
实践日记_eastMocapInstallUsage
eastMocap Install and Usage
easymocap关键点检测模块可以用HRNet或者Openpose
每次改完代码要python setup.py develop–uninstall 再 python setup.py develop
Install OpenPose(拼尽全力无法战胜)
1 | git clone https://github.com/CMU-Perceptual-Computing-Lab/openpose.git --depth 1 |
1 | # 解决OPENPOSE下载权重那一步骤太慢问题 |
1 | # 解决OPENPOSE在make时候报一堆Protobuf 的版本问题,需要确保系统中安装的 protoc 编译器版本与头文件版本一致。 |
Install HRNet
代码里面有HRNet
下载 yolov4.weights 并将其放入 data/models/yolov4.weights 中,因为HRnet是一个单人人体关键点回归算法,所以需要YOLO先把人取出来
1 | mkdir -p data/models |
下载预训练的 HRNe权重 pose_hrnet_w48_384x288.pth from (OneDrive)[https://1drv.ms/f/s!AhIXJn_J-blW231MH2krnmLq5kkQ],打开之后只下载coco中的w48 384*288 按如下方式放置它们
1 | data |
各种SMPL
SMPL(2015)
- 最基本的人体模型:只建模躯干 + 四肢
- 由:
- pose 参数(72维:24个关节 × 每个关节3D旋转)
- shape 参数(10维 PCA 模型)控制身高胖瘦等体型
- 输出:
- 6890个 mesh 顶点
- 24 个 3D joints
- 无手指、无表情、无脸部
- 常用于:人体姿态估计、SMPLify 等
SMPL+H(2017)
- 在 SMPL 基础上加入了两只手的模型(MANO)
- H = Hand,即:SMPL + Hand
- 总共支持:
- 身体:24个关节
- 双手:各15自由度
- 手的姿势也用 axis-angle(或 rotation matrix)建模
- 表情、眼睛、嘴巴仍然不支持
- 常用于:全身+手姿估计(如手势识别)
SMPL-X(2019)
SMPL-X = SMPL eXtended
- 最完整的模型,涵盖:
- 身体 + 手指 + 面部
- 参数结构:
shape: 10维body_pose: 63维left_hand_pose: 45维right_hand_pose: 45维jaw_pose: 3维expression: 10维global_orient: 3维
- 顶点数增加为 10,475
- 支持表情控制(表情参数 + 下颌旋转)
- 常用于:高级人体建模、交互动作、表情估计、动画等
要下载 SMPL 模型,请访问此 (男性和女性模型,版本 1.0.0,10 形 PC)和此 (性别中立模型)项目网站并注册以访问下载部分。
要下载 SMPL+H 模型,请访问此项目网站并注册以访问下载部分。
要下载 SMPL-X 模型,请访问此项目网站并注册以访问下载部分。
按如下方式放置它们data/bodymodels/:
1 | data |
To check the model, please install and use our 3D visualization tool:
1 | python3 apps/vis3d/vis_smpl.py --cfg config/model/smpl.yml |
如果想用于单视角二维升三维的算法,这里推荐SPIN
这部分用在 1v1p*.py 中。如果你只使用多视图数据集,可以跳过这一步。
在此处下载预训练的 SPIN 模型并将其放置到 data/models/spin_checkpoints.pt .
在此处获取额外的数据,并将 smpl_mean_params.npz 放入 data/models/smpl_mean_params.npz .
安装主仓库
1 | python>=3.6 |
可视化的库
Install Pyrender
1 | pip install pyrender |
Install Open3D
Open3D is used to perform realtime visualization and SMPL visualization with GUI. No need for this if you just run the fitting code.
