
论文阅读_LucidDreamer
LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | LucidDreamer: Domain-free Generation of 3D Gaussian Splatting Scenes |
| 作者 | Jaeyoung Chung, Suyoung Lee, Hyeongjin Nam, Jaerin Lee, Kyoung Mu Lee |
| 作者单位 | ASRI, Department of ECE, Seoul National University, Seoul, Korea |
| 时间 | 2023 (推断) |
| 发表会议/期刊 | 未明确说明(可能是计算机视觉顶会,如 ICCV/CVPR) |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 文本、RGB图像、RGBD图像 |
| 输出 | 3D高斯喷洒场景(3D Gaussian Splatting Scenes) |
| 所属领域 | 3D场景生成 |
摘要精简
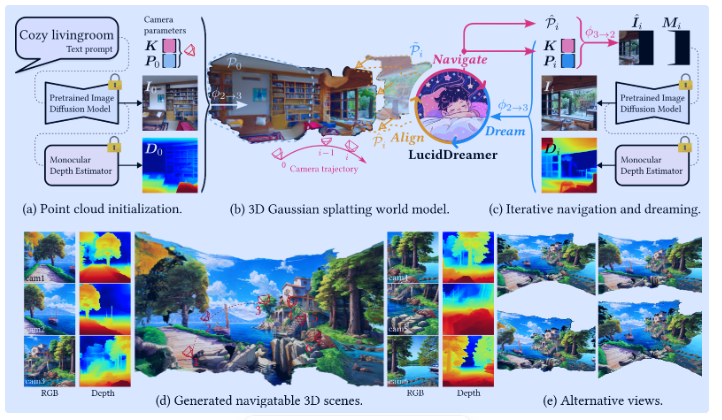
LucidDreamer 提出一种无领域限制的高质量 3D 场景生成框架,支持文本、RGB、RGBD 等多种输入类型。核心流程为交替执行 “Dreaming” 和 “Alignment” 操作:Dreaming 阶段以点云为几何指导,通过 Stable Diffusion 修复生成多视角一致图像,结合单目深度估计提升为 3D 点;Alignment 阶段通过深度缩放系数估计和点云对齐算法,将新生成的点云与现有点云平滑融合。最终以融合后的点云为初始 SfM 点,优化 3D 高斯泼溅(3D Gaussian Splatting),填充点云孔洞,生成高清、多视角一致的 3D 场景。
引言与出发点
随着商用混合现实平台的出现和3D图形技术的快速发展,高质量3D场景生成已成为计算机视觉中的重要问题。现有基于扩散模型的3D生成方法(体素、点云、隐式神经表示)由于使用3D扫描数据训练,存在生成多样性和质量低的问题。另一种思路是利用预训练的图像生成扩散模型(如 Stable Diffusion)来创建多样化的高质量3D场景,但这些模型无法保证生成图像之间的多视角一致性。因此,本文提出 LucidDreamer,一个结合 Stable Diffusion 和 3D Gaussian Splatting 的流程,可以从文本、RGB、RGBD等多种输入生成高质量、多样化的3D场景。其核心思想是通过 Dreaming 和 Alignment 两个交替步骤,逐步构建一个统一的大规模点云,并以此为基础优化高斯喷洒表示,从而生成逼真且一致的3D场景。
创新点
- 无需特定领域训练的高质量3D场景生成:提出 LucidDreamer 流程,通过结合大规模预训练扩散模型(Stable Diffusion)、单目深度估计和显式3D表示(高斯喷洒),实现了对任意领域场景的高质量生成,克服了现有方法因依赖特定3D扫描数据集而导致的领域限制问题。
- Dreaming 和 Alignment 交替的渐进式场景构建:
- Dreaming 过程:将点云作为几何指导,在设定的相机轨迹上,将点云可见部分投影到新视角,利用扩散修复模型补全图像,并结合深度估计将新图像提升为3D点云。
- Alignment 过程:设计一种对齐算法,通过沿射线移动新点并平滑插值深度变化,将新生成的点云部分无缝对齐并融合到现有场景点云中,确保几何一致性。
- 灵活的多模态输入支持:支持文本、RGB图像、RGBD图像作为输入,并可同时使用多种输入条件(如图像+文本),甚至允许在生成过程中动态改变输入条件,为用户提供了高度灵活的创作方式。
- 基于高斯喷洒的高质量渲染:使用构建好的大规模点云作为初始结构运动点,初始化并优化3D高斯喷洒模型。高斯喷洒的连续表示能够填补点云因深度不一致产生的空洞,从而渲染出更加逼真的3D场景。
