
论文阅读_CDS-MVSNet
CDS-MVSNet(Curvature-Guided Dynamic Scale Networks for Multi-view Stereo)
基本信息
| 项目 | 内容 |
|---|---|
| 论文标题 | CDS-MVSNet(Curvature-Guided Dynamic Scale Networks for Multi-view Stereo) |
| 作者 | Khang Truong Giang, Soohwan Song, Sungho Jo |
| 作者单位 | 韩国科学技术院(KAIST) |
| 时间 | 2022 |
| 发表会议/期刊 | ICLR |
方法概览
| 特点 | 文章性质 |
|---|---|
| 输入 | 标定之后的多视角图像 |
| 输出 | 场景的点云图,每个视角的法线和深度图 |
| 所属领域 | MVS |
摘要精简
本文提出一种基于曲率引导动态尺度特征提取的多视图立体网络 CDS-MVSNet,核心是曲率引导动态尺度特征网络(CDSFNet)。**CDSFNet 由新型曲率引导动态尺度卷积(CDSConv)构成,通过图像表面法向曲率自适应选择每个像素的最优卷积核尺度,**提升特征匹配的判别性。结合基于曲率的可见性加权代价聚合策略,CDS-MVSNet 能在复杂室外场景中提升重建完整性,同时仅处理半分辨率图像即可维持高重建质量,实现更快运行速度和更低内存消耗。该方法在 DTU 和 Tanks & Temples 数据集上表现优异,优于现有主流 MVS 方法。
其实就是把VisMVSNet中的特征提取换成CDSConv
研究动机与出发点
多视图立体(MVS)的核心挑战是从高分辨率图像中精确估计稠密对应关系,现有学习型 MVS 方法虽在代价体构建和正则化上有改进,但特征提取存在明显缺陷:
-
传统 CNN 采用固定尺寸卷积核,感受野受限,难以适应图像中物体的极端尺度变化,导致匹配模糊,尤其在参考图与源图相机姿态差异较大时;
-
