
论文阅读_CVP-MVSNet
CVP-MVSNet(与CasMVSNet无区别)
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | Cost Volume Pyramid Based Depth Inference for Multi-View Stereo |
| 作者 | Jiayu Yang、Wei Mao、Jose M. Alvarez、Miaomiao Liu |
| 作者单位 | Australian National University(澳大利亚国立大学) |
| 时间 | 2020 |
| 发表会议/期刊 | CVPR |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 多视角 |
| 输出 | 参考视角深度图 |
| 所属领域 | MVS |
1. 摘要精简
提出一种基于成本体积金字塔(Cost Volume Pyramid)的多视图立体匹配(MVS)深度推断网络 CVP-MVSNet,以粗到精的方式构建成本体积,替代固定分辨率的单一成本体积。该方法先在图像金字塔的最粗分辨率层构建全深度范围的成本体积,再基于前一阶段的深度估计,迭代构建像素级深度残差的部分成本体积,实现深度图逐步细化。网络结构紧凑轻量化,在保证重建精度的同时,比 SOTA 方法(如 Point-MVSNet)快 6 倍,内存消耗减少 6 倍,在 DTU 和 Tanks and Temples 数据集上取得优异性能,源代码已开源(https://github.com/JiayuYANG/CVP-MVSNet)。
2. 研究动机与出发点
现有学习型 MVS 方法存在效率与内存的矛盾:MVSNet 的固定分辨率 3D 成本体积内存消耗随图像分辨率立方增长,难以适配高分辨率场景;R-MVSNet 的循环正则化虽降低内存,但运行时间延长;Point-MVSNet 基于点云迭代细化,速度随迭代次数线性增加。此外,现有方法未充分考虑深度采样与图像分辨率的关联,导致资源浪费。因此,作者提出成本体积金字塔框架,通过粗到精的成本体积构建,结合深度残差推断,在聚合上下文信息的同时优化内存与速度,实现高效高精度的深度推断。
3. 创新点
- 提出成本体积金字塔结构,以粗到精方式迭代构建成本体积,避免一次性处理全分辨率全深度范围的高内存开销;
- 揭示深度采样与图像分辨率的内在关联,制定科学的深度残差搜索范围与采样间隔原则,确保采样有效性;
- 基于规则图像网格构建残差成本体积,采用多尺度 3D CNN 正则化,相比 Point-MVSNet 的点云边缘卷积,更高效地聚合上下文信息;
- 网络结构紧凑,无需额外后处理,在相同精度下比 Point-MVSNet 快 6 倍、内存消耗低 6 倍,且支持高分辨率图像输入。
4. 网络架构构成
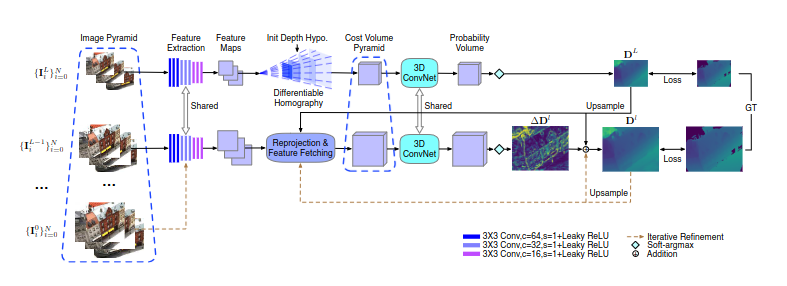
网络整体遵循 “图像金字塔→特征提取→成本体积金字塔→3D CNN 正则化→深度推断→多视图融合” 的流程,核心为成本体积金字塔的迭代构建与细化:
- 图像金字塔构建:将输入图像(参考图 + 源图)下采样生成 L+1 层金字塔,最底层为原始分辨率;
- 特征提取:权重共享的 2D CNN 为各层图像提取多尺度特征;
- 成本体积金字塔构建:从最粗层开始,先构建全深度范围成本体积得到粗深度图,再迭代构建残差成本体积细化深度;
- 3D CNN 正则化:对每层成本体积施加多尺度 3D 卷积,聚合空间与深度维度的上下文信息;
- 深度推断:通过 soft-argmax 将正则化后的概率体积转换为深度图,迭代叠加残差得到最终高分辨率深度图;
- 多视图融合:采用与 MVSNet 一致的深度图融合方法,生成 3D 点云。
5. 特征提取