1 | python3 -m pip install -U pip # run this if pip can not find this version |
Install PyTorch3D
1 | https://github.com/facebookresearch/pytorch3d/blob/364a7dcaf4b285cc93c70e0b5d9eb9bbf42389a5/INSTALL.md |
如何使用
整理数据
SMPL24点模型
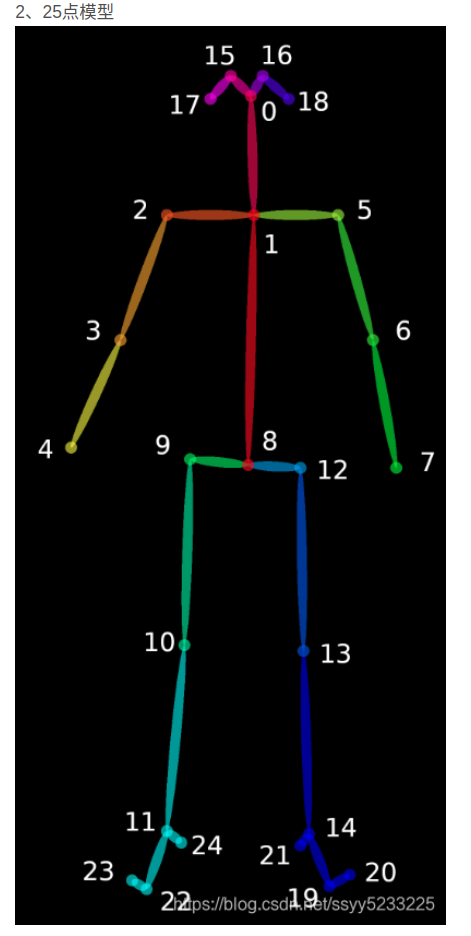
Openpose25
1 | {0, “Nose”}, |
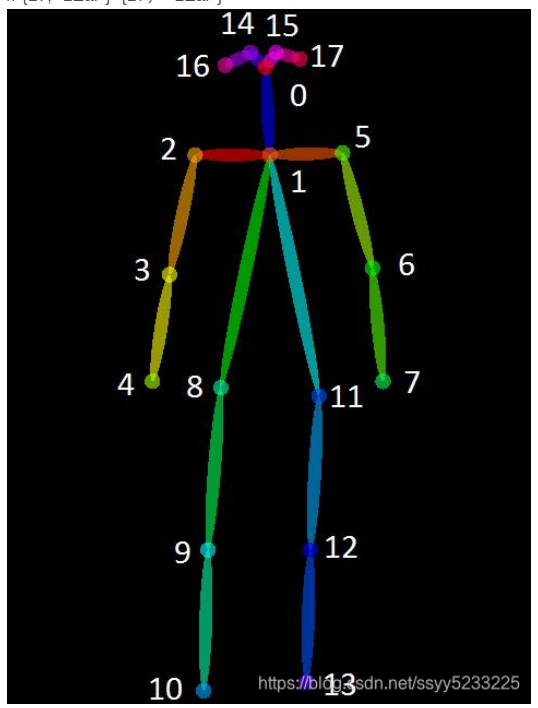
Openpose17
COCO17
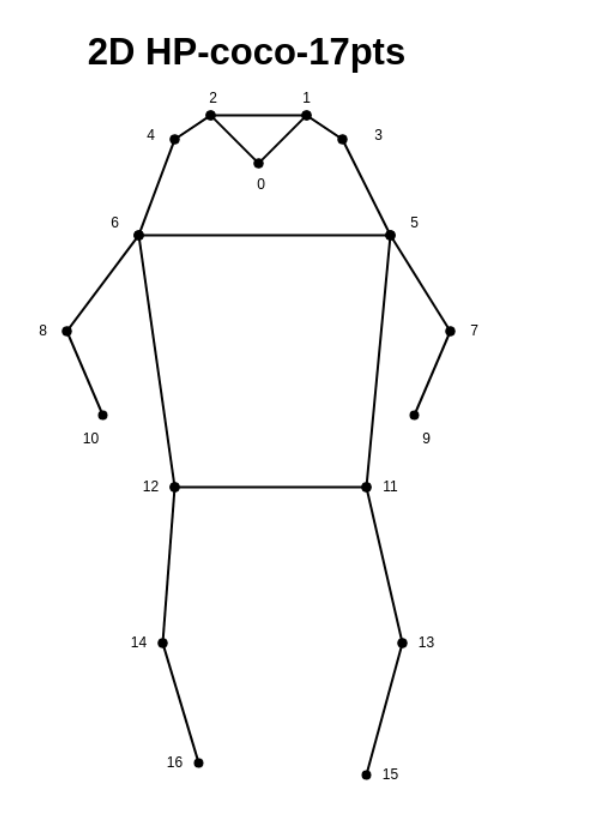
1 | 'joint_names': [ |
1 | # Alphapose全22个点转化到Openpose的关系 |
1 | # 整理前的数据 |
1 | # 处理数据,把openpose的结果再次处理,改成75点的一个格式,放在annots |
1 | # 整理完的数据 |
重建
1 | # --path |
编写一个python文件,输入一个类似alphapose-result2_merged.json的json文件,在json文件目录下建立同名的文件夹,然后基于json文件中的多帧信息,创建每个帧的骨架信息,按照000000_keypoints.json的openpose的格式,具体而言:把alphapose的json文件中每一帧都创建一个json文件,然后json文件中keypoints本是22个骨架关节关键点,映射为openpose的pose_keypoints_2d和hand_left_keypoints_2d和hand_right_keypoints_2d,在单帧的映射过程中,
alphapose的第0个点鼻子对应openpose中pose_keypoints_2d的0点
alphapose的第1个点左眼对应openpose中pose_keypoints_2d的16点
alphapose的第2个点右眼对应openpose中pose_keypoints_2d的15点
alphapose的第3个点左耳朵对应openpose中pose_keypoints_2d的18点
alphapose的第4个点右耳朵对应openpose中pose_keypoints_2d的17点
alphapose的第5个点左肩膀对应openpose中pose_keypoints_2d的5点
alphapose的第6个点右肩膀对应openpose中pose_keypoints_2d的2点
alphapose的第7个点左胳膊肘对应openpose中pose_keypoints_2d的6点
alphapose的第8个点右胳膊肘对应openpose中pose_keypoints_2d的3点
alphapose的第9个点左手腕对应openpose中pose_keypoints_2d的7点
