
论文阅读_Cas-MVSNet
Recurrent MVSNet(R-MVSNet)
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Cascade Cost Volume for High-Resolution Multi-View Stereo and Stereo Matching |
| 作者 | Xiaodong Gu, Zhiwen Fan, Zuozhuo Dai, Siyu Zhu, Feitong Tan, Ping Tan |
| 作者单位 | 阿里巴巴人工智能实验室 |
| 时间 | 2020 |
| 发表会议/期刊 | CVPR |
方法概览
这篇论文包含了Stereo部分和MVS部分,是结合起来的
| 特点 | 文章性质 |
|---|---|
| 输入 | 多视角 |
| 输出 | 参考视角深度图 |
| 所属领域 | MVS |
1. 摘要精简
提出一种内存和时间高效的级联代价体(Cascade Cost Volume)框架,用于高分辨率多视图立体匹配(MVS)和立体匹配任务。该框架将传统单一 3D 代价体分解为多阶段级联结构,基于特征金字塔以 “粗到精” 方式重建:前一阶段预测结果指导后一阶段缩小深度 / 视差范围、提升代价体空间分辨率并细化间隔,使计算资源聚焦于有效区域。该框架可无缝集成到现有 3D 代价体基方法(如 MVSNet、PSMNet、GwcNet),在 DTU 数据集上使 MVSNet 精度提升 35.6%(排名第一),GPU 内存和运行时间分别减少 50.6% 和 59.3%;在 Tanks and Temples 数据集上取得所有深度学习模型第一,立体匹配任务中也显著降低端点误差(EPE)和内存消耗,源代码已开源(https://github.com/alibaba/cascade-stereo)。
2. 研究动机与出发点
现有基于 3D 代价体的 MVS 和立体匹配方法存在核心瓶颈:内存和时间消耗随代价体分辨率(空间 + 深度)立方增长,导致难以处理高分辨率输入,只能通过下采样代价体 + 后续上采样 / 细化的方式输出结果,效率低且精度受限。此前的优化方案(如 Point-MVSNet 的点云细化、R-MVSNet 的循环正则化)虽有改进,但仍存在适配性局限或精度权衡问题。受粗到精学习型立体匹配方法启发,作者提出级联代价体框架,通过多阶段逐步缩小深度 / 视差搜索范围、提升空间分辨率,避免一次性处理全尺度代价体,在保证精度的同时大幅降低资源消耗,突破高分辨率重建的限制。
3. 创新点
- 级联代价体设计:将单一 3D 代价体分解为多阶段结构,前一阶段预测结果自适应缩小后一阶段的深度 / 视差范围(Rk=wk⋅Rk−1,wk<1),减少无效假设平面数量;
- 多尺度特征与分辨率协同:结合特征金字塔(FPN),各阶段代价体采用逐步提升的空间分辨率(MVS 任务从 1/16→1/4→1,立体匹配从 1/16→1/4),适配 “粗到精” 的细节恢复需求;
