
论文阅读_CroCo
CroCo: Self-Supervised Pre-training for 3D Vision Tasks by Cross-View Completion
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | CroCo: Self-Supervised Pre-training for 3D Vision Tasks by Cross-View Completion |
| 作者 | Philippe Weinzaepfel, Vincent Leroy, Thomas Lucas, Romain Bregier, Yohann Cabon, Vaibhav Arora, Leonid Antsfeld, Boris Chidlovskii, Gabriela Csurka, Jerome Revaud |
| 作者单位 | NAVER LABS Europe |
| 时间 | 2022 |
| 发表会议/期刊 | 未明确说明,应为预印本或正在投稿中的工作 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 同一场景的两个不同视角的图像对 |
| 输出 | 预训练的图像编码器/解码器,用于下游3D视觉任务(深度估计、光流、相对姿态等) |
| 所属领域 | 自监督学习、3D计算机视觉、预训练 |
1. 摘要精简
本文提出了一种名为 CroCo 的自监督预训练方法,其核心是 跨视角补全 任务。与传统的掩码图像建模不同,CroCo 利用同一场景的两个不同视角的图像对:将第一幅图像的部分区域掩码,模型需要利用该图像的可见部分 以及 第二幅(参考)图像来重建被掩码的内容。这迫使模型理解场景的三维几何与视图间的空间关系,从而学习到对单目和双目3D视觉任务(如深度估计、光流、相机姿态估计)更有效的表示。
2. 引言与动机
- 现有MIM的局限:现有自监督预训练方法中,MIM(如 MAE)通过单视图掩码重建学习表征,但其训练数据(如 ImageNet)偏向目标中心,模型更侧重学习高层语义,难以适配 3D 视觉、低层几何任务(如深度估计、光流)—— 这类任务需要模型理解场景几何与视图间的空间关系。而实例判别类方法(如 DINO)输出全局表征,对密集像素级预测任务支持不足。
- 核心动机:如果提供一个额外的视角(参考图像),理论上可以解决这种模糊性,前提是模型能够理解两幅图像之间的几何对应关系。因此,设计跨视角补全任务,旨在引导模型学习3D几何与多视图一致性,从而获得更有利于3D下游任务的预训练表示。
3. 创新点
- 提出跨视角补全预训练任务:首次将“利用第二视图信息来补全第一视图的掩码区域”作为自监督预训练任务。这与单视图MIM形成对比,后者只能依靠单视图上下文和语义先验。
- 专为3D几何任务设计:明确以提升单目/双目3D视觉任务(深度、光流、姿态)的性能为目标,与主要面向高层语义任务的MIM工作区分开来。
- 通用且简洁的架构:
- 使用Siamese Vision Transformer作为编码器,权重共享。
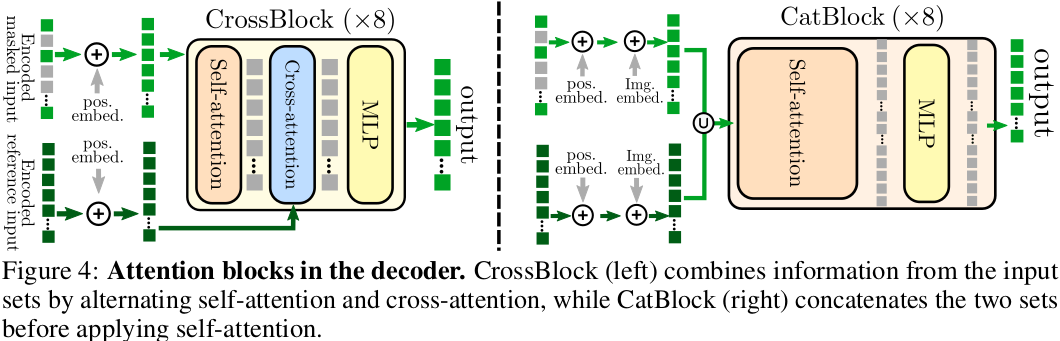
- 设计了两种基于Transformer的解码器架构(
CrossBlock和CatBlock),CrossBlock 通过交替自注意力与跨注意力融合双视图特征,计算成本低;CatBlock 拼接双视图 token 后进行自注意力,参数更少,二者在不同任务中各有优势,兼顾性能与效率。 - 预训练后的模型可以灵活迁移:单目任务仅使用编码器;双目任务直接使用整个编码器-解码器架构,无需复杂的任务特定设计。
- 证明合成数据预训练的有效性:在Habitat仿真器生成的室内场景图像对上进行预训练,尽管数据是合成的且领域较窄,但在真实世界的3D下游任务上取得了显著提升,证明了方法在几何表示学习上的有效性。
相关工作对比及指出的问题
| 相关工作类别 | 代表性方法 | 对比结论与指出的问题 |
|---|---|---|