alphapose的第10个点右手腕对应openpose中pose_keypoints_2d的4点
alphapose的第11个点左髋关节对应openpose中pose_keypoints_2d的12点
alphapose的第12个点右髋关节应openpose中pose_keypoints_2d的9点
alphapose的第13个点左去去应openpose中pose_keypoints_2d的13点
alphapose的第14个点右膝盖对应openpose中pose_keypoints_2d的10点
alphapose的第15个点左脚踝对应openpose中pose_keypoints_2d的14点
alphapose的第16个点右脚踝对应openpose中pose_keypoints_2d的11点
alphapose的第17个点左脚尖对应openpose中pose_keypoints_2d的20点
alphapose的第18个点右脚尖对应openpose中pose_keypoints_2d的23点
至于openpose中pose_keypoints_2d的1点中胸位置,取alphapose的第5个点左肩膀和第6个点右肩膀的中点
至于openpose中pose_keypoints_2d的8点腹部位置,取alphapose的第11个点左髋和第12个点右髋的中点
然后把
alphapose的第9个点左手腕对应openpose中hand_left_keypoints_2d的0点
alphapose的第10个点右手腕对应openpose中hand_right_keypoints_2d的0点
alphapose的第19个点左手手背对应openpose中hand_left_keypoints_2d的9点
alphapose的第20个点右手手背对应openpose中hand_right_keypoints_2d的9点
alphapose的第21个点腰部,目前没有放在openpose中
其余的没有映射的点都是0 0 0
用python写一个软件,输入一个这样的一个json文件和想要输出相机camera的id,id有多个,没输入id则默认全部相机参数都输出
将其中的相机参数导出为extri.yml和intri.yml,这两个yml导出形式是opencv标定的格式,需要你把json文件中指定id相机参数根据Transform的平移矩阵和旋转矩阵参数输出到extri.yml中,把Instrinsic中的相机内参,根据json文件中的名称整理为opencv的相机内参格式,输出到intri.yml,并且两个yml的输出名称为json的名称_extri或者名称_intri
用python写一个软件,输入一个这样的一个json文件和想要输出相机camera的id,id有多个,没输入id则默认全部相机参数都输出
将其中的相机参数导出为extri.yml,导出形式是opencv标定的格式,需要你把json文件中指定id相机参数根据Transform的平移矩阵和旋转矩阵参数输出到extri.yml中输出名称为json的名称_extri
报错整理
几个帧在一起少同几个关节不会报错
