
论文阅读_DreamFusion
DreamFusion: Text-to-3D using 2D Diffusion
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | DreamFusion: Text-to-3D using 2D Diffusion |
| 作者 | Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall |
| 作者单位 | Google Research, UC Berkeley |
| 时间 | 2022 |
| 发表会议/期刊 | arXiv (后发表于 ICLR 2023) |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 文本描述(自然语言提示词) |
| 输出 | 三维神经辐射场(NeRF),可渲染为任意视角、任意光照下的图像,或导出为网格 |
| 所属领域 | 文本生成三维(Text-to-3D)、神经渲染、扩散模型 |
1. 摘要精简
本文提出了DreamFusion,一种使用预训练的二维文本到图像扩散模型来实现文本到三维合成的方法。传统方法需要大规模标注的三维数据和高效的三维去噪架构,而这些条件目前尚不具备。本文通过引入一种基于概率密度蒸馏(probability density distillation) 的损失函数,将二维扩散模型作为先验,来优化一个参数化的图像生成器(NeRF)。具体地,在一个类似DeepDream的流程中,通过梯度下降优化一个随机初始化的三维模型(神经辐射场,NeRF),使得从随机角度渲染出的二维图像具有较低的损失。最终生成的三维模型可以从任意角度查看、在任意光照下重照明,或合成到任何三维环境中。该方法无需任何三维训练数据,也无需修改图像扩散模型,证明了预训练图像扩散模型作为先验的有效性。
2. 研究动机与出发点
引言指出,基于文本的生成图像模型(如扩散模型)已经能够实现高保真、多样化和可控的图像合成。这得益于大规模图文对齐数据集和可扩展的生成模型架构。然而,将这一成功扩展到三维合成面临挑战,因为这需要大量的特定模态(三维)训练数据,而这样的数据相对稀缺。
三维资产的创作目前严重依赖专业人员在软件(如Blender, Maya)中手工建模,过程耗时且需要专业知识。文本到三维生成模型有望降低创作门槛,提升艺术家的工作流程。
现有三维生成模型通常需要显式的三维数据(体素、点云)进行训练。而本文的目标是仅利用一个在二维图像上训练的扩散模型来学习三维结构,从而规避三维数据稀缺的问题。先前的工作如Dream Fields证明了使用CLIP等二维图文模型进行三维合成的可能性,但其生成结果往往缺乏真实感和准确性。因此,本文旨在探索如何利用更强大的二维扩散模型作为先验,来生成高质量、连贯的三维物体和场景。
3. 创新点与相关工作对比
创新点总结:
- 提出分数蒸馏采样(Score Distillation Sampling, SDS):这是一种新颖的损失函数,基于概率密度蒸馏,能够利用预训练的二维扩散模型的分数函数(score function) 来优化任意可微分的图像参数化表示(如NeRF),从而在不需要三维数据的情况下进行三维生成。
- mip-NeRF 变体的 3D 表示:基于 mip-NeRF 360 改进,用 MLP 参数化体密度τ和反照率ρ,通过积分位置编码处理抗锯齿;计算密度梯度得到表面法向量,结合 Lambert 漫反射模型实现重光照,增强几何细节;
- 视图与光照增强策略
- 随机采样球面相机位姿(方位角0∘-360∘,仰角−10∘-90∘),扩大视角覆盖;
- 视图相关文本提示:根据相机角度追加 “front view”“overhead view” 等,提升多视角一致性;
- 随机切换带纹理、无纹理、不同光照的渲染模式,强制模型学习真实 3D 几何而非扁平纹理。