| 实例判别类自监督 | DINO、MoCo | 输出全局表征,适合图像分类等高层任务,但缺乏局部像素级信息,难以迁移至密集 3D 几何任务(如深度估计)。 |
| 单视图 MIM 方法 | MAE、MultiMAE | 学习高层语义表征,适配分类、检测任务,但单视图重建存在固有模糊性,无法学习 3D 几何结构;MultiMAE 依赖额外模态(深度、语义)监督,通用性不足。 |
| 密集任务自监督方法 | InsLoc、VADeR | 聚焦于密集语义任务(如分割、检测),设计与评估未针对 3D 几何任务(深度、光流、位姿),表征迁移性有限。 |
| 3D 相关自监督方法 | 基于视图合成、RGB-D 匹配的方法 | 依赖光度一致性约束或 RGB-D 数据,数据获取成本高,且多针对特定 3D 任务设计,缺乏通用表征迁移能力。 |
4. 网络架构
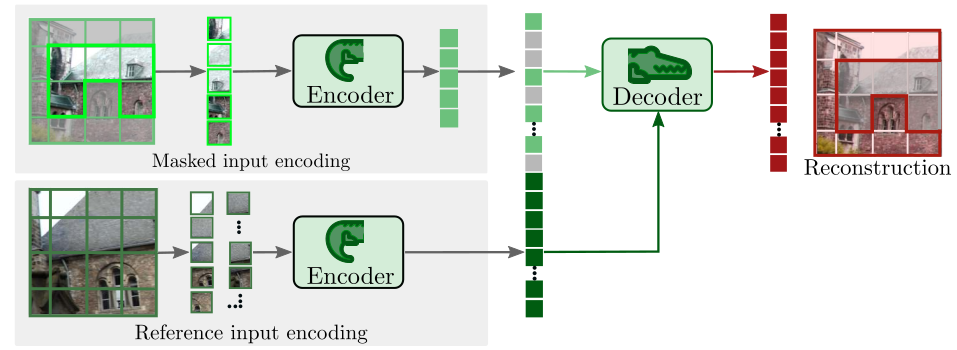
CroCo 预训练架构包含一个 Siamese 编码器和一个解码器。
- 输入:一对图像 (目标) 和 (参考),分别被划分为 个不重叠的 patch。将输入图像(224×224 分辨率)分割为 14×14=196 个 16×16 像素的 patch,每个 patch 展平为向量后经线性投影映射至 768 维,添加正弦位置编码以保留空间信息。
- 掩码:以高比例(如90%)随机掩码 中的 patch,得到可见 patch 集合 $ ilde{p}_1$。
- 编码器 ():一个权重共享的 ViT,分别编码 $ ilde{p}_1$ 和完整的 ,得到对应的 token 序列。
- 解码器 ():接收编码后的 $ ilde{p}_1$ token(并为掩码位置添加可学习的
[MASK]token)以及编码后的 token,通过交叉注意力或拼接自注意力机制融合信息,最终预测被掩码 patch 的 RGB 像素值。
CroCo 的 Siamese 编码器核心是共享权重的 Vision Transformer(ViT-Base/16)
5. 特征提取
- patch 分割与编码:将输入图像(224×224 分辨率)分割为 14×14=196 个 16×16 像素的 patch,每个 patch 展平为向量后经线性投影映射至 768 维,添加正弦位置编码以保留空间信息。
- 双视图特征提取
- 掩码图像x1:仅输入可见 patch 集合p~1,经编码器Eθ提取特征,后续填充 mask token(维度 768)以匹配原始 token 数量。
- 参考图像x2:输入全部 patch 集合p2,经同一共享权重编码器Eθ提取特征,保留完整的视图特征。
- 特征融合前处理:编码器输出的双视图特征均经过层归一化(LayerNorm),为解码器的跨视图注意力融合做准备。
- Transformer块:每个块包含多头自注意力机制和 MLP。
- Siamese设计:两个视图共享同一个编码器的权重,确保特征嵌入空间的一致性。
DPTHead
DPTHead,源于论文《Vision Transformers for Dense Prediction》(DPT 原始工作),核心是多尺度特征融合 + 密集像素级预测,适配 ViT 的 patch 级特征输出,结构如下:
- 核心目标:将 ViT 输出的低分辨率 patch 特征(14×14)转换为与输入图像同分辨率(224×224 或 256×256)的密集预测图(如深度图)。
- 关键组件:
- 特征提取层:复用 ViT 编码器的多尺度特征(不仅用最后一层输出,还融合中间层特征),捕捉从局部到全局的几何 / 语义信息。
- 特征金字塔融合:通过卷积层将不同层的 ViT 特征映射至同一维度(如 512 维),再通过上采样(插值或转置卷积)将低分辨率特征逐步提升至目标分辨率。
- 全局特征增强:引入全局平均池化(Global Average Pooling)捕捉图像级全局信息,与局部特征拼接融合,提升预测鲁棒性。
- 预测头:最后通过 1×1 卷积层将融合后的特征映射至单通道输出(如深度值),得到密集预测结果。
