
基于3r的slam方法总结
基于3r的slam方法总结
vggt-long

| 特点 | 值 | |
|---|---|---|
| foundation model | vggt | |
| loop detecting | 通过dino然后用一个 aggregating module进行场景识别 | |
| 主要方法 | 滑窗,滑窗区域有重叠区域,滑窗帧直接做vggt,重叠帧是一个密集匹配,直接做SIM(3)拼接 | |
| 是否提取特征并匹配 | none | |
Hier-SLAM++
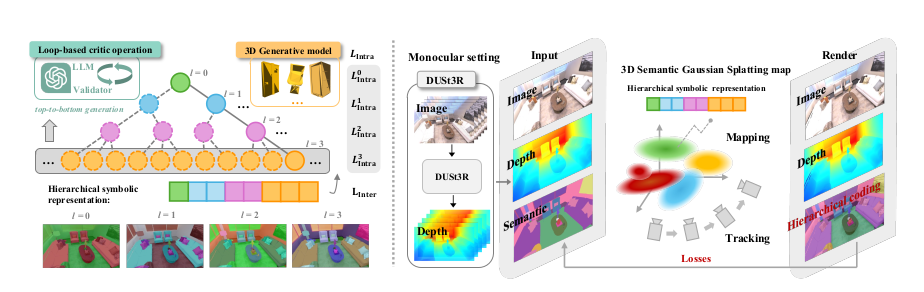
| 特点 | 值 | |
|---|---|---|
| foundation model | dust3r | |
| loop detecting | none | |
| 主要方法 | 两帧输入到dust3r可以获得初始的pose和pointmap,然后他不做匹配,而是用之前3dgs的方法,在渲染过程中使用最小化渲染损失进行几何矫正优化SE3参数 | |
| 额外的特点 | 用大语言模型+ 3D 生成模型得到生成层级语义树结构。根到叶路径代表不同语义类别,层级压缩后可用更少参数表达更多类别 | |
MASt3R-SLAM
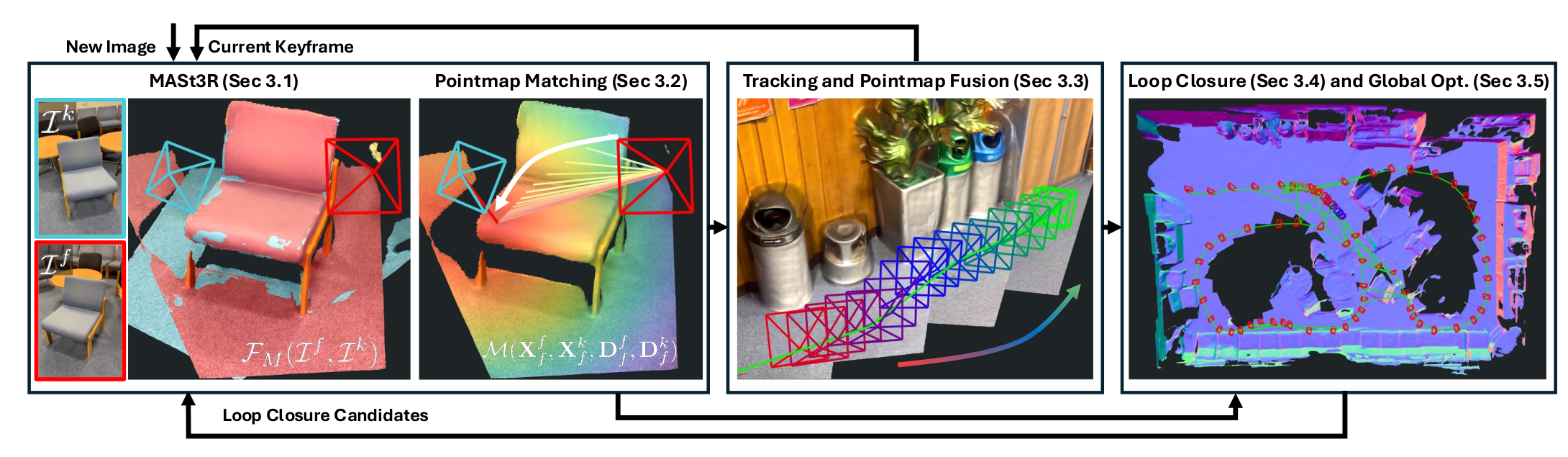
| 特点 | 值 | |
|---|---|---|
| foundation model | MASt3r | |