为控制内存和计算量,现有方法常基于低分辨率图像训练,固定尺度的特征表示无法泛化到高分辨率图像,导致重建性能下降。
为解决上述问题,作者提出动态尺度特征提取网络,适配不同物体尺度和图像分辨率,同时降低计算与内存消耗,提升 MVS 重建的精度和效率。
创新点
- 提出曲率引导动态尺度卷积(CDSConv):通过计算图像表面在多个候选尺度下的法向曲率,结合分类网络自适应选择每个像素的最优卷积核尺度,适配纹理、物体尺度和极线几何;
- 设计 CDSFNet 特征提取网络:由多个 CDSConv 层构成 U-Net 类架构,能学习像素级动态尺度特征,减少匹配模糊,且支持深度堆叠以扩展尺度搜索空间;
- 提出 CDS-MVSNet 框架:采用粗到精的级联结构,利用 CDSFNet 输出的法向曲率隐式编码特征匹配能力,实现基于曲率的可见性加权代价聚合;仅处理半分辨率图像即可输出高分辨率深度图,大幅降低计算量和内存消耗;
- 在 DTU 和 Tanks & Temples 数据集上取得 state-of-the-art 性能,尤其在复杂室外场景的重建完整性和高分辨率图像处理效率上表现突出。
网络架构
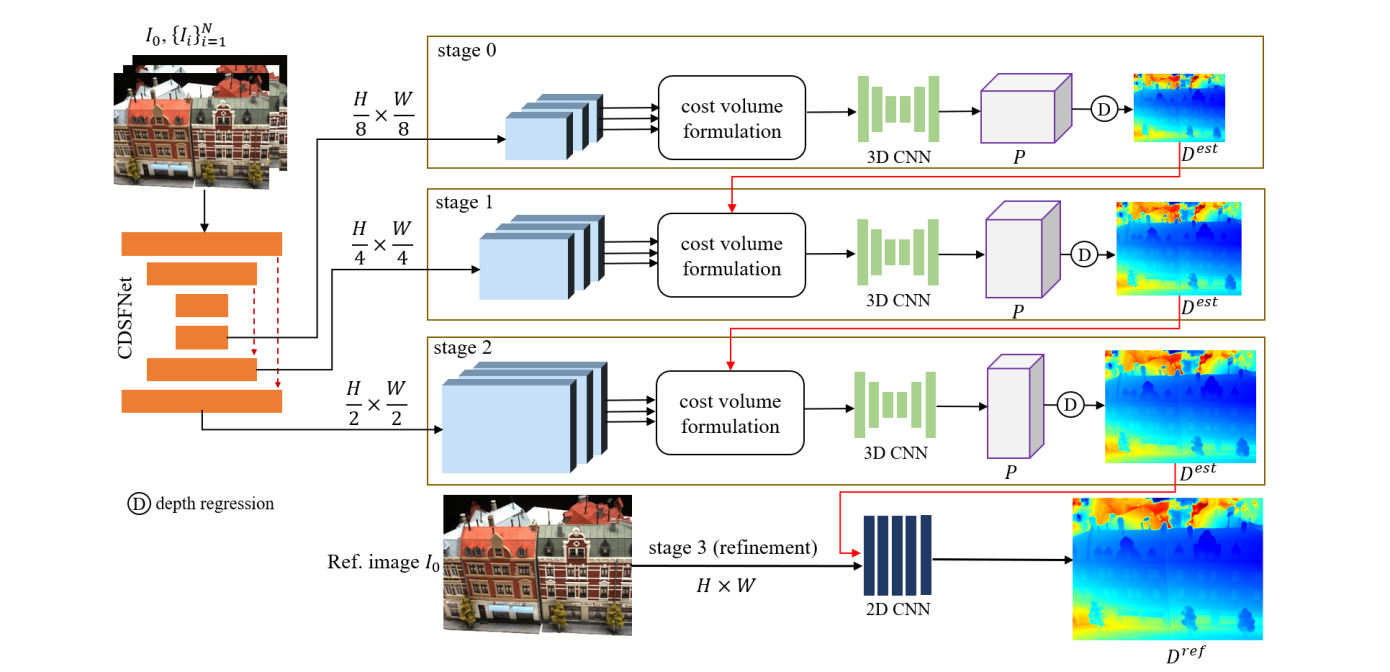
CDS-MVSNet 采用粗到精的级联架构,整体分为 4 个核心阶段:
- 输入:1 张参考图像 + N 张源图像,以及对应的相机参数(用于计算极线几何);
- 特征提取阶段:通过 CDSFNet 为每个参考 - 源图对提取动态尺度特征图和法向曲率图,输出 3 个不同分辨率的特征(对应级联阶段 0、1、2);
- 级联深度估计阶段(阶段 0-2):每个阶段依次执行代价体构建、3D CNN 正则化和深度回归,前一阶段的深度输出用于缩小后一阶段的深度假设范围;
- 深度细化阶段(阶段 3):将阶段 2 的半分辨率深度图上采样至原始分辨率,通过 2D CNN 残差细化得到最终深度图;
- 后处理:过滤低置信度深度,融合得到 3D 稠密点云。
5. 特征提取过程