单独一帧少几个关节不会报错
ANNOT不符合规范
1 | Traceback (most recent call last): |
如果annots少一个帧的json文件,这里annots/2少一个第20.json
1 | python apps/demo/mv1p.py ../zju-ls-feng_TestData --out ../zju-ls-feng_TestData/outputTest2loss20annots --vis_det --vis_repro --undis --sub_vis 2 5 9 --vis_smpl --start 20 --end 25 |
如果annots多一个帧的json文件,这里annots/2多一个20_copy.json
1 | python apps/demo/mv1p.py ../zju-ls-feng_TestData --out ../zju-ls-feng_TestData/outputTest2loss20annots --vis_det --vis_repro --undis --sub_vis 2 5 9 --vis_smpl --start 20 --end 25 |
如果多的或者少的是start/end之外的帧则不会报错
如果start/end包含的帧太少,至少三帧
1 | python apps/demo/mv1p.py ../zju-ls-feng_TestData --out ../zju-ls-feng_TestData/outputTest2loss20annots --vis_det --vis_repro --undis --sub_vis 2 5 9 --vis_smpl --start 20 --end 22 |
不知道怎么错的
1 | python apps/demo/mv1p.py ../dataOpenpose202403270042 --out ../dataOpenpose202403270042/output --vis_det --vis_repro --undis --sub_vis 5 13 --vis_smpl --start 0 --end 5 |
改了例程的intri.yml,也报错
1 | Traceback (most recent call last): |
另外如果output里面有keypoint3d文件,那么运行的时候会优先读取3d文件,如果上一次3d文件就是错的,那还是会报这个错
可视化一个smpl模型
1 | python apps/vis3d/vis_smpl.py --param_path /home/outbreak/HPE/easyMocap/dataOpenpose202403270042/outputFrom3d/smpl/000020.json |
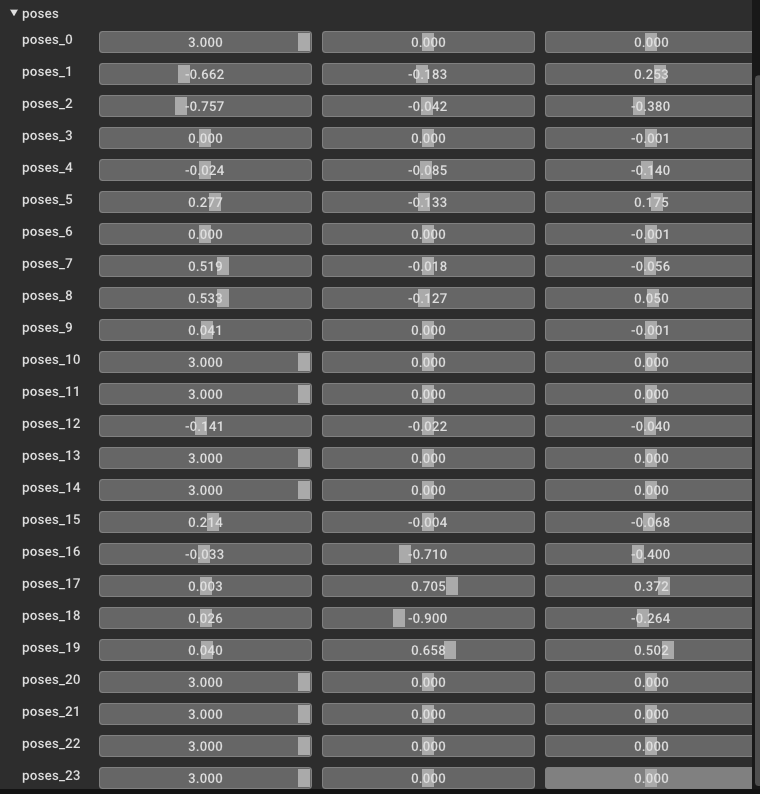
测试我的插值
起始帧


结束帧


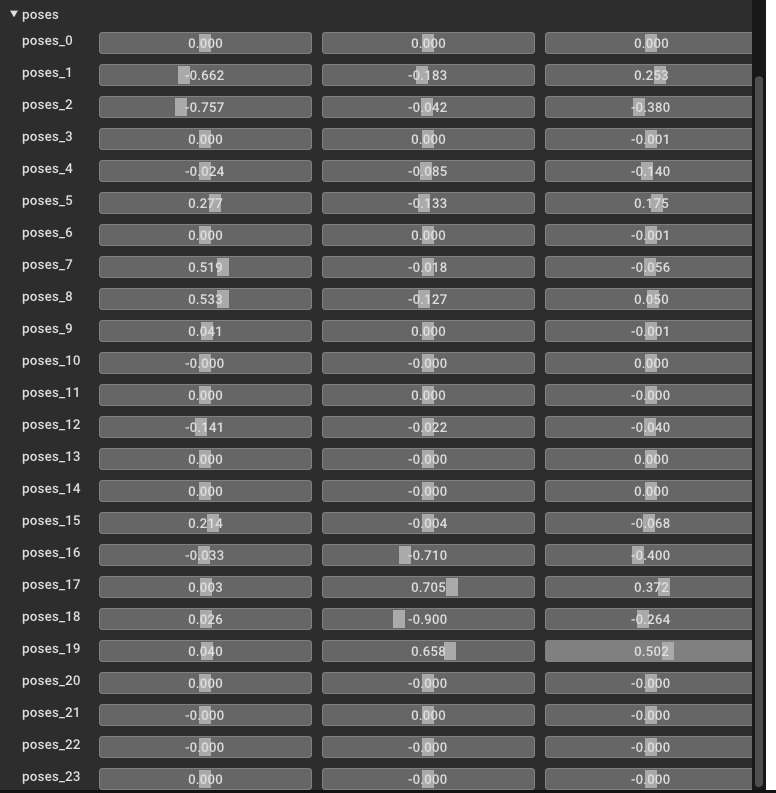
插值10/10帧

 微信
微信- 支付宝