| loop detecting | 借鉴 MASt3R-SfM 中的聚合选择性匹配核 ASMK进行图像检索,来检测回环。 | |
| 主要方法 | 两帧输入到Masr3r可以获得特征图,置信度图和pointmap,但是他不用Dust3r自带的pose估计,而是做一个两个帧光线误差最小化来获得SIM3的pose,然后做一个重叠的两个帧输入如0和1输入,1和2输入,2和3输入,不断获得位姿变化拼接。 | |
MegaSaM: Accurate, Fast, and Robust Structure and Motion from Casual Dynamic Videos
| 特点 | 值 | |
|---|---|---|
| foundation model | DepthAnythingV2 | |
| loop detecting | ||
| 主要方法 | 基于DROID-SLAM | |
| 特点 | 让普通随手拍摄的动态视频(包含运动物体、遮挡、非刚性场景等)也能得到准确、快速、鲁棒的三维重建。输出相机位姿、焦距,以及稠密的视频深度图 | |
Outdoor Monocular SLAM with Global Scale-Consistent 3D Gaussian
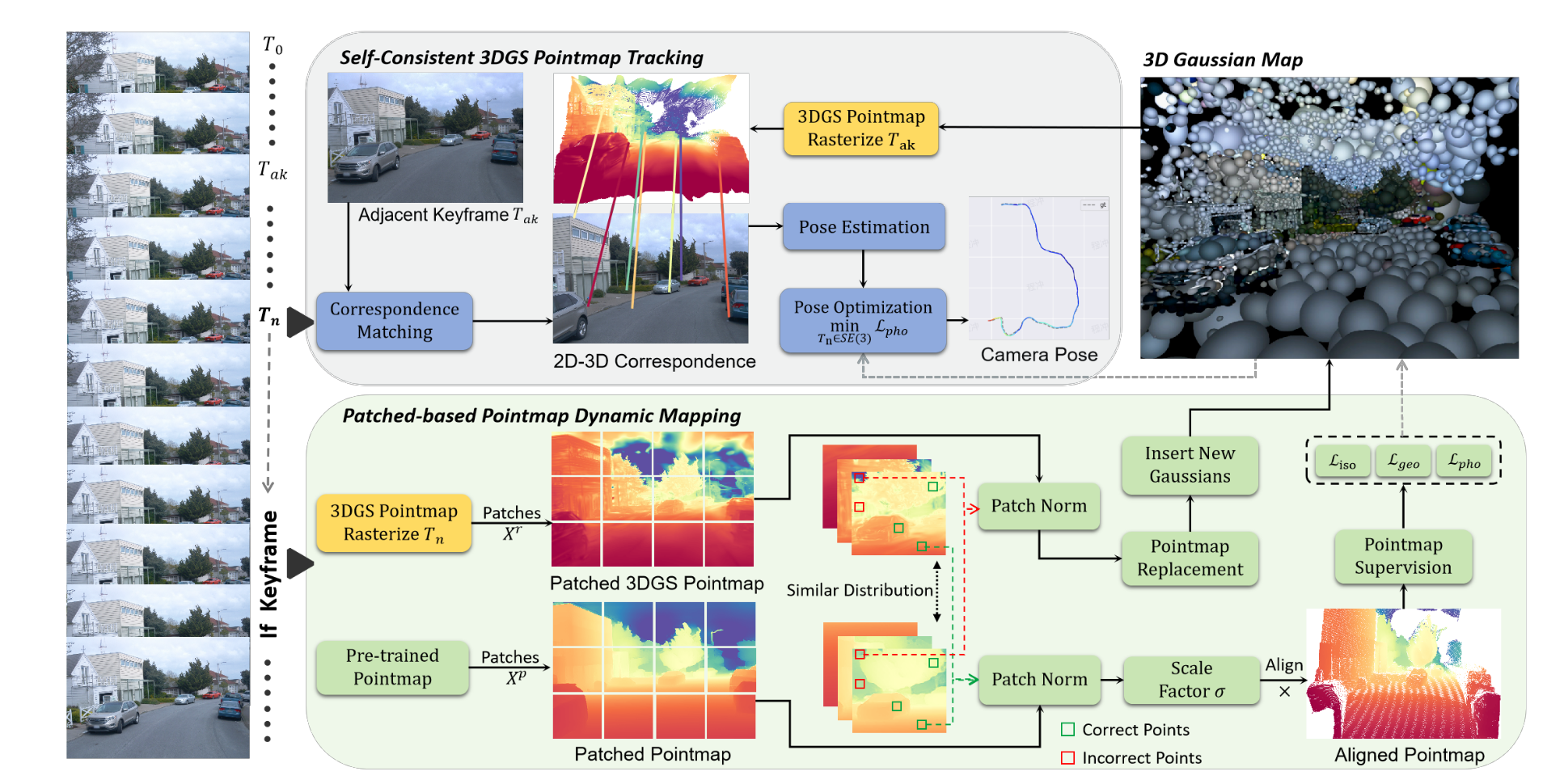
| 特点 | 值 | |
|---|---|---|
| foundation model | Mast3r | |