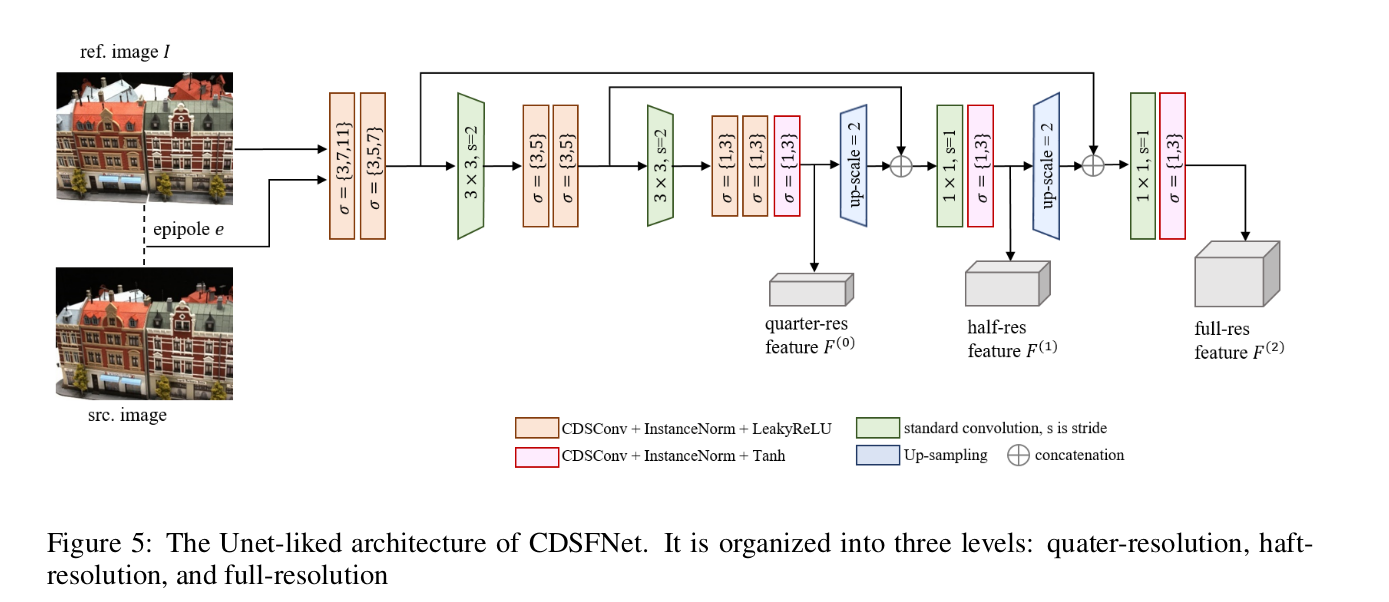
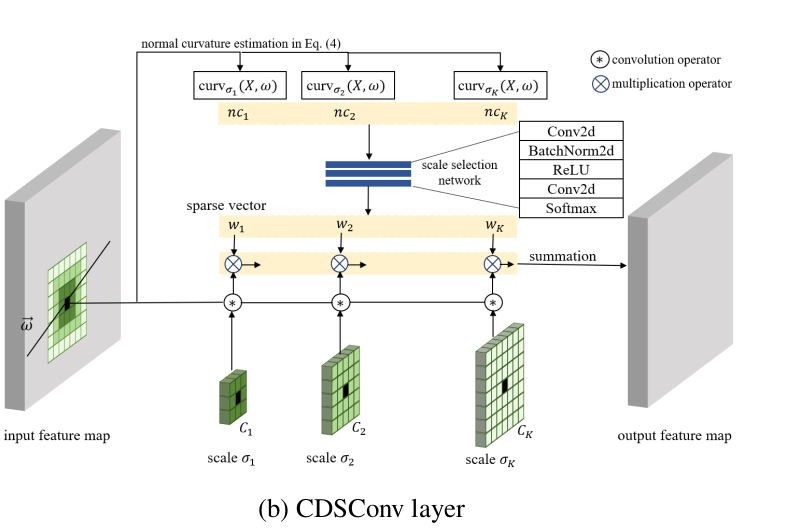
特征提取的核心是 CDSFNet(U-Net 类架构),其核心组件为 CDSConv,具体流程如下:
-
CDSConv 输入:输入特征 $$F^{in}$$,极线方向 $$\omega = [u, v]^T$$,以及 K 个候选尺度对应的卷积核 $${C_1, C_2, …, C_K}$$;
-
可学习法曲率计算:引入 3 个可学习卷积核 $$K_{\sigma}^{\overline{xx}}, K_{\sigma}^{\overline{xy}}, K_{\sigma}^{\overline{yy}}$$,近似计算特征图在该尺度下的二阶导数,法向曲率公式为:
其中 $$|K_{\sigma}^{(.)}| \to 0$$,通过正则化约束其范围;
-
尺度选择:通过含有卷积块的轻量 CNN 处理 K 个候选尺度的曲率,输出 one-hot 权重向量 $$[w_1, w_2, …, w_K]$$(Softmax 激活,带小温度参数);
-
特征融合:加权求和不同尺度卷积核的输出,得到动态尺度特征:
- CDSFNet 输出:3 个分辨率的特征图 $$F^{(0)}, F^{(1)}, F^{(2)}$$ 和对应的法向曲率图 $${NC^{est,(0)}, NC^{est,(1)}, NC^{est,(2)}}$$。
6. 代价体构建过程和VisMVSNet类似
代价体构建分为两视图代价计算和多视图加权聚合两步:
- 两视图代价计算:对每个深度假设 $$d_j$$,通过极线几何将源视图特征 $$F_i$$ warp 到参考相机平面,得到 $$F_i^w(d_j)$$;
计算参考特征 $$F_{0,i}$$ 与 $$F_i^w(d_j)$$ 的像素级内积,作为两视图匹配代价:
- 多视图加权聚合:
- 计算两视图代价体的熵 $$H_i$$,衡量匹配不确定性:
-
