
论文阅读_CIDER
CIDER(Correlation cost volume and Inverse DEpth Regression)其实是抄CwcNet这个stereo网络
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | CIDER(Correlation cost volume and Inverse DEpth Regression) |
| 作者 | Qingshan Xu、Wenbing Tao |
| 作者单位 | Huazhong University of Science and Technology(华中科技大学) |
| 时间 | 2019 |
| 发表会议/期刊 |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 多视角 |
| 输出 | 参考视角深度图 |
| 所属领域 | MVS |
1. 摘要精简
提出一种基于相关代价体和逆深度回归的多视图立体匹配(MVS)方法 CIDER,解决现有方法的可扩展性和精度瓶颈。该方法通过平均分组相关相似度度量构建轻量级代价体,大幅降低内存消耗和计算负担;采用级联 3D U-Net 对代价体进行正则化,聚合更多上下文信息;将 MVS 任务重新定义为逆深度回归任务,实现亚像素精度估计并适配大规模场景。在 DTU 和 Tanks and Temples 数据集上的实验表明,CIDER 取得 SOTA 性能,在可扩展性和精度上表现优异,源代码即将开源(https://github.com/GhiXu/CIDER)。
2. 研究动机与出发点
现有深度学习 MVS 方法存在两大核心问题:一是代价体表示内存消耗巨大,限制大规模和高分辨率场景应用(如 MVSNet 的 32 通道代价体内存占用高);二是深度推断方式不合适,传统深度回归在非校正图像中会导致极线方向采样不均,逆深度分类则引入阶梯效应,需额外后处理(如 R-MVSNet 的变分细化、DeepMVS 的 DenseCRF)。此外,R-MVSNet 的循环正则化虽减少内存,但无法像 3D U-Net 那样聚合足够上下文信息,性能受限。因此,本文旨在通过轻量级代价体、高效正则化和合理的深度推断方式,同时解决内存和精度问题。
3. 创新点
- 提出平均分组相关相似度度量,将多视图特征按通道分组计算内积相似度,平均多源视图结果得到 8 通道轻量级代价体,无需额外压缩模块,内存消耗大幅降低;
- 设计级联 3D U-Net用于代价体正则化,通过两次 3D U-Net 串联和残差连接,聚合多尺度上下文信息,有效处理模糊区域深度估计;
- 将 MVS 任务定义为逆深度回归任务,在逆深度空间均匀采样假设,确保极线方向采样均匀,实现鲁棒亚像素估计,适配大规模场景;
- 支持任意数量输入视图,通过平均多源视图代价体聚合信息,无需复杂适配机制。
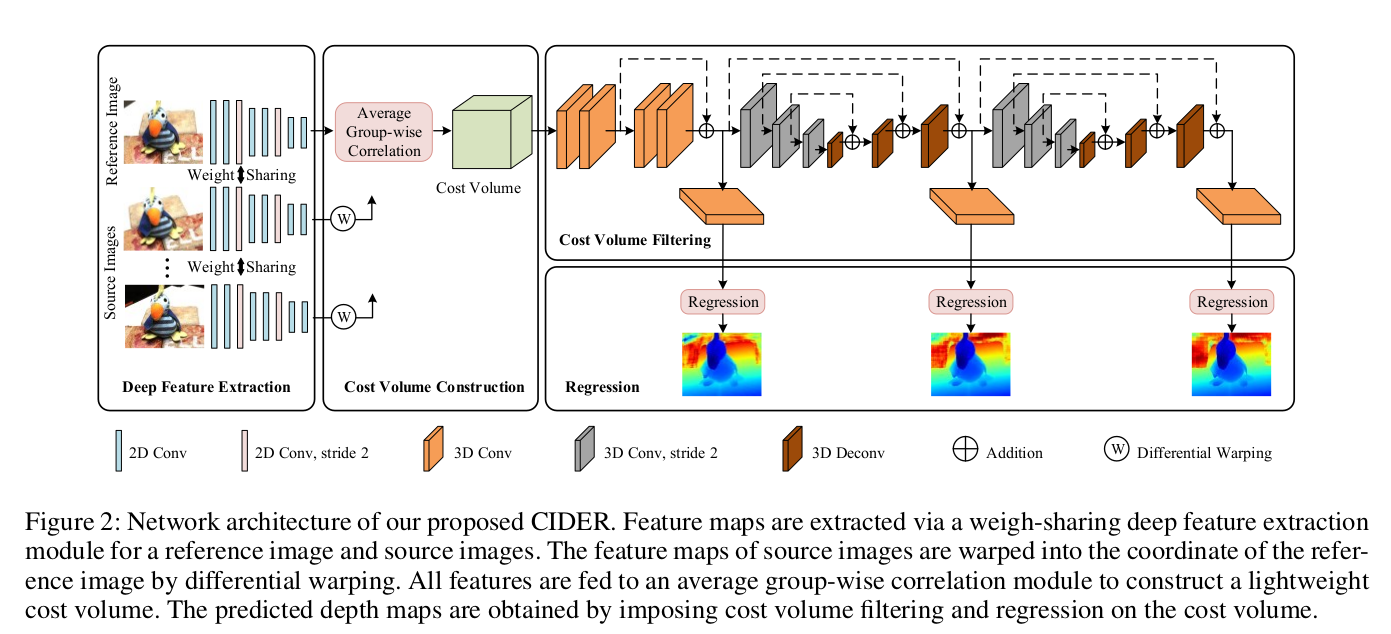
4. 网络架构
网络整体由四个核心模块串联组成,流程为 “特征提取→代价体构建→代价体滤波→逆深度回归”:
- 深度特征提取模块:权重共享的 2D CNN,为参考图和源图提取多尺度深层特征;
- 相关代价体构建模块:通过微分 warp 将源图特征映射到参考图坐标系,利用平均分组相关度量聚合多视图特征,生成轻量级代价体;
- 代价体滤波模块:包含残差模块和两级串联的 3D U-Net,对代价体进行逐步正则化,抑制噪声并聚合上下文;
- 逆深度回归模块:三个并行输出分支,将滤波后的代价体转换为概率分布,回归亚像素逆深度序数,最终转换为深度值。
5. 特征提取
采用与 MVSNet 类似的多尺度 2D CNN,所有输入图像(参考图 + 源图)共享权重:
- 网络结构:共 8 层卷积,前 7 层含批归一化(BN)和 ReLU 激活(部分层除外),最后 1 层无激活;
- 下采样策略:通过两次步长为 2 的 5×5 卷积实现下采样,最终特征图尺寸为输入图像的 1/4;