| loop detecting | 首先第一帧是直接获得3dgs的点图,然后下一帧的rgb和当前3dgs点图做2d-3d的匹配,通过最小化光度损失获得下一帧的位姿,如果作为关键帧,关键帧通过Mast3r获得点图和3dgs的点图,然后根据两个点图一致的地方计算Scale做align,然后对齐到全局3dgs中 | |
| 主要方法 | ||
| 特点 | 在没有深度传感器的情况下构建全局尺度一致的 3D Gaussians pointmap | |
Pseudo Depth Meets Gaussian: A Feed-forward RGB SLAM Baseline
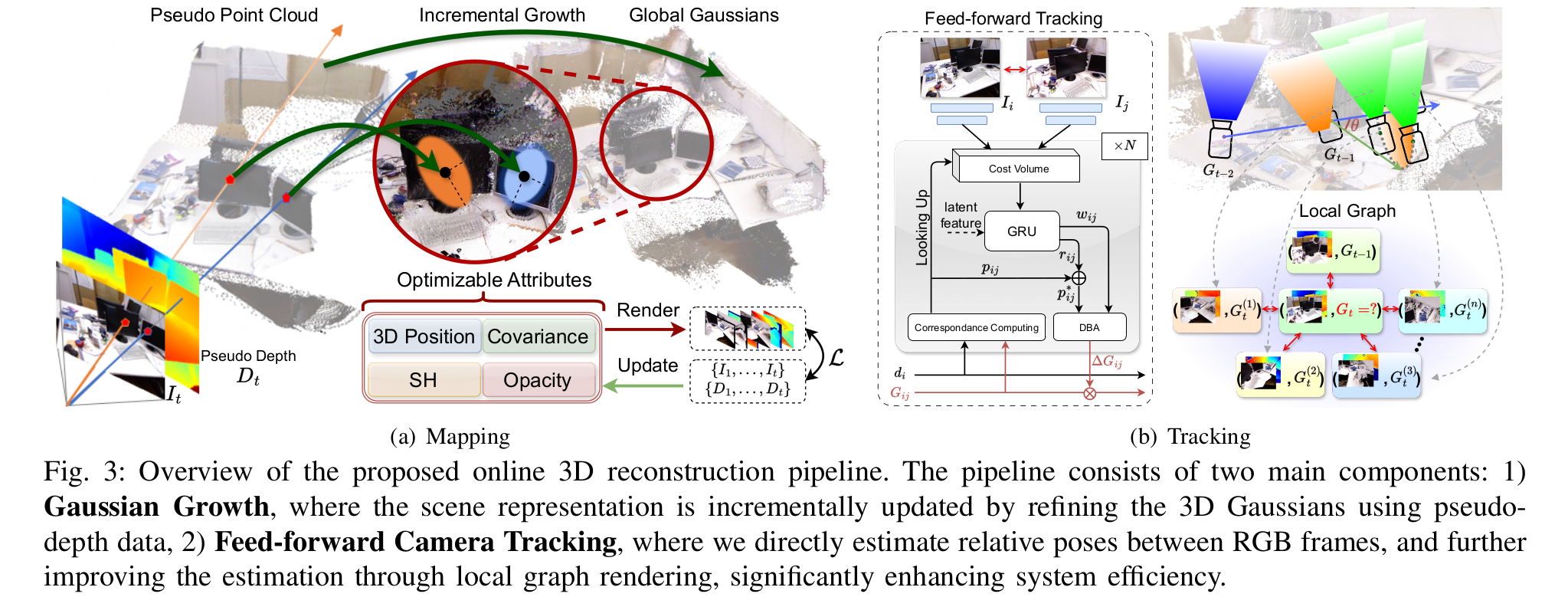
| 特点 | 值 | |
|---|---|---|
| foundation model | Mast3r | |
| loop detecting | 首先第一帧是直接获得3dgs的点图,然后下一帧的rgb和当前3dgs点图做2d-3d的匹配,通过最小化光度损失获得下一帧的位姿,如果作为关键帧,关键帧通过Mast3r获得点图和3dgs的点图,然后根据两个点图一致的地方计算Scale做align,然后对齐到全局3dgs中 | |
| 主要方法 | ||
| 特点 | 在没有深度传感器的情况下构建全局尺度一致的 3D Gaussians pointmap | |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 This is a 部落格 of outbreak_sen!
 微信
微信- 支付宝