- 实现零样本文本到三维生成:将SDS与一个专门设计的NeRF变体结合,形成了DreamFusion算法。该算法仅需要一个预训练的文本到图像扩散模型,就能为多样化的文本提示生成高保真、几何一致的三维模型。
- 创新的三维表示与渲染:对标准NeRF进行了关键修改,引入基于物理的着色(光照)、视角相关的文本提示、以及几何正则化,以鼓励生成具有合理几何形状而非“画在平面上”的三维内容。
- 无需三维数据与模型微调:整个方法不依赖任何三维或多视角训练数据,且不修改预训练的扩散模型(使用冻结的Imagen模型),展示了强大的迁移学习能力。
与相关工作对比:
| 对比方法 | 核心问题指出 |
|---|---|
| Dream Fields(CLIP 引导) | 1. 用 CLIP 损失训练,文本对齐精度低,几何一致性差;2. 无纹理渲染时几何评分接近随机(1.3%);3. 生成质量模糊 |
| CLIP-Mesh | 1. 依赖 CLIP 训练,评估存在偏置(同模型训练与测试);2. 仅优化网格,细节表现力弱;3. 文本一致性低于本文 |
| 3D GANs(如 GRAF) | 1. 需大量 3D 训练数据,泛化性差;2. 仅能生成特定类别(如人脸),无法处理任意文本;3. 分辨率有限 |
| 传统 NeRF | 1. 需多视角图像输入,无法直接处理文本;2. 无生成能力,仅能重建已知场景 |
| 3D 扩散模型 | 1. 3D 数据稀缺,训练成本极高;2. 生成效率低,难以实时优化;3. 文本条件融合困难 |
- 与基于CLIP的三维生成方法(如Dream Fields, CLIP-Mesh)对比:指出这些方法虽然能进行零样本生成,但生成的三维物体往往缺乏真实感和准确性。DreamFusion使用更强大的扩散模型先验,生成的几何和纹理质量显著更高。
- 与需要三维数据训练的生成模型(如基于体素、点云的GAN)对比:这些方法受限于三维数据的稀缺性。DreamFusion完全规避了对三维训练数据的依赖,利用海量的二维图文数据中蕴含的知识。
- 与传统的扩散模型采样方式对比:传统的扩散模型在像素空间进行采样,生成的是二维图像。SDS允许在参数空间(如NeRF的参数)进行采样/优化,从而生成可以自由操控的三维表示。
4. 网络架构构成
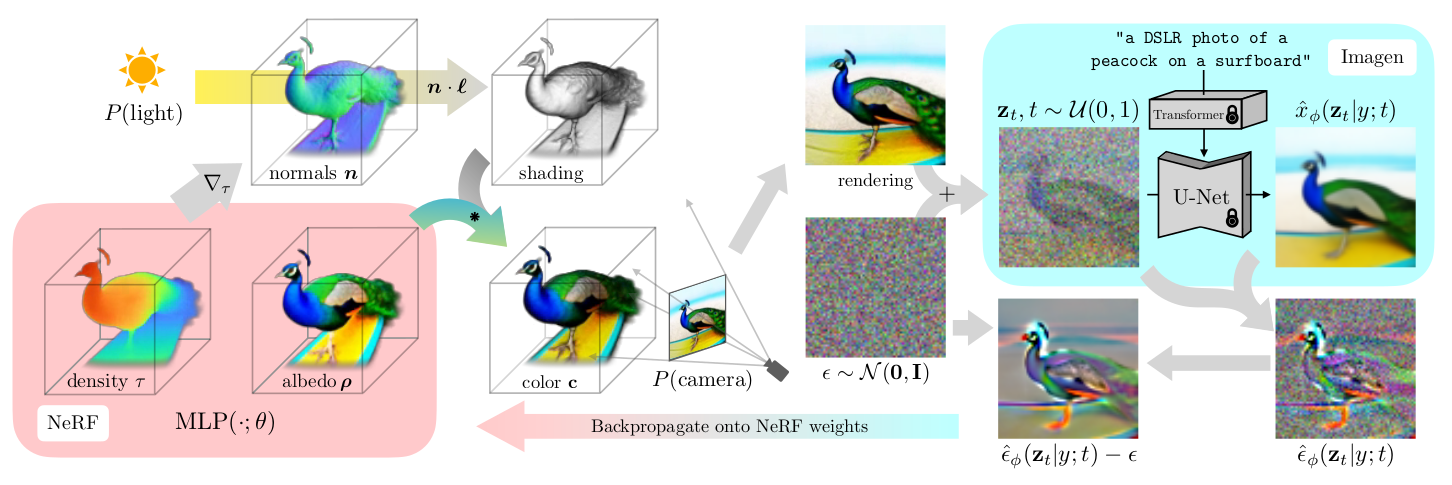

DreamFusion的核心是一个优化框架,而非一个单一的前馈网络。其架构主要由预训练 2D 扩散模型、3D 生成模块(mip-NeRF 变体)、SDS 损失模块、采样与渲染模块四部分组成:
-
预训练的文本到图像扩散模型:使用Imagen模型的基础模块作为冻结的、提供先验知识的批评器(critic)。它不参与梯度更新,仅为优化提供指导信号,预训练于 LAION400M 等 2D 图像文本对。
- 启用分类器无关引导(CFG),通过增强文本对齐。
-
3D 生成模块(mip-NeRF 变体)
- 核心MLP:一个多层感知机,5 个 ResNet 块(128 隐藏单元),Swish 激活 + 层归一化,输出体密度τ(exp 激活)和反照率ρ(sigmoid 激活);输入三维坐标 ,输出体素密度 $ au$ 和反照率(albedo)颜色 。$$( au,,{
ho})= ext{MLP}\left({\mu}; heta
ight)$$ - 位置编码:采用 mip-NeRF 的积分位置编码,协方差,训练初期退火实现粗到精优化;
- 着色(Shading)模型:为了得到逼真的几何,引入了光照。通过计算密度场的梯度得到法向量 ,然后使用漫反射模型计算每个点的颜色 。
- 核心MLP:一个多层感知机,5 个 ResNet 块(128 隐藏单元),Swish 激活 + 层归一化,输出体密度τ(exp 激活)和反照率ρ(sigmoid 激活);输入三维坐标 ,输出体素密度 $ au$ 和反照率(albedo)颜色 。$$( au,,{
 微信
微信- 支付宝