- 通道变化:从输入 3 通道逐步提升至 32 通道,最终输出 32×(H/4)×(W/4) 的深层特征,为后续分组相关计算提供基础。
6. 代价体构建
核心是 “微分 warp + 分组相关 + 多视图平均”,构建 8 通道轻量级代价体:
逆深度采样公式:
将参考图特征和源图 warp 后特征按通道均匀分为 G=8 组,第 g 组相似度为
多视图聚合:将每个源图与参考图的 G 通道代价体(尺寸 G×(H/4)×(W/4)×D)平均,得到最终 8 通道代价体,N 为输入视图总数。
7. 代价体正则化
采用级联 3D U-Net 进行正则化,包含残差模块和两级 3D U-Net 串联:
- 前置残差模块:3 层 3D 卷积 + 残差连接,对原始 8 通道代价体进行初步特征增强;
- 第一级 3D U-Net:通过 3 次步长为 2 的 3D 卷积下采样(通道数从 8→16→32→64),再通过 3 次步长为 2 的 3D 反卷积上采样,与对应下采样特征拼接(跳连),输出 8 通道代价体;
- 第二级 3D U-Net:重复第一级结构,进一步聚合上下文信息,抑制噪声;
- 正则化优势:级联结构比单级 3D U-Net 捕捉更丰富的多尺度信息,轻量级代价体为两级 U-Net 提供内存支持,避免 MVSNet 等单一代价体无法采用复杂正则化的问题。
8. 深度图生成(变分深度图优化)
逆深度假设采样:在逆深度空间均匀采样 D 个深度假设,公式为
亚像素序号回归::三个输出分支分别从残差模块、第一级 U-Net、第二级 U-Net 输出中提取特征,通过 3D 卷积转换为 1 通道概率体积,经 softmax 得到各深度假设的概率pj,回归亚像素序数k
深度转换:将序数 k 转换为最终深度
后处理:计算每个像素的 4 邻域概率累积作为置信度,过滤置信度 < 0.8 的像素;要求像素至少三视图一致(相对深度差 < 0.01 且重投影误差 < 1 像素),融合多视图深度得到最终 3D 点云。
9. 损失函数
多阶段监督损失:
其中:
- d为地面真值(GT)深度图,$\hat{d}_q $(q=0,1,2)分别为残差模块、第一级 U-Net、第二级 U-Net 对应的预测深度图;
- , ,
- :平均绝对误差(MAE)
11. 消融实验测试组件
消融实验基于 Base 模型(采用 MVSNet 的方差相似度、单级 3D U-Net、深度回归),在 Tanks and Temples 训练集上验证核心组件有效性:
- 平均分组相关相似度(AGC):替换 Base 模型的方差相似度,验证轻量级代价体的内存优势和性能保持情况;
- 逆深度回归(IDR):在 AGC 模型基础上替换深度回归为逆深度回归,验证采样均匀性对大规模场景性能的提升;
- 级联 3D U-Net 滤波:在 AGC-IDR 模型基础上添加第二级 3D U-Net,验证级联正则化对模糊区域噪声抑制的效果;
- 深度假设数量(D):测试 D=192 和 D=256 对性能的影响,验证更多假设对精度的提升。
Base模型:方差相似性 + 3D U-Net滤波 + 深度回归
AGC模型:平均分组相关性相似性
- 内存:11.1GB → 6.5GB(减少41%)
- 性能保持相似
AGC-IDR模型:AGC + 逆深度回归
- 分数:22.67% → 46.96%(显著提升)
- 证明逆深度回归的有效性
CIDER完整模型:AGC-IDR + 级联3D U-Net
- 分数:46.96% → 48.66%
- 内存仅轻微增加(6.5GB → 7.4GB)
12. 性能优势
内存效率:
- CIDER:7.4GB (D=192), 9.6GB (D=256)
- MVSNet:11.7GB
- 内存消耗显著降低
时间效率:
- CIDER:3.11秒
- R-MVSNet:8.57秒
- 运行速度更快
精度表现:
- DTU整体误差:0.427mm(优于MVSNet的0.462mm)
- Tanks and Temples:在深度学习方法中表现优异
- 无需变分优化即可达到亚像素精度
 微信
微信- 支付宝