- 动态间隔调整:深度 / 视差间隔随阶段细化(Ik=pk⋅Ik−1,pk<1),粗阶段用大间隔快速定位大致范围,细阶段用小间隔捕捉精细结构;
- 可插拔兼容特性:无需重构基线网络,仅替换代价体模块即可集成到 MVSNet、PSMNet 等主流方法,适配 MVS 和立体匹配两类任务;
- 多阶段监督与独立参数学习:所有阶段均施加监督,且各阶段 3D CNN 正则化参数独立学习,避免参数共享导致的适配性不足,进一步提升精度。
4. 网络架构
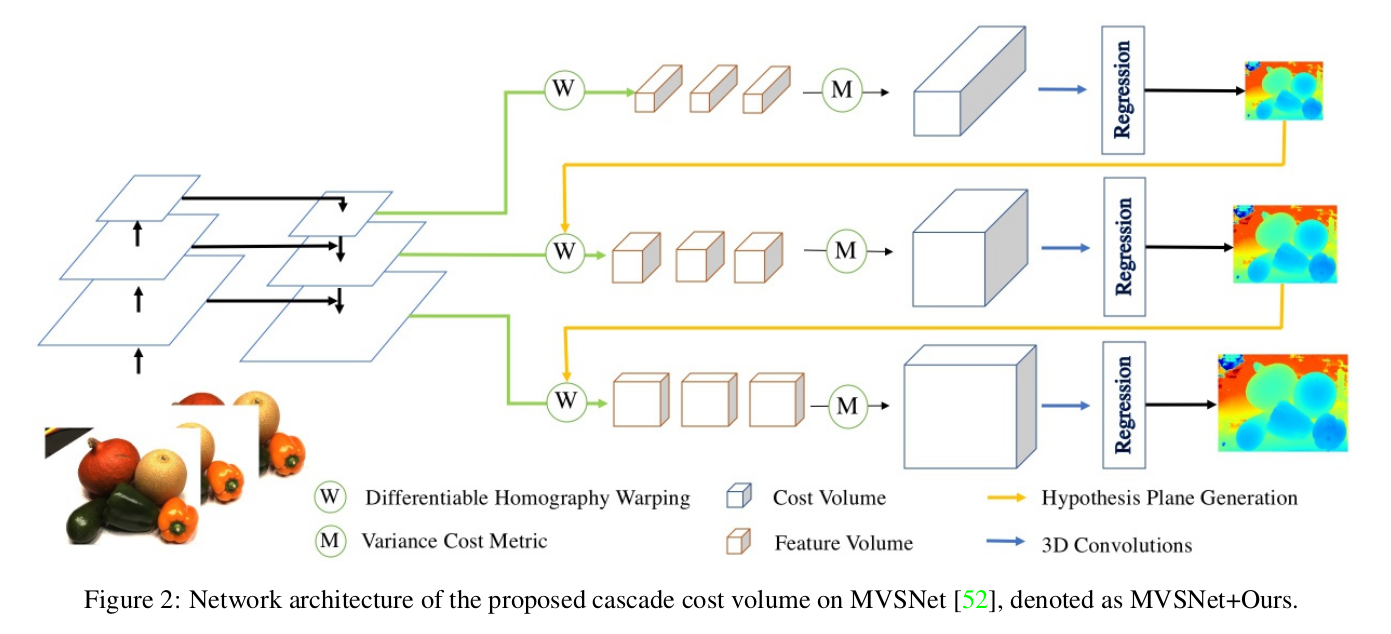
框架为 “多阶段级联 + 后处理” 结构,核心是 N 个串联的代价体处理单元(MVS 任务 N=3,立体匹配任务 N=2),整体流程如下:
- 输入层:多视图图像(MVS)或双目图像(立体匹配)、相机参数、初始深度 / 视差范围;
- 特征金字塔提取:生成多尺度图像特征,为各阶段代价体提供对应分辨率的特征输入;
- 级联代价体单元(每个阶段):基于前一阶段输出,确定当前阶段深度 / 视差范围、间隔和空间分辨率,构建代价体→3D CNN 正则化→输出中间深度 / 视差图;
- 后处理层:MVS 任务采用光度滤波、几何一致性滤波、深度融合(fusibile 工具);立体匹配任务采用视差细化,最终生成高分辨率 3D 点云(MVS)或视差图(立体匹配)。
网络采用三阶段级联架构:
- 第一阶段:低空间分辨率(1/16),大深度间隔,48个深度假设
- 第二阶段:中等空间分辨率(1/4),中等深度间隔,32个深度假设
- 第三阶段:高空间分辨率(1/1),小深度间隔,8个深度假设
每个阶段包含特征提取、代价体积构建、3D CNN正则化和深度回归。
5. 特征提取
采用特征金字塔网络(FPN)提取多尺度图像特征,所有输入视图共享同一特征提取网络:
- MVS 任务(3 阶段级联):特征金字塔包含 3 个尺度特征图,空间分辨率分别为输入图像的 1/16、1/4、1,对应 3 个阶段的代价体空间分辨率;
- 立体匹配任务(2 阶段级联):特征金字塔包含 2 个尺度特征图,空间分辨率为输入图像的 1/16、1/4,对应 2 个阶段的代价体空间分辨率;
- 特征提取网络:由多层 2D CNN 构成,包含卷积(Conv)、批归一化(BN)和 ReLU 激活,逐步下采样并提升通道数,为代价体构建提供富含语义和细节的特征表示。
6. 代价体构建
单应性变换公式:
关键参数设计:
- 深度假设范围:,
- 深度间隔:,
- 深度假设数量:
- 为待学习的深度残差;
- 第一阶段:覆盖整个场景的深度 / 视差范围R1,采用较大间隔I1;
7. 代价体正则化
- 每个阶段使用独立的3D CNN进行代价体积正则化
- 各阶段 3D CNN 参数独立学习(不共享),避免单一参数适配不同尺度 / 范围代价体的局限性, ablation 实验证明独立参数比共享参数性能更优。