相关工作总结与对比
| 相关领域 | 代表性工作 | 指出问题/局限性 |
|---|---|---|
| 3D场景表示 | 点云、网格、体素;神经辐射场(NeRF);3D高斯喷洒(3D Gaussian Splatting) | 显式表示需要大量元素表达细节;隐式表示(如NeRF)处理慢且难以操控;高斯喷洒结合了显式表示的快速渲染和隐式表示的高质量。 |
| 3D场景生成 | 基于GAN的生成(pi-GAN, GRAF);基于扩散模型的生成(在体素、点云、triplane、隐式网络上的扩散) | GAN训练不稳定,内存限制导致生成质量低;扩散模型在3D表示上的训练受限于3D扫描数据,多样性和质量不足,且多为物体中心,难以生成复杂场景。 |
| 基于2D扩散模型的3D生成 | DreamFusion, SJC;RGBD2(基于RGBD扩散模型生成室内场景) | DreamFusion等需要耗时的SDS优化;RGBD2等需要针对特定领域(如室内场景)训练扩散模型,泛化性差,生成的图像风格受训练数据限制,分辨率低(128x128)。 |
网络架构
LucidDreamer 的流程不依赖于一个端到端的单一网络,而是一个由多个现成模块构成的管道系统,主要分为两个阶段:
- 点云构建阶段:
- 输入处理模块:根据输入类型(文本、RGB、RGBD)生成初始RGB图像 和深度图 。文本输入使用 Stable Diffusion 生成图像;RGB输入使用单目深度估计模型(如 ZoeDepth)估计深度;RGBD直接使用提供的深度。
- Dreaming 模块:包含一个预训练的 Stable Diffusion 修复模型 和一个单目深度估计模型 。用于在相机轨迹的每个新位置 生成完整的图像 和对应的深度图 。
- Alignment 模块:一个几何处理算法 ,负责将新生成的点云 与现有点云 对齐并融合。
- 高斯喷洒优化阶段:
- 3D Gaussian Splatting 优化器:使用点云构建阶段生成的最终点云 和一系列重投影图像作为监督,优化3D高斯喷洒表示。该阶段利用高斯喷洒的快速可微渲染进行训练。
整个系统的核心是 Dreaming 和 Alignment 的迭代过程,而非一个固定的神经网络架构。
特征提取机制
LucidDreamer 本身不包含传统的特征提取网络。其关键的信息传递和一致性保障依赖于以下机制:
- 几何指导的图像生成:在 Dreaming 步骤中,特征来源于当前场景点云的几何投影。将点云投影到新相机平面得到的图像 和掩码 ,为 Stable Diffusion 修复模型提供了强烈的几何先验,引导其生成与现有场景几何一致的新内容。
- 深度一致性优化:通过优化深度缩放系数 ,使新生成图像的深度图 与现有点云在重叠区域对齐,从而在3D空间实现几何对齐。
- 点云对齐与插值:在 Alignment 步骤中,算法在点级别进行操作,通过计算重叠区域对应点的位移向量,并约束点沿相机射线移动,辅以平滑插值,保证了新点云与旧点云在3D空间中的无缝连接。这是一种基于3D几何坐标的直接特征(位置、颜色)整合。
三维场景生成流程
-
初始化:
- 根据输入(文本/RGB/RGBD)获得初始图像 和深度图 。
- 根据相机内参 和外参 ,将 和 提升到3D空间,形成初始点云 。
-
迭代点云构建 (重复 次):
- 导航:沿预设相机轨迹移动相机到新位置 。
- Dreaming:
a. 将现有点云 投影到新相机平面,得到不完整的图像 和掩码 。
b. 使用 Stable Diffusion 修复模型 根据 和 生成完整图像 。
c. 使用深度估计模型 估计 的相对深度 ,并通过优化缩放系数 得到与现有点云对齐的深度图 。
d. 仅对修复区域()的像素,利用 和 生成新的点云 。 - Alignment:使用对齐算法 移动新点云 中的点,使其与 平滑连接,得到融合后的点云 $\mathcal{P}i = \mathcal{P}{i-1}
 微信
微信- 支付宝