采用权重共享的 9 层 2D 卷积网络,所有图像金字塔层级、所有输入视图(参考图 + 源图)共用同一网络:
- 网络结构:每层卷积后均接 LeakyReLU 激活函数,无批归一化;
- 下采样策略:通过卷积核步长自然适配图像金字塔的不同分辨率,无需额外下采样层;
- 特征输出:每层输出 16 通道特征图,特征图尺寸与对应图像金字塔层级的尺寸一致(即最粗层为H/2L×W/2L,最底层为H×W),为成本体积构建提供统一维度的特征表示。
6. 成本体积构建方式
成本体积分为"粗层全深度成本体积"和"细层残差成本体积"两类,均采用方差度量聚合多视图特征:
(1) 粗层全深度成本体积(最粗分辨率层 L)
- 深度采样:在全深度范围 内均匀采样 M 个平行平面,采样深度为
- 特征Warp:通过可微分单应变换将源图特征映射到参考图坐标系,单应矩阵为
其中 为第 i 个视图在 L 层的缩放内参,、 为相对旋转和平移, 为参考相机主轴;
- 方差成本计算:聚合参考图与所有源图的Warp特征,计算特征方差作为匹配成本,公式为
其中 为第 i 个视图在深度 d 的Warp特征, 为所有视图特征的均值;
- 成本体积拼接:将 M 个深度的成本图拼接为 的成本体积(F=16 为特征通道数)。
(2) 细层残差成本体积(层级 )
-
深度残差假设:对前一阶段( 层)的深度图 进行双三次上采样,得到 ,围绕每个像素的上采样深度 ,设置 M 个深度残差假设 , 为残差采样间隔;
-
残差范围确定:通过将参考图像素投影到源图极线,取极线上偏离投影点 2 个像素的两点,反投影回参考图视觉射线,得到深度残差的搜索范围;
-
部分成本体积构建:采用与粗层一致的方差成本计算方式,构建 的部分成本体积,仅覆盖残差范围。
7. 代价体正则化
使用多尺度3D CNN对代价体进行正则化;输出为概率体 ,表示每个深度假设的概率;增强局部平滑性并扩大感受野。
8. 深度图生成
最粗层:
使用 soft-argmax 从概率体中回归深度:
逐层细化:
根据残差概率体更新深度:
9. 损失函数
使用 损失在金字塔所有层级上监督深度图:
其中:
- Ω为有地面真值(GT)的有效像素集;
- 为第 l 层的 GT 深度图(通过下采样原始 GT 得到);
- 为第 l 层的预测深度图;
- L为图像金字塔的总层数。
10. 测试数据集
- DTU 数据集:含 124 个室内场景,7 种光照条件,49 或 64 个拍摄视角,提供 GT 点云和相机参数,用于核心性能评估;
- Tanks and Temples 数据集:含室内外真实场景,分为 Intermediate 集(中等规模)和 Advanced 集(大规模复杂场景),用于验证模型泛化性。
11. 消融实验
消融实验在 DTU 数据集上进行,验证核心参数与设计的有效性:
- 金字塔层级数量:测试 2、3、4、5 层金字塔对重建精度的影响,结果表明 2 层为最优(最粗层 80×64,最底层 160×128),层级过多会导致粗层分辨率过低,影响初始深度估计质量;
- 像素间隔设置:测试深度残差搜索范围对应的像素间隔(0.25、0.5、1、2 像素),结果表明间隔过窄(0.25 像素)或过宽(2 像素)均会导致精度下降,0.5 或 1 像素为最优选择,验证了深度采样与图像分辨率关联原则的合理性。
其他亮点
- 支持输出与输入图像相同分辨率的深度图;
- 自适应残差搜索范围:基于极线几何自动计算每个像素的深度残差搜索范围,确保覆盖真实深度的同时避免无效采样;
- 特征共享与高效推断:所有图像金字塔层级共享特征提取网络与 3D CNN 正则化网络参数,减少模型参数量,提升推断效率;
- 无额外后处理:网络输出的深度图无需 DenseCRF 或变分细化,直接通过多视图融合即可生成高质量点云,简化流程。
 微信
微信- 支付宝