6. 代价体构建
注:CroCo 是一个预训练框架,本身不涉及传统立体匹配或深度估计中的“代价体”概念。其解码器中的交叉注意力机制可以被视为一种隐式的、动态的代价匹配过程:
- 在
CrossBlock中,解码器为 的每个(可见或掩码)token 计算其与 所有 token 的交叉注意力权重。 - 这些注意力权重本质上是在衡量 的某个空间位置与 中所有位置的特征相似度,可以理解为一种在特征空间进行的、稀疏的“匹配代价”计算。
- CrossBlock:先对x1的特征进行自注意力(强化自身上下文),再通过跨注意力将x1特征与x2特征对齐融合,直接建模双视图间的像素级关联。
- CatBlock:将x1和x2的特征 token 拼接(添加视图区分嵌入v1,v2),通过自注意力统一建模双视图全局依赖,间接实现跨视图特征融合。
8. 深度图生成(下游任务)
CroCo 在单目深度估计任务中通过以下步骤生成深度图:
预训练权重复用:丢弃解码器,仅使用预训练的 ViT 编码器Eθ提取输入图像的特征(无需掩码处理,输入完整图像 patch)。
深度预测头:在编码器输出的特征之上添加 DPT(Dense Prediction Transformer)头,该头通过多尺度特征融合与像素级映射,将编码器的 patch 级特征转换为密集的像素级深度预测。
训练与推理:
- 训练:使用 NYUv2 数据集的深度标签,以 L1 损失(或其他深度任务常用损失)微调编码器 + DPT 头。
- 推理:输入单张图像,经编码器提取特征后,DPT 头直接输出与输入图像分辨率一致的深度图。
9. 损失函数
预训练使用简单的 像素级重建损失(均方误差,MSE),仅针对被掩码的 patch 计算。
\mathcal{L}(x_1, x_2) = rac{1}{|p_1 \setminus ilde{p}_1|} \sum_{p_1^i \in p_1 \setminus ilde{p}_1} || \hat{p}_1^i - p_1^i ||^2
其中 是模型预测的 patch, 是真实 patch。实验发现对每个 target patch 进行内部像素值的均值和方差归一化后再计算损失,效果更好。
10. 测试数据集
文章在多种数据集上评估了 CroCo 预训练模型迁移到下游任务的表现:
| 任务类型 | 任务名称 | 数据集 | 评价指标 |
|---|---|---|---|
| 高层语义 | 图像分类 | ImageNet-1K | Top-1 准确率 |
| 语义分割 | ADE20K | mIoU | |
| 单目3D | 深度估计 | NYUv2 | (Acc@1.25) |
| 密集回归任务集 | Taskonomy (包含深度、法线、关键点等8个任务) | L1 Loss | |
| 绝对相机位姿回归 | 7-Scenes | 位置中值误差 (cm),旋转中值误差 (°) | |
| 双目3D | 光流估计 | MPI-Sintel | 平均端点误差 (AEPE) |
| 相对相机位姿估计 | 7-Scenes | 位置/旋转中值误差 | |
| 立体匹配 | Virtual KITTI (VKITTI) | 3-pixel error rate |
11. 消融实验
文章进行了详尽的消融实验以验证设计选择:
- 掩码比例:实验表明 90% 的高掩码比例在3D任务上效果最佳,高于MAE等单视图MIM方法的最佳比例。这说明参考视图提供了充足信息,高掩码能更好促进几何理解。
- 目标归一化:对每个待重建patch的像素进行内部归一化(减均值除标准差)能稳定提升所有下游任务性能。
- 解码器架构:对比了
CrossBlock(交叉注意力)和CatBlock(拼接后自注意力)。两者性能接近,CrossBlock参数量多但计算量小,CatBlock反之。最终主要使用CrossBlock。 - 解码器深度:发现解码器层数对单目任务影响不大,但对双目任务(如光流)很重要,更深解码器性能更好。
