha, Gabriel Brostow, Jamie Watson |
| 作者单位 | Niantic |
| 时间 | 2025 |
| 发表会议/期刊 | TiPami |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 标定之后的多视角图像 |
| 输出 | 场景的点云图 |
| 所属领域 | MVS |
摘要精简
MVSA 提出了一种零样本、通用型多视角立体视觉方法,旨在解决传统MVS方法在跨域、跨场景(室内/室外)泛化能力差的问题。它结合了单目与多视角线索,采用自适应代价体解决尺度相关问题,结合 Transformer 架构实现高效特征处理。核心创新包括代价体 patchifier(无信息损失地将代价体 token 化)、视图数与尺度无关的元数据整合机制,以及单目 - 多目线索融合器。MVSA 在 Robust Multi-View Depth Benchmark 上取得 state-of-the-art 零样本深度估计结果,超越现有 MVS 和单目基线方法,生成高精度、3D 一致的深度图,助力高质量 3D 网格重建。
引言与出发点
-
现有 MVS 方法面临三大核心挑战,推动作者开展研究:
-
泛化能力弱:多数方法在训练域(如室内)表现优异,但难以适配不同场景(如室内 vs 室外)和相机设置,跨域性能大幅下降;
-
深度范围依赖:传统方法需已知深度范围构建代价体,而实际场景深度范围差异极大(室内数米 vs 室外数百米),且无法预先知晓;
-
架构与输入适配不足:ViT 架构的优势未充分融入 MVS,且现有方法难以处理可变数量的输入视图,元数据整合缺乏灵活性。
-
-
单目深度模型的局限性:虽能泛化,但仅依赖单图像,无法利用多视角几何一致性。
-
核心挑战:
- 如何构建适应任意深度范围的代价体积;
- 如何有效融合Transformer架构;
- 如何处理可变数量的输入视图;
- 如何预测3D一致的深度。
创新点
1. 视角数量与尺度无关的元数据机制
-
传统方法要求固定数量的源视图(如8张),MVSA 使用MLP对每个源视图独立处理,再通过加权聚合支持任意数量输入。
-
尺度归一化:通过源视图最大相对姿态归一化元数据中的相对姿态,用代价体深度范围的最值归一化深度相关元数据,使模型不受场景尺度影响;深度预测后通过缩放对齐输入姿态尺度,公式为:
其中σ(x)为网络输出的 sigmoid 值。
2. 代价体积块化器
- 将代价体积()转换为适合ViT输入的令牌序列。
- 避免简单卷积下采样,而是结合参考图像特征进行引导式下采样,保留细节信息。
3. 单目-多视角线索融合器
- 将代价体积令牌与参考图像编码器(ViT-B)的令牌在多个层级相加,融合单目先验与多视角匹配信息。
4. 自适应深度范围估计
- 使用级联代价体积:首次预测用于估计深度范围,第二次重建代价体积进行最终预测。
- 训练时对真实深度范围添加随机扰动,增强模型对不准确范围估计的鲁棒性。
5. 自适应代价体与深度范围估计
- 无需预先知晓深度范围:通过相机内参和外参启发式估计深度范围,结合级联代价体动态细化深度 bin,适配不同场景的深度差异;训练时对深度范围添加噪声,提升模型对范围估计误差的鲁棒性。
- 元数据增强代价体:整合特征点积、射线方向、相对射线角度、相对姿态距离、深度有效性掩码等元数据,丰富代价体的几何信息,提升匹配可靠性。
网络架构
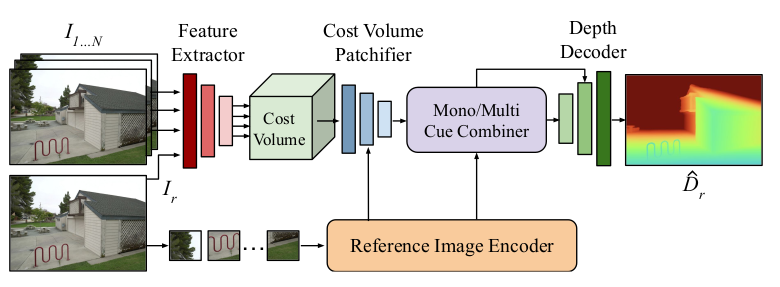
MVSA 采用 Transformer 与 CNN 结合的混合架构,整体分为五大核心组件,流程为 “特征提取→代价体构建→线索融合→深度解码”:
- 特征提取器:使用ResNet18前两个块,提取源视图和参考视图的特征(分辨率 )。
- 代价体积:基于平面扫描构建,融合多视角特征与元数据。
- 参考图像编码器:使用Depth Anything V2的ViT-B,提取单目深度特征(分辨率 )。
- 单目-多视角线索融合器:将代价体积token与单目token融合,输入ViT-B(DINOv2初始化)。
- 深度解码器:上采样序列特征,生成最终深度图。。
特征提取
