
论文阅读_DreamBooth
DreamBooth:Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
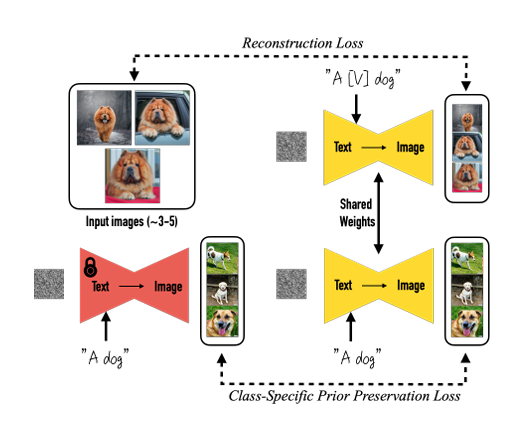
微调文生图扩散模型的方法,最大的特点是Subject-Driven,针对某一个特定的主体,生成这个主体可以是一个动物或者某个物体,包括人都是可以的。有特定小狗的一些照片,一般 3-5 张就能生成模型没有见过它做的事情的图片,比如说去到了这个希腊,去游泳,这都是模型没有见到过的照片,但是模型却能生成出来。并且这些生成的图片都有很高的保真度,能够保持这个物体的主要特征。
Probdef
输入:提示词和一个给定的很小量的 reference set,比如一个狗的三张图
输出:模仿生成该 set 中所指定提示词的图片,比如狗在南极的图
背景:
diffusion models这些模型实现了从给定文本提示中高质量和多样化的图像合成。但是缺少能够通过一个给定的很小量的 reference set ,去模仿生成该 set 中所指定 subject 的图片。这种针对特定物体的生成,在此前绝大部分的生成模型都是做不到的。相当于额外做了一个任务。作者还为这个主题驱动生成的新任务提供了一个新的数据集和评估协议。 lora仍然是主流,且有许多变种。dreambooth这两年没有什么大进展
方法:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 This is a 部落格 of outbreak_sen!
 微信
微信- 支付宝

