
李沐-TransFormer基础
李沐-TransFormer基础
Attention Is All You Need
谷歌在2017年的论文
同等贡献很多
代码在tensor2tensor
摘要
- 序列转换模型都是基于复杂的循环神经网络或卷积神经网络,且都包含一个encoder和一个decoder。表现最好的模型还通过attention机制把encoder和decoder联接起来。
- 提出了一个新的、简单的网络架构,Transformer. 它只基于单独的attention机制,完全避免使用循环和卷积。在两个翻译任务上表明,我们的模型在质量上更好,同时具有更高的并行性,且训练所需要的时间更少。
- RNN,LSTM,GRU在序列建模和转换任务上取得SOTA结果,递归模型通常沿输入和输出序列的符号位置进行因子计算。在计算时将位置与步骤对齐,它们生成一系列隐藏状态和当前的输入生成。这种内部的固有顺阻碍了训练样本的并行化,
- attention已经成功应用在encoder和decoder中了。self-attention,有时也叫做内部注意力,是一种注意力机制,它将一个序列的不同位置联系起来,以计算序列的表示。self-attention 已经成功的运用到了很多任务上,包括阅读理解、抽象摘要、语篇蕴涵和学习任务无关的句子表征等。
- 编码时候需要整个放进去,解码时候只能一个一个输出
创新点
- 使用注意力机制
- 提出了缩放的点积注意力机制
- 多头注意力机制
- Positional Encoding(位置编码)
- Embeddings and Softmax (词嵌入和 softmax)
- 前馈网络FeedForward
- Masked Muilt-Head attention
创新点讲解
- embedding
- 位置编码
layernorm
Jimmy Ba 等人在 2016 年提出,旨在解决 Batch Normalization(BN) 对小批量数据(Batch Size)依赖的问题。LN 对每个样本独立归一化,计算其在所有通道(或特征维度)上的均值和方差,不依赖 Batch 内其他样本。
- 其实就是一个batch里有多个图,batchnorm就是所有图,每个通道做norm
- layernorm就是每个图,但是所有通道分别自己做norm,适合动态数据(如变长序列)。注意不再是每个通道分别做norm,而是现在所有通道公平norm。
- BN 是对每个通道
c,跨所有样本N和空间位置(H,W)计算统计量。 - LN 是对每个样本
n,跨所有通道C和空间位置(H,W)计算统计量。
Masked Muilt-Head attention
解码器应该只看到前面的输入,不能看到之后的输入
Attention
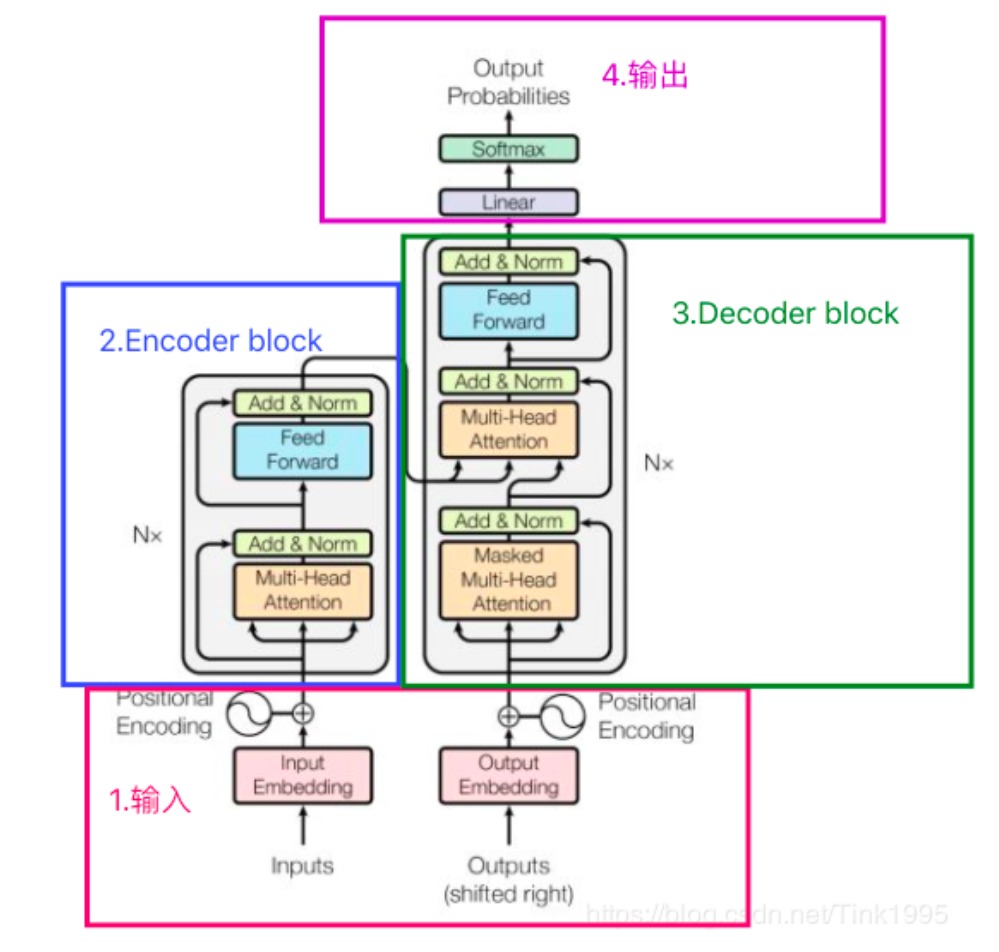
模型架构
- Encoder:encoder由**N(N=6)**个完全相同的layer堆叠而成.每层有两个子层。第一层是multi-head self-attention机制,第二层是一个简单的、位置全连接的前馈神经网络Simple position-wise fully connected feed-forward network。我们在两个子层的每一层后采用残差连接,接着进行layer normalization。也就是说,每个子层的输出是LayerNorm(x + Sublayer(x)) 其中 Sublayer(x) 是由子层本身实现的函数。为了方便这些残差连接,模型中的所有子层以及embedding层产生的输出维度都为dmodel=512。nn.LayerNorm
- Decoder: decoder也由N(N=6)个完全相同的layer堆叠而成.除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该子层对编码器encoder堆栈的输出执行multi-head attention操作,这不就是交叉注意力机制,与encoder相似,我们在每个子层的后面使用了残差连接,之后采用了layer normalization。我们也修改了decoder stack中的 self-attention 子层,以防止当前位置信息中被添加进后续的位置信息。
自注意力机制
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 This is a 部落格 of outbreak_sen!
 微信
微信- 支付宝