通过 2D CNN ($$Vis(\cdot)$$) 整合法向曲率 $$NC_i^{est}$$ 和熵 $$H_i$$,预测视图权重 $$W_i$$(编码特征匹配可靠性);
-
加权平均得到聚合代价:
代价体正则化
使用3D CNN将聚合的匹配代价体正则化为深度概率体,深度通过期望回归:
深度图生成
级联回归:阶段 0-2 分别输出对应分辨率的深度图,前一阶段深度用于缩小后一阶段的深度假设范围,逐步提升精度;
上采样与细化:阶段 3 将阶段 2 的半分辨率深度图上采样至原始分辨率,输入 2D CNN 残差网络;结合参考图 RGB 信息,网络输出深度残差,与上采样深度相加得到细化深度图:
损失函数
总损失:
其中,,是第 l 阶段预测深度与地面真值的 L1 损失,衡量深度回归精度。
特征损失:为训练 CDSFNet 设计,基于匹配代价的二分类交叉熵,含权重和法向曲率正则项:
测试数据集
- DTU数据集:室内场景,用于深度图评估
- BlendedMVS数据集:大规模合成数据集,用于训练和定性评估
- Tanks & Temples基准:大型室外场景,评估重建点云的F-score
消融实验
- 可学习曲率vs原始曲率:比较了四种模型变体,证明可学习曲率在性能和计算效率上的优势
- 曲率引导的可见性聚合:验证了法曲率先验对可见性预测的有效性
- CDSFNet候选尺度数量:测试了1-4个候选尺度,发现增加尺度数可提升性能但增加计算量
- 级联结构各阶段贡献:分析了四个阶段对深度估计精度的影响,前三个阶段贡献主要精度
曲率引导的动态尺度机制详解
CDSConv通过分析图像表面沿极线方向的法曲率来选择最优尺度:
- 薄结构/纹理丰富区域:选择小尺度以保留局部细节
- 无纹理区域:选择大尺度以获取更多上下文信息
- 适应图像分辨率:低分辨率图像倾向于小尺度,高分辨率图像倾向于大尺度
- 考虑极线约束:参考图像的特征会根据每个源图像的不同而变化,适应不同的相机位姿差异
该机制使得网络能够为每个像素在匹配过程中捕获相同上下文信息,提取可匹配的特征,显著减少匹配模糊性。
 微信
微信- 支付宝

