
论文阅读_Fast-MVSNet
Fast-MVSNet
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Fast-MVSNet: Sparse-to-Dense Multi-View Stereo With Learned Propagation and Gauss-Newton Refinement |
| 作者 | Zehao Yu, Shenghua Gao |
| 作者单位 | ShanghaiTech University |
| 时间 | 2020 |
| 发表会议/期刊 | CVPR |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 多视角 |
| 输出 | 参考视角深度图 |
| 所属领域 | MVS |
1. 摘要精简
提出一种高效的稀疏到密集、粗到精多视图立体匹配(MVS)框架 Fast-MVSNet,兼顾重建精度与效率。该方法先构建稀疏代价体预测稀疏高分辨率深度图,再通过小型 CNN 学习局部像素的深度依赖关系,将稀疏深度图 densify 为密集深度图,最后引入可微分高斯牛顿(Gauss-Newton)层优化深度图。所有模块轻量且可微分,支持端到端训练,内存消耗低且效率极高 —— 比 R-MVSNet 快 14 倍、比 Point-MVSNet 快 5 倍,在 DTU 和 Tanks and Temples 数据集上取得相当或更优的重建效果,源代码已开源(https://github.com/svip-lab/FastMVSNet)。
2. 研究动机与出发点
现有深度学习 MVS 方法存在效率与内存的核心矛盾:MVSNet 等基于 3D CNN 的方法内存消耗随分辨率立方增长,难以适配高分辨率场景;R-MVSNet 和 Point-MVSNet 虽优化了内存,但效率仍不足(R-MVSNet 处理 400×300 深度图需 6.9 秒,Point-MVSNet 处理 640×480 需 3 秒),无法满足实际场景需求。此外,低分辨率深度图丢失细细节,高分辨率深度图直接预测成本过高。因此,本文提出稀疏到密集 + 粗到精的混合策略,在保证精度的同时大幅提升效率,解决 MVS 的实用性瓶颈。
3. 创新点
- 提出稀疏到密集 + 粗到精的双策略框架:稀疏表示降低内存与计算成本,粗到精流程保证重建精度,兼顾效率与有效性;
- 设计数据驱动的深度传播模块:基于联合双边上采样启发,用小型 CNN 学习局部像素的深度依赖关系, densify 稀疏深度图,过程可解释且无需手动调参;
- 提出可微分高斯牛顿层:以多视图 CNN 特征和粗深度图为输入优化深度,支持端到端训练,快速提升亚像素精度;
- 整体模块轻量高效:所有组件均为小型网络或可微分优化层,内存消耗仅为 Point-MVSNet 的 1/2,推理速度远超现有 SOTA 方法。
4. 网络架构
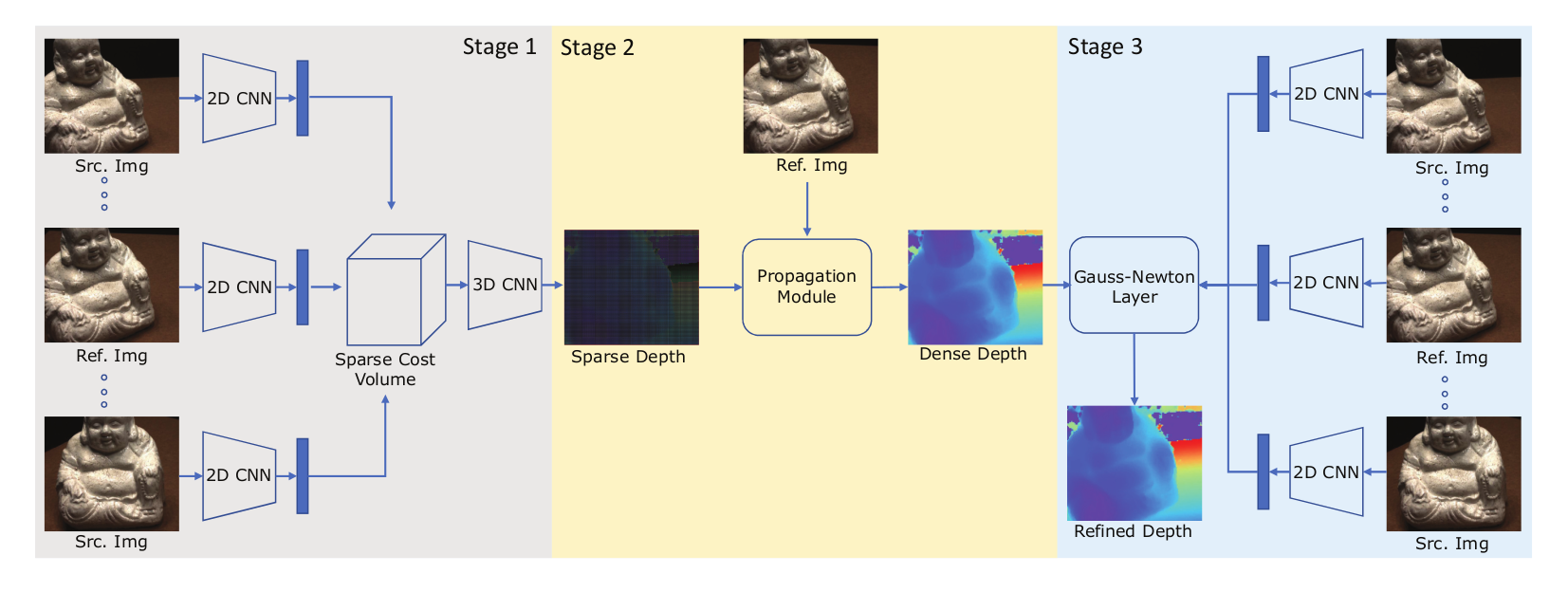
三阶段流水线结构:
网络整体分为三个串联阶段,流程为 “稀疏深度预测→密集深度传播→深度优化细化”:
- 阶段 1:稀疏高分辨率深度图预测,通过稀疏代价体构建与 3D CNN 正则化,输出稀疏高分辨率深度图;
- 阶段 2:深度图传播,利用小型 CNN 学习的权重,将稀疏深度图 densify 为密集深度图,保留边缘细节;