8. 深度图生成
残差学习机制:
- 第一阶段回归绝对深度值
- 后续阶段回归深度残差:
深度回归:
- 使用soft argmin操作从概率体积回归深度值
- 每个阶段输出逐渐精细的深度图
- 最终输出由第三阶段生成
9. 损失函数
多阶段监督损失:
其中:
- :第k阶段的损失函数(MVS 任务用L1损失,立体匹配任务用端点误差(EPE)损失);
- :各阶段损失权重
- 实验中通过平衡各阶段贡献设置合适值,确保粗阶段快速收敛,细阶段聚焦细节优化。
10. 测试数据集
MVS 任务
- DTU 数据集:含 124 个场景、7 种光照条件,用于核心性能评估;
- Tanks and Temples 数据集:含 intermediate 集(8 个中等规模场景)和 advanced 集(大型复杂场景),验证泛化性和可扩展性。
立体匹配任务
- Scene Flow 数据集:大型合成数据集,含 35454 个训练对和 4370 个测试对,用于定量评估 EPE;
- KITTI 2015 数据集:真实道路场景数据集,含 200 个训练对和 200 个测试对,评估视差异常值比例;
- Middlebury 数据集:高分辨率立体匹配数据集,含 60 个图像对,验证高分辨率场景适配性。
11. 消融实验
(1)网络核心组件
级联阶段数:
- 2阶段:整体误差0.4314
- 3阶段:整体误差0.4310(最佳)
- 4阶段:整体误差0.4364
特征金字塔影响:
对比 “无特征金字塔(仅上采样特征)” 与 “有特征金字塔”,验证多尺度特征对精度和效率的提升;
- 无特征金字塔:整体误差0.453
- 有特征金字塔:整体误差0.355
参数共享:
对比 “各阶段 3D CNN 参数共享” 与 “独立学习”,证明独立参数更适配不同阶段代价体特性。
- 共享参数:整体误差0.4512
- 独立参数:整体误差0.4310
空间分辨率:
- 固定分辨率:性能较差
- 递增分辨率:显著提升精度
(2)代价体参数设置
- 深度 / 视差间隔:测试不同间隔缩放因子pk的影响,验证细阶段小间隔对细节恢复的作用;
- 深度 / 视差范围:分析范围缩小比例wk对覆盖真实深度的影响,确定合理范围以平衡效率和召回率。
(3)后处理组件
- MVS 任务:测试光度滤波、几何一致性滤波、深度融合的单独作用,验证各步骤对去除异常值、提升点云完整性的有效性;
- 立体匹配任务:测试视差细化步骤对减少阶梯效应、提升亚像素精度的影响。
12. 性能优势
内存效率:
- MVSNet+Ours:5345 MB
- 原始MVSNet:10823 MB
- 减少50.6%内存消耗
时间效率:
- MVSNet+Ours:0.492秒
- 原始MVSNet:1.210秒
- 减少59.3%运行时间
精度提升:
- DTU整体误差:从0.551mm提升至0.355mm
- Tanks and Temples:在深度学习方法中排名第一
 微信
微信- 支付宝

