
论文阅读_IterMVSNet
IterMVS
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | IterMVS: Iterative Probability Estimation for Efficient Multi-View Stereo |
| 作者 | Fangjinhua Wang(又是你), Silvano Galliani, Christoph Vogel, Marc Pollefeys |
| 作者单位 | ETH Zurich |
| 时间 | 2021 |
| 发表会议/期刊 | CVPR |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 标定之后的多视角图像 |
| 输出 | 场景的点云图,每个视角的法线和深度图 |
| 所属领域 | MVS |
摘要精简
本文提出 IterMVS,一种高效的高分辨率多视图立体(MVS)数据驱动方法。核心是基于 GRU 的概率估计器,其隐藏态编码像素级深度概率分布,通过多轮迭代注入多尺度匹配信息,逐步优化分布并推断深度与置信度。该方法创新结合分类与回归策略,兼顾多模态分布鲁棒性与亚像素精度。在 DTU、Tanks&Temples 和 ETH3D 数据集上验证表明,IterMVS 是内存和运行时效率最高的学习型 MVS 方法,同时在 DTU 上取得竞争性性能,在 Tanks&Temples 和 ETH3D 上展现更优泛化能力。
效果不怎么样,只是快,显存低
引言与出发点
- 问题背景:传统MVS方法受限于手工建模和匹配度量,在遮挡、光照变化、低纹理区域等挑战条件下表现不佳。
- 现有方法局限:
- MVSNet等基于3D CNN的方法内存和运行时间消耗大,难以扩展到高分辨率
- 循环方法(如R-MVSNet)可降低内存但增加运行时间
- 多阶段方法(如PatchmatchNet)效率高但由粗到细结构限制错误恢复能力
- 核心目标:开发同时具备高效率和高性能的MVS方法
创新点
1. GRU-based概率估计器
- 提出轻量 GRU 概率估计器,将像素级深度概率分布编码在 32 维隐藏态中,无需全程存储高维概率体,大幅降低内存占用。
- 隐藏态通过多轮迭代持续更新,每轮注入多尺度匹配信息,始终保持对全深度范围的分布追踪,避免粗到精方法的搜索范围限制。
2. 分类+回归混合深度估计策略
- 先通过 argmax 从概率分布中找到最高概率索引(分类),再在该索引的局部范围内计算期望(回归),公式为:$$\mathbf{D}(\mathbf{p})=\left(\frac{1}{\sum_{j=X(\mathbf{p})-r}^{X(\mathbf{p})+r} \mathbf{P}(\mathbf{p}, j)} \sum_{j=X(\mathbf{p})-r}^{X(\mathbf{p})+r} \frac{1}{d_j}\cdot\mathbf{P}(\mathbf{p}, j)\right)^{-1}$$
3. 像素级视图权重与学习型上采样
- 引入像素级视图权重,通过轻量 2D CNN 估计,自适应融合多源视图信息,提升遮挡和视角变化场景的鲁棒性。
- 深度上采样采用学习型策略,基于参考图像特征预测邻域权重,通过加权组合实现从 1/4 到全分辨率的精准提升,优于传统双线性上采样。
网络架构
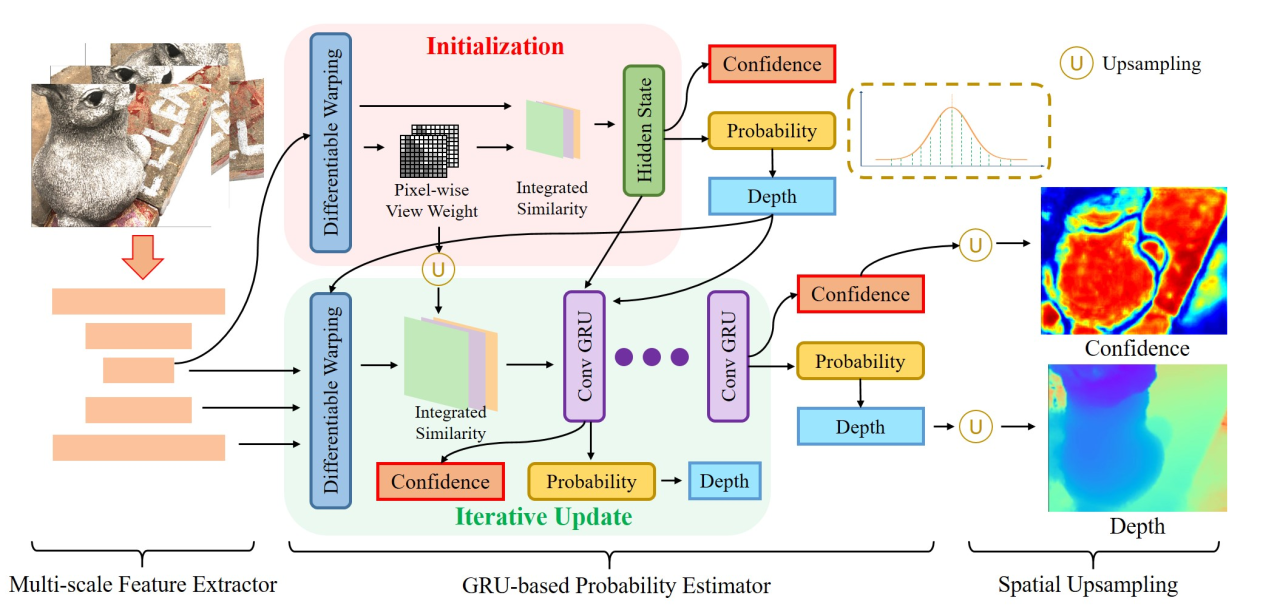
IterMVS 由三大核心模块组成,流程为 “特征提取→概率迭代优化→深度上采样”:
多尺度特征提取器:输出 3 个尺度的图像特征,为匹配计算提供基础;
GRU-based 概率估计器:含初始化和迭代更新子模块,编码深度概率分布并输出 1/4 分辨率深度与置信度;
空间上采样模块:将低分辨率深度图提升至全分辨率,保留细节信息。
特征提取
- 使用**特征金字塔网络(FPN)**提取多尺度特征
- 3个尺度级别:
- 分辨率: 原始分辨率
- 通道数:
- 特征图用于后续多尺度匹配相似度计算,初始化阶段仅使用 level3 特征降低计算量,迭代阶段融合所有尺度特征。
- 特征存储为 ,其中为图像索引,为尺度级别
代价体构建
可微分扭曲
使用相机参数将源视图特征扭曲到参考视图:
相似性计算
两视图匹配相似度:采用组 - wise 相关性,将特征通道分为 8 组,计算每组内积作为相似度;
视图权重集成
多源信息融合:通过像素级视图权重加权求和多源相似度,得到初始和迭代阶段的匹配相似度;
代价体正则化
- 不使用传统3D CNN正则化,通过GRU隐藏状态迭代更新实现隐式正则化
- 初始化正则化:初始相似度经 2D U-Net 聚合邻域信息,转换为初始隐藏态h0,编码初始深度概率分布;
- 尺度聚合:每个尺度的相似度经独立2D U-Net处理后拼接,确保多尺度信息有效融合。
深度图生成
1. 概率分布提取
概率分布提取:从GRU隐藏态通过2D CNN和Softmax,得到全深度范围的离散概率分布§;
2. 混合深度估计策略
混合策略深度估计:先通过argmax找到最高概率索引(X§),再在局部半径(r=4)范围内计算期望,得到1/4分辨率深度图;
分类:找到最大概率索引
回归:在局部范围内计算期望
3. 置信度估计:
从隐藏态通过2D CNN和Sigmoid预测置信度©,用于过滤低可信度深度值;
4. 空间上采样
使用学习的上采样方法:基于参考图level2特征,对粗分辨率的9个最近邻进行加权组合,加权组合得到全分辨率深度图(D_{upsample})。
损失函数
总损失函数:
各分量损失
- 初始化损失:初始化阶段深度与真值的L1损失
- 分类损失:概率分布与真值one-hot编码的交叉熵损失;
- 回归损失:仅考虑分类索引附近的像素,计算深度L1损失;
- 置信度损失:预测置信度与真值(基于深度误差)的二分类交叉熵损失;
- 上采样损失:
测试数据集
- DTU:室内多视角立体数据集,124个场景
- Tanks & Temples:大规模室外真实场景
- ETH3D:高分辨率图像,强视角变化
消融实验
1. 深度预测策略
- 分类+回归(最佳)
- 仅分类:精度下降
- 仅回归:易过拟合,泛化差
2. 置信度估计
- 学习置信度(最佳)
- 概率求和:边界处效果差
3. 特征尺度
- 多尺度特征(最佳)
- 单尺度特征:性能下降
4. 深度上采样
- 学习上采样(最佳)
- 双线性上采样:性能显著下降
5. 逆深度损失
- 使用逆深度(最佳)
- 直接深度:大规模场景性能差
6. 逐像素视图权重
- 使用视图权重(最佳)
- 简单平均:强视角变化下性能差
7. 迭代次数
- 更多迭代带来持续改进
- 时在DTU达到SOTA性能
8. 视图数量
- 多视图信息改善重建质量
- 约6个视图时性能饱和
其他创新点
逆深度空间处理
- 在逆深度空间均匀采样假设
- 更适合大规模场景
- 损失计算也在逆深度空间进行
灵活的性能-效率权衡
- 通过调整迭代次数 平衡速度与精度
- 用户可根据应用需求自定义权衡
置信度学习
- 从隐藏状态直接学习置信度
- 用于后续的离群值过滤
- 比基于概率求和的策略更准确
 微信
微信- 支付宝