- 阶段 3:高斯牛顿细化,通过可微分高斯牛顿层优化密集深度图,提升亚像素精度;
- 后处理:多视图深度图融合为 3D 点云,采用与 MVSNet 一致的融合策略。
5. 特征提取
采用与 MVSNet 一致的 8 层 2D CNN,所有输入视图(参考图 + 源图)共享权重:
网络结构:每层卷积后含批归一化和 ReLU 激活,无额外下采样层(除自然卷积步长效应);
输出特征:最终输出 32 通道特征图,尺寸为输入图像的 1/8,为后续稀疏代价体构建提供紧凑且富含语义的特征表示;
6. 代价体构建
稀疏代价体:尺寸为 ,训练时 ,评估时 ,代价体内存消耗为Point-MVSNet的一半
7. 代价体正则化
- 使用3D CNN正则化代价体(也可用其他方法如Conv GRU)
- 通过可微分argmax预测稀疏深度图
- 3D CNN在稀疏表示下能融合更大空间上下文信息
8. 深度图生成
初始深度图:
阶段 1:稀疏高分辨率深度图生成,正则化后的稀疏代价体通过可微分 argmax 操作,输出与输入图像同尺寸的稀疏深度图;
传播过程:
先通过最近邻插值得到初始密集深度图,再利用 CNN 预测的局部权重进行加权聚合,公式为
其中 由CNN预测
高斯牛顿细化:

高斯牛顿细化,以多视图特征和密集深度图为输入,最小化重投影特征误差:
深度增量计算:
最终深度为
9. 损失函数
采用均值绝对误差(MAE)损失,同时监督传播后的密集深度图和细化后的深度图,确保各阶段精度
为传播后的密集深度图,为高斯牛顿细化后的深度图;
其中 ,,平衡两阶段损失贡献。 为真实深度图
10. 测试数据集
- DTU数据集:80个场景,49或64个相机位置,7种光照条件
- Tanks and Temples:大规模室外数据集,测试泛化能力
- 输入图像分辨率:DTU为1280×960,Tanks and Temples为1920×1056
11. 消融实验测试组件
消融实验在 DTU 评估集上进行,验证核心组件的有效性:
- 稀疏高分辨率深度图:对比低分辨率深度图(上采样至相同尺寸),验证稀疏高分辨率表示在细节保留上的优势;
- 传播模块:对比 “无传播模块(仅最近邻插值)” 与 “含传播模块”,验证学习式深度传播对密集深度图精度的提升;
- 高斯牛顿细化:对比 “无细化” 与 “含细化”,验证优化层对亚像素精度的改善(整体质量相对提升 9.5%);
- 效率对比:将 Point-MVSNet 的 PointFlow 模块替换为高斯牛顿层,验证其在保持相当精度的同时,效率提升 5 倍。
额外创新点补充
- 可解释性传播:传播模块受联合双边上采样启发,融合图像信息与局部深度依赖,相比黑盒网络更具可解释性;
- 端到端可训练:高斯牛顿层设计为可微分,使整个稀疏到密集流程能端到端训练,避免分阶段训练的误差累积;
- 灵活性强:代价体正则化可替换为 R-MVSNet 的 ConvGRU,框架兼容性高,适配不同场景需求。
其他亮点
- 在DTU上取得最佳完整性和整体质量
- 内存消耗仅5.3GB,远低于其他方法
- 支持640×480高分辨率深度图输出
- 在Tanks and Temples上展现良好泛化能力
- 代码开源:https://github.com/svip-lab/FastMVSNet
 微信
微信- 支付宝