- 多视图特征提取:参考图和源图通过 ResNet18 的前两个 block 编码,经实例归一化后,输出分辨率为H/4×W/4的特征图Fr和Fi;
- 单目特征提取:参考图先缩放至14H/16×14W/16,输入 Depth Anything V2 的 ViT-Base 编码器,输出分辨率为H/16×W/16的单目特征,用于后续线索融合;
- 特征适配:多视图特征与单目特征通过维度投影和上 / 下采样,统一至相同通道数和分辨率,为融合做准备。
代价体构建
- 特征 warping:根据深度假设D,通过可微单应性将源图特征Fi warp 至参考图视角;
- 元数据计算:对每个像素(ur,vr)和深度 bink,计算特征点积、射线方向、相对姿态距离等元数据;
- 视图数自适应聚合:每个源视图的元数据和 warped 特征经 MLP 输出匹配分数和权重,加权求和得到代价体在该像素和 bin 的数值;
- 尺度归一化:对元数据中的姿态、深度等进行尺度归一化,确保模型尺度无关性;
- 代价体维度:最终代价体维度为 的代价体,包含深度、空间和特征通道信息。
- 元数据包括:
- 特征点积
- 射线方向
- 参考/源视图深度
- 射线夹角
- 相对位姿距离
- 深度有效性掩码
代价体正则化
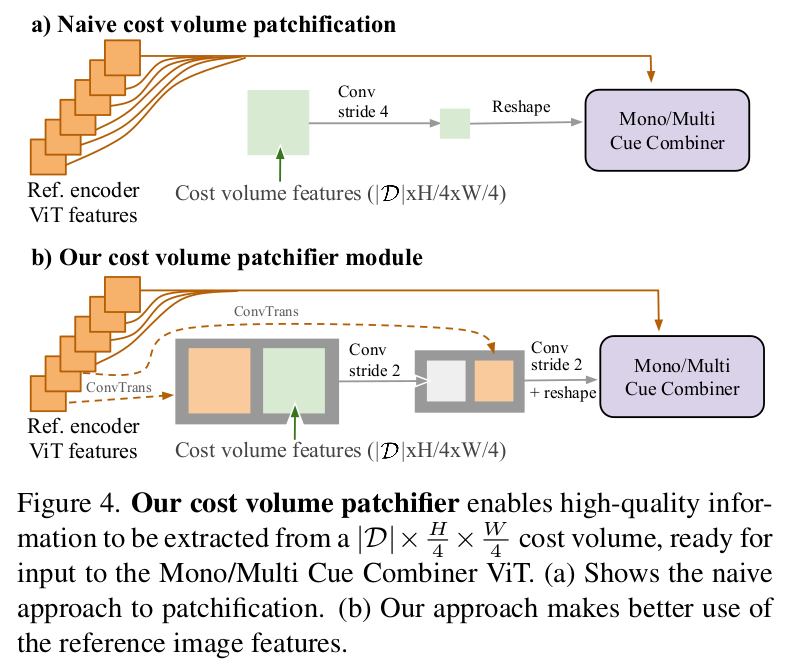
- 不使用传统3D CNN正则化,而是通过代价体积块化器 + ViT 进行隐式正则化。
- 代价体 patchifier 处理:通过 3 个残差块(步长 1、2、2)将代价体下采样至H/16×W/16,过程中拼接参考图像编码器的中间特征,引导下采样方向,保留关键几何信息;
- Transformer 正则化:patchifier 输出的特征图 reshape 为 token 序列,输入 Mono/Multi Cue Combiner 的 ViT-Base,与单目 ViT 特征在中间块融合,通过自注意力捕捉全局上下文,强化代价体的判别性;
- 特征投影:ViT 输出的序列特征经线性投影,转化为适配解码器的特征图格式。
深度图生成
-
自适应深度范围初始化:通过相机参数估计初始深度范围[dmin,dmax],生成初始深度 bin;
-
代价体细化:级联迭代优化深度 bin,缩小深度搜索范围,提升深度精度;
-
深度解码:基于 [58] 的解码器架构,将融合后的特征图逐步上采样至原始分辨率,输出深度 logit 值;
-
尺度对齐:通过 sigmoid 转换和指数缩放,将 logit 值映射为 metric 深度,对齐输入姿态的尺度;
损失函数
总损失为:
其中:
- Log深度损失监督多尺度解码输出与真值的 log 域绝对误差,公式为:
- 梯度损失(作用于逆深度),对最高分辨率输出的1/D计算空间梯度损失,避免损失主导,公式为::
- 法向量损失:
测试数据集
在Robust Multi-View Depth Benchmark (RMVDB) 上评估,包含:
- KITTI(驾驶)
- ScanNet(室内)
- ETH3D(建筑)
- DTU(物体级)
- Tanks & Temples(大规模场景)
消融实验
- Mono/Multi Cue Combiner:对比 ViT vs CNN 融合、朴素 patchify vs 提出的 patchifier,使用CNN替代ViT、朴素块化器均导致性能下降。
- 元数据与归一化:元数据提升性能,尺度归一化对非度量场景鲁棒。
- 代价体积设置:固定深度范围(0-100m)在DTU等数据集上失败;训练时对范围加噪声很重要。
- 整体架构:移除DAV2预训练权重、使用更小ViT、使用SimpleRecon架构均不如完整MVSA。
- 训练数据:在相同数据上训练,MVSA优于MVSFormer++。
- 泛化性验证:缩放 ScanNet 姿态尺度(×100),测试模型对尺度变化的鲁棒性。
其他创新点
- 动态物体处理:在KITTI等包含运动物体的数据上表现优于传统MVS。
- 3D重建质量:深度图具有高3D一致性,重建出的网格质量优于多数仅在ScanNet上训练的方法。
- 高斯溅射正则化:可作为深度与法线先验用于高斯溅射重建的正则化。
 微信
微信- 支付宝