- 训练数据对来源:比较了使用两个真实不同视角的图像对 vs 对单张图像应用几何变换生成图像对。后者性能大幅下降,表明模型可能只是拟合了已知的变换,而非学习几何推理。
- 视图重叠度:研究了预训练图像对之间的共视率。发现共视率在 0.5 左右 时预训练效果最好。重叠太少则任务退化为单视图补全;重叠太多则任务过于简单。
- 预训练任务有效性:在相同数据上训练MAE与CroCo,CroCo在3D任务上显著优于MAE,证明了跨视图补全任务对于学习几何表示的优势。
- 微调策略:探索了在单目任务微调时是否使用预训练解码器。发现即使丢弃解码器(仅用编码器+DPT)效果已很好,但若保留并微调解码器(输入复制两次),性能还能进一步提升,不过计算代价增加。
12. 其他创新与贡献
- 无需复杂设计的双目任务适配:CroCo 的预训练架构可直接用于光流、相对姿态估计等双目任务,只需修改输出头,无需引入成本体积等任务特定模块,简化了流程并取得了有竞争力的结果。
- 强调几何与语义任务的权衡:实验表明,在室内场景合成数据上预训练的 CroCo 在3D几何任务上表现优异,但在 ImageNet 分类等高层语义任务上弱于在 ImageNet 上预训练的 MIM 模型。这清晰揭示了预训练数据与任务目标对所学表示性质的导向作用。
为什么 DepthAnything 等模型优先使用 DINO2 而非 CroCo 的编码器?
核心原因是两者的预训练目标、数据分布、特征泛化性适配不同场景,DINO2 更契合通用场景的深度估计需求,具体分析如下:
(1)预训练目标:通用特征 vs 专用几何特征
- CroCo 的预训练目标是跨视图补全,强制模型学习 “双视图几何关系”,特征更偏向 3D 几何结构(如深度、相机位姿),但语义泛化性差。论文实验显示,CroCo 在 ImageNet 分类(Top-1 准确率 37.0%)远低于 DINO(78.2%)和 MAE(68.0%),说明其特征在真实场景的通用鲁棒性不足。
- DINO2 的预训练目标是单视图实例判别,学习 “图像全局 / 局部特征的不变性”,特征更通用,既能捕捉语义信息,也能间接建模场景几何(通过真实数据的统计规律),适配通用场景的深度估计(如户外、复杂光照、多样物体)。
(2)预训练数据:合成室内 vs 真实海量数据
- CroCo 的预训练数据是Habitat 合成室内场景(180 万对双视图图像),场景单一(仅室内)、数据为仿真生成,缺乏真实场景的噪声(如光照变化、遮挡、纹理差异),导致特征在真实场景的鲁棒性不足。
- DINO2 的预训练数据是海量真实图像(如 ImageNet-1K 及扩展数据集),覆盖户外、室内、动态场景等,数据规模更大、分布更全,特征的泛化性和真实场景适配性远超 CroCo。
(3)数据与训练成本:单视图 vs 双视图
- CroCo 的预训练依赖双视图图像对(需同一场景不同视角),数据获取成本高(要么合成,要么通过 SLAM 等技术采集),难以扩大预训练规模。
- DINO2 的预训练仅需单视图图像,数据获取成本极低,可基于互联网海量无标注图像训练,预训练模型的参数规模和特征质量更优。
(4)开源生态与任务适配
- DINO2 由 Meta 开源,提供完善的预训练权重(如 ViT-Base/16、ViT-Large/14 等)、工具链和文档,易于集成到下游任务(如 DepthAnything),且经过工业界和学术界广泛验证。
- CroCo 的核心优势是 “室内 3D 几何任务”(如室内深度估计、位姿估计),但开源生态不够完善,预训练模型仅适配合成室内数据,难以直接迁移到通用场景的深度估计(如 DepthAnything 面向的户外 / 混合场景)。
(5)任务导向差异
- DepthAnything 等模型的目标是通用场景的稠密深度估计(无需限制室内 / 户外),需特征同时具备 “几何准确性” 和 “场景鲁棒性”,DINO2 的通用特征更契合这一需求。
- CroCo 的编码器更适合专用室内 3D 任务,若用于通用场景,会因数据分布不匹配导致性能下降(论文也提到其在语义任务上的短板)。
 微信
微信- 支付宝

